Rocksdb 利用recycle_log_file_num 重用wal-log文件
recycle_log_file_num 复用wal文件信息, 优化wal文件的空间分配,减少pagecache中文件元信息的更新开销。
为同事提供了一组rocksdb写优化参数之后有一个疑惑的现象被问到,发现之前的一些代码细节有遗忘情况,同时也发现了这个参数的一些小优化,这里做个总结。
在参数:
opts.recycle_log_file_num = 10;
opts.max_write_buffer_number = 16;
opts.write_buffer_size = 128 << 20;
大压力写下 出现了多个.log文件同时存在的现象,想要看看为什么会有这个现象。
在描述这个现象产生的原因之前我们先看看Rocksdb的wal创建以及清理过程,其中recycle_log_file_num是如何reuse log的
Rocksdb的WAL创建
如果不设置disable_memtable=true,不设置enable_pipelined_write=1,不disableWAL=1的话,基本的写入调用栈如下:
JoinBatchGroup的逻辑这里暂不提及,从大体的写入过程中各个文件的创建过程如下:
DBImpl::PreprocessWriteDBImpl::SwitchWALDBImpl::SwitchMemtableDBImpl::CreateWAL // 创建wal文件
在CreateWal文件的时候,Rocksdb会为这个wal创建一个PosixEnv下的文件句柄,以及文件名,并创建一个文件writer,用来后续的数据写入。
如下代码:
// 其中recycle_log_number 为当前想要复用的wal log文件名
// new_log 为需要在该函数中创建的writer,最后传出来
// log_file_num 是创建的新的文件名,如果可回收的文件为0,则直接用新的就可以了。
IOStatus DBImpl::CreateWAL(uint64_t log_file_num, uint64_t recycle_log_number,size_t preallocate_block_size,log::Writer** new_log) { ......// 根据文件num,创建新的文件名std::string log_fname =LogFileName(immutable_db_options_.wal_dir, log_file_num);// 如果有可回收的numer,则reuseif (recycle_log_number) { ROCKS_LOG_INFO(immutable_db_options_.info_log,"reusing log %" PRIu64 " from recycle list
",recycle_log_number);std::string old_log_fname =LogFileName(immutable_db_options_.wal_dir, recycle_log_number);TEST_SYNC_POINT("DBImpl::CreateWAL:BeforeReuseWritableFile1");TEST_SYNC_POINT("DBImpl::CreateWAL:BeforeReuseWritableFile2");io_s = fs_->ReuseWritableFile(log_fname, old_log_fname, opt_file_options,&lfile, /*dbg=*/nullptr);} else { io_s = NewWritableFile(fs_.get(), log_fname, &lfile, opt_file_options);}if (io_s.ok()) { ......// 创建一个file writerstd::unique_ptr<WritableFileWriter> file_writer(new WritableFileWriter(std::move(lfile), log_fname, opt_file_options,immutable_db_options_.clock, io_tracer_, nullptr /* stats */, listeners,nullptr, tmp_set.Contains(FileType::kWalFile)));*new_log = new log::Writer(std::move(file_writer), log_file_num,immutable_db_options_.recycle_log_file_num > 0,immutable_db_options_.manual_wal_flush);}return io_s;
}
其中ReuseWritableFile函数和NewWritableFile函数内部分别打开的是一个存在和不存在的文件,如果我们能够reuse log文件名,则在ReuseWritableFile函数中通过open系统调用打开已存在文件的时候不需要创建新的dentry和inode,且不需要将这一些元数据更新到各自dcache/inode-cache中的相应hash表中,所以重用文件名这里的优化就体现在内核对文件的一些操作逻辑上。
关于open系统调用的内核逻辑,可以参考从unlink系统调用来看操作系统文件系统原理。
CreateWAL这个函数仅仅是用到了recycle_log_number,什么时候给recycle_log_number 赋值呢,可以由下向上递推。
recycle_log_number 如何复用log
向上递推 ,可以看到CreateWAL函数是在SwitchMemtable中被调用,recycle_log_number数值是从一个log_recycle_files_的deque中取出来的。
Status DBImpl::SwitchMemtable(ColumnFamilyData* cfd, WriteContext* context) { ......// 从log_recycle_files_ 的头端取出一个元素作为当前可回收的log numberuint64_t recycle_log_number = 0;if (creating_new_log && immutable_db_options_.recycle_log_file_num &&!log_recycle_files_.empty()) { recycle_log_number = log_recycle_files_.front();}......if (creating_new_log) { // TODO: Write buffer size passed in should be max of all CF's instead// of mutable_cf_options.write_buffer_size.io_s = CreateWAL(new_log_number, recycle_log_number, preallocate_block_size,&new_log);if (s.ok()) { s = io_s;}}
而log_recycle_files_ 这个deque则是在从活跃log deque alive_log_files_ 中取的。
在FindOnsoleteFiles函数中需要清理一些过期文件(log, sst, blob等),针对一些过期的log进行回收,并添加到log_recycle_files_ 双端队列中。
其中recycle_log_file_num 表示能够回收的log个数
if (!alive_log_files_.empty() && !logs_.empty()) { uint64_t min_log_number = job_context->log_number;size_t num_alive_log_files = alive_log_files_.size();// find newly obsoleted log files// 从活跃log中取出没有接受写入数据的log,将这一部分log进行重用// min_log_number表示当前这个log 还在被持续更新。while (alive_log_files_.begin()->number < min_log_number) { auto& earliest = *alive_log_files_.begin();if (immutable_db_options_.recycle_log_file_num >log_recycle_files_.size()) { ROCKS_LOG_INFO(immutable_db_options_.info_log,"adding log %" PRIu64 " to recycle list
",earliest.number);log_recycle_files_.push_back(earliest.number);} else { job_context->log_delete_files.push_back(earliest.number);关于alive_log_files_这个变量的元素更新是在 打开db 和 SwitchMemtable 过程中进行更新的,这两个部分会创建wal
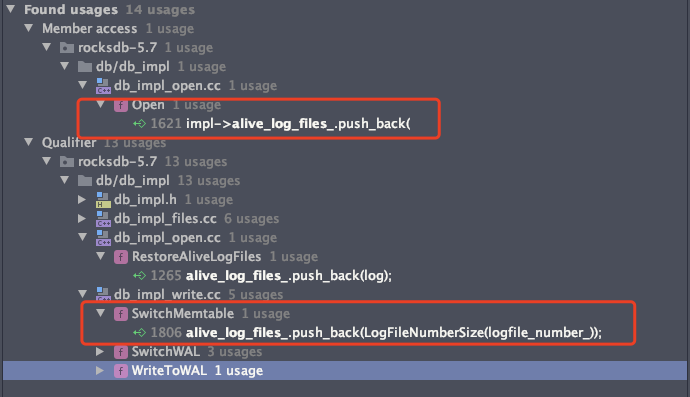
在FindOnsoleteFiles函数中,构造好的job_context传出即可。
清理WAL的调用栈如下(如果当前log被reuse,那就不会被清理了)
DBImpl::MaybeScheduleFlushOrCompaction // 调度compaction/flushDBImpl::BGWorkFlush // 从线程池调度flushDBImpl::BackgroundCallFlush DBImpl::FindObsoleteFiles // 构造好我们的job_context,其中包括需要清理的sst/blob/logDBImpl::PurgeObsoleteFiles // 执行清理
在清理函数中PurgeObsoleteFiles会决定是否需要keep log
bool keep = true;switch (type) { case kWalFile:keep = ((number >= state.log_number) ||(number == state.prev_log_number) ||(log_recycle_files_set.find(number) !=log_recycle_files_set.end()));break;
如果发现log在log_recycle_files_set 我们之前回收的log列表中,则需要keep,也就不会执行后续的log文件删除了。
总结
到此,我们就知道参数opts.recycle_log_file_num的完整作用了,回到开头提到的现象,在开头的配置下大并发写rocksdb 会发现部分log文件可能存在的时间较长,且同时存在多个log 数目。
对于第一个问题 log存在的时间较长,即是由recycle_log_file_num 参数控制,它会不断得复用一些过期(不接受写入)的log,并且这一些log不会被回收。这个参数能够提升log文件的复用,减少对文件元数据的操作,加速SwitchMemtable的过程。
对于第二个问题 log存在多个,则是由于max_write_buffer_number参数的问题,它允许同时存在多个memtable,如果写入量较大,则imm 排队flush,则这个过程中的imm 对应的log文件是不会清理的,而recycle_log_file_num 则会回收一些log_num,且让这一些log不会被清理,所以会同时出先多个log_num。
需要注意的是recycle_log_file_num 这个参数回收的log不会被清理。
更多相关:
-
[Mar 31 02:39:34.185] Server {0x2b1d85563700} NOTE:
-
今天的Log信息有的能打有的不能打,甚是奇怪,高了半天明白了,常见的几个问题就不说了,说我这个奇怪的。看下面的内容,那个能打印呢? 1 2 3 4 5 Log.v("交易返回码:log", " "); Log.v("re:log", ""); Log.e("交易返回码:log", ""); Log.e("re:log", "...
-
问题描述: 已知一个使用字符串表示的非负整数num,将num中的k个数字移 除,求移除k个数字后,可以获得的最小的可能的新数字。 例如:num = “1432219” , k = 3 在去掉3个数字后得到的很多很多可能里,如1432、4322、2219、1219 、1229…; 去掉数字4、3、2得到的1219最小! 贪心规律:...
-
一个谜团 如果你用过类似guava这种“伪函数式编程”风格的library的话,那下面这种风格的代码对你来说应该不陌生: 1 2 3 4 5 6 7 8 9 public void tryUsingGuava() { final int expectedLength = 4; Iterables.filter(...
-
http://en.wikipedia.org/wiki/Condition_number...