哈希表的分类,创建,查找 以及相关问题解决
总体的hash学习导图如下:
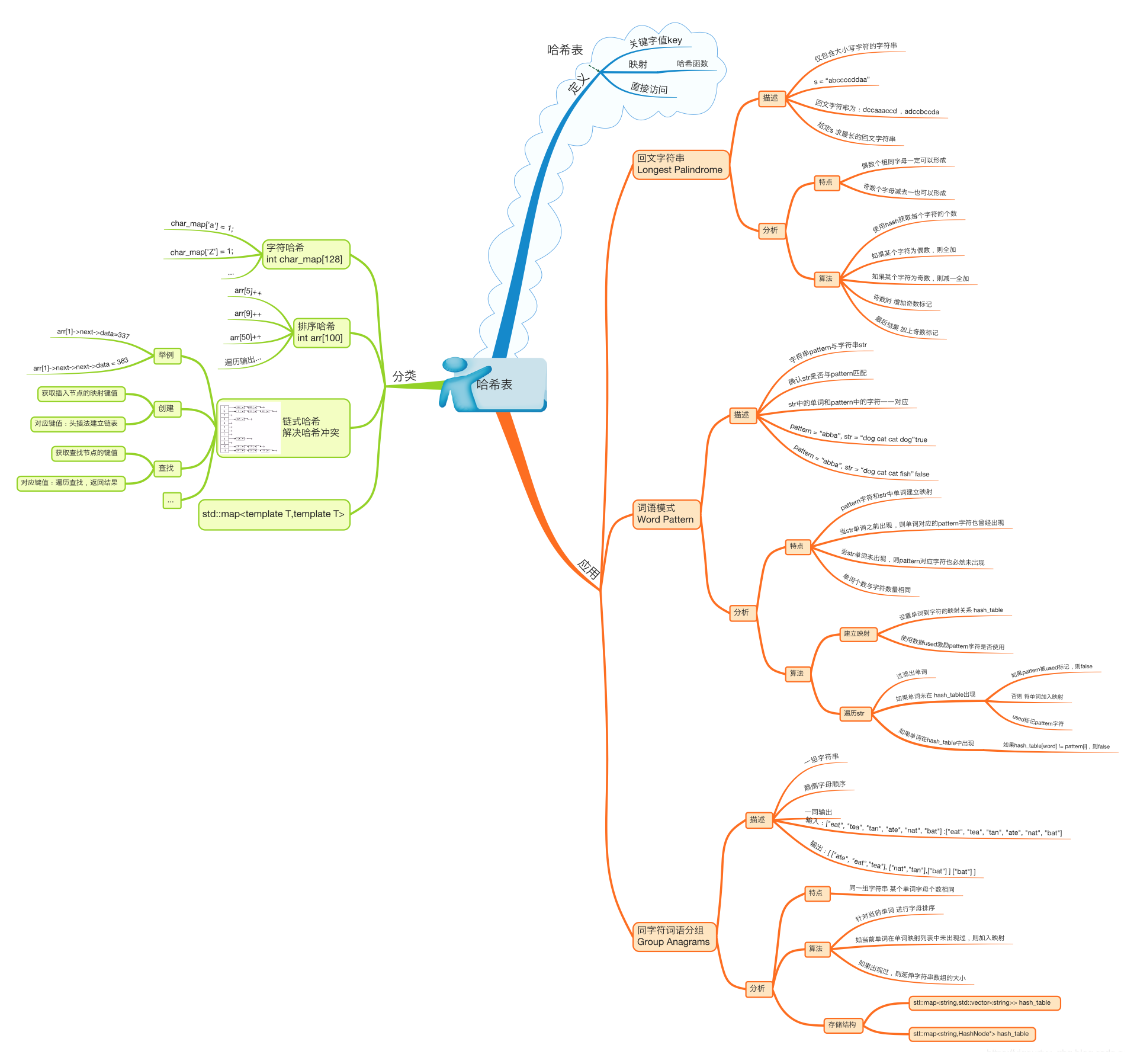
文章目录
- 定义
- 分类
- 字符hash
- 排序hash
- 链式hash(解决hash冲突)
- 创建链式hash
- 查找指定数值
- STL map(hash)
- 哈希分类 完整测试代码
- 应用(常见题目)
- 1. 回文字符串(Longest Palindrome)
- 2. 词语模式(Word Pattern)
- 3. 同字符词语分组(Group Anagrams)
定义
- 需要拥有关键字 key
- 维护一个key和value的映射关系,哈希函数
- 最终的hash表拥有直接通过key访问值的能力
分类
字符hash
/*count letters*/
void hash_char() { int char_map[128] = { 0};string s = "aabbbcddeh";for (int i = 0;i < s.length(); ++i) { char_map[s[i]] ++;}for (int i = 0;i < 128; ++i) { if (char_map[i] > 0) { printf("[%c] [%d]
",i,char_map[i]);}}
}
排序hash
void hash_sort() { int arr[] = { 1,100,2,6,998,532,40};int hash_arr[999] = { 0};for (int i = 0;i < 7; ++i) { hash_arr[arr[i]] ++;}for (int i = 0;i < 999; i++) { if (hash_arr[i] > 0) { cout << i << endl;}}
}
链式hash(解决hash冲突)
创建链式hash
struct HashNode
{ int data;struct HashNode *next;HashNode(int x):data(x),next(NULL){ }
};int get_key(int key, int tabel_len) { return key % tabel_len;
}void insert_hash(HashNode *hash_table[], HashNode *node, int tabel_len) { int key = get_key(node -> data, tabel_len);node ->next = hash_table[key];hash_table[key] = node ;
}
查找指定数值
int get_key(int key, int tabel_len) { return key % tabel_len;
}bool search(HashNode *hash_table[], int value, int tabel_len) { int key = get_key(value,tabel_len);HashNode *head = hash_table[key];while(head) { if (head -> data == value) { return true;}head = head -> next;}return false;
}
STL map(hash)
void stl_hash() { std::map<string, int> map;string a[3] = { "aaa","ssss","ddd"};map[a[0]] = 1;map[a[1]] = 100;map[a[2]] = 301;cout << "stl hash_table is " << endl;for (std::map<string, int>::iterator it = map.begin(); it != map.end(); it ++) { cout << "[" << it -> first.c_str() << "] :" << it -> second << endl; }if (map.find(a[1]) != map.end()) { cout << "sss is in the stl map " << map[a[1]]<< endl;}
}
哈希分类 完整测试代码
#include 输出如下:
hash_char
[a] [2]
[b] [3]
[c] [1]
[d] [2]
[e] [1]
[h] [1]
hash_sort
1
2
6
40
100
532
998
hash_table
[0]
[1] -> 1-> 100-> 1
[2] -> 2
[3]
[4] -> 532
[5]
[6] -> 6
[7] -> 40
[8] -> 998
[9]
[10] 0 is not int the hash_table
1 is in the hash_table
2 is in the hash_table
3 is not int the hash_table
4 is not int the hash_table
5 is not int the hash_table
6 is in the hash_table
7 is not int the hash_table
8 is not int the hash_table
9 is not int the hash_table
stl hash_table is
[aaa] :1
[ddd] :301
[ssss] :100
sss is in the stl map 100
应用(常见题目)
1. 回文字符串(Longest Palindrome)
问题如下:
已知一个只包括大小写字符的 字符串,求用该字符串中的字符可以生 成的最长回文字符串长度。
例如 s = “abccccddaa”,可生成的 最长回文 字符串长度为 9,如 dccaaaccd、 adccbccda、 acdcacdca等,都是正确的。
代码实现如下:
#include 输出如下:
abccccddaabb
11
2. 词语模式(Word Pattern)
问题描述如下:
已知字符串pattern与字符串str,确认str是否与pattern匹配。
str与pattern匹配代表字符 串str中的单词与pattern中的字符一一对应。(其中pattern中只包含小写字符,str中
的单词只包含小写字符,使用空格分隔。) 例如,
pattern = “abba”, str = “dog cat cat dog” 匹配.
pattern = “abba”, str = “dog cat cat fish” 不匹配.
pattern = “aaaa”, str = "dog cat cat dog"不匹配.
pattern = “abba”, str = "dog dog dog dog"不匹配.
实现如下:
#include 输出如下:
abba
dog cat cat do
0abba
dog cat cat dog
1
3. 同字符词语分组(Group Anagrams)
问题描述:
已知一组字符串,将所有anagram(由颠倒字母顺序而构成的 字)放到一起输出。
例如:[“eat”, “tea”, “tan”, “ate”, “nat”, “bat”] :[“eat”, “tea”, “tan”, “ate”, “nat”, “bat”]
返回:[ [“ate”, “eat”,“tea”], [“nat”,“tan”], :[ [“ate”, “eat”,“tea”], [“nat”,“tan”],[“bat”] ]
实现如下:
#include 的存储映射*/
std::vector<std::vector<string>> get_group_anagrams(std::vector<string> &str) { std::map<string, std::vector<string> > hash_table;string tmp;std::vector<std::vector<string>> result;for (int i = 0;i < str.size(); ++i){ tmp = str[i];sort(tmp.begin(), tmp.end());if (hash_table.find(tmp) != hash_table.end()) { hash_table[tmp].push_back(str[i]);} else { std::vector<string> item;item.push_back(str[i]);hash_table[tmp] = item;}}std::map<string, std::vector<string> >::iterator it = hash_table.begin();for (;it != hash_table.end(); ++it) { result.push_back(it->second);}return result;
}int main(int argc, char const *argv[])
{ /* code */std::vector<string> str;for (int i = 0;i < 6; ++i) { string tmp;cin >> tmp;str.push_back(tmp);}std::vector<std::vector<string> > result = get_group_anagrams(str);for (int i = 0;i < result.size(); ++i) { for (int j = 0;j < result[i].size(); ++j) { cout << "[" << result[i][j] << " ] ";}cout << endl;}return 0;
}
输出如下:
ate eat tea tan nat bat
[bat ]
[ate ] [eat ] [tea ]
[tan ] [nat ]
更多相关:
-
HMAC: Hash-based Message Authentication Code,即基于Hash的消息鉴别码 在各大开放平台大行其道的互联网开发潮流中,调用各平台的API接口过程中,无一例外都会用到计算签名值(sig值)。而在各种计算签名的方法中,经常被采用的就是HMAC-SHA1,现对HMAC-SHA1做一个简单的介绍:...
-
今天介绍两种基础的字符串匹配算法,当然核心还是熟悉一下Go的语法,巩固一下基础知识 BF(Brute Force)RK(Rabin Karp) 源字符串:src, 目标字符串:dest; 确认dest是否是src 的一部分。 BF算法很简单暴力,维护两个下标i,j,i控制src的遍历顺序, j控制dest遍历顺序。 记录一下i的...
-
Apache POI是一个开源的利用Java读写Excel,WORD等微软OLE2组件文档的项目。 我的需求是对Excel的数据进行导入或将数据以Excel的形式导出。先上简单的测试代码:package com.xing.studyTest.poi;import java.io.FileInputSt...
-
要取得[a,b)的随机整数,使用(rand() % (b-a))+ a; 要取得[a,b]的随机整数,使用(rand() % (b-a+1))+ a; 要取得(a,b]的随机整数,使用(rand() % (b-a))+ a + 1; 通用公式:a + rand() % n;其中的a是起始值,n是整数的范围。 要取得a到b之间的...
-
利用本征图像分解(Intrinsic Image Decomposition)算法,将图像分解为shading(illumination) image 和 reflectance(albedo) image,计算图像的reflectance image。 Reflectance Image 是指在变化的光照条件下能够维持不变的图像部分...
-
题目:面试题39. 数组中出现次数超过一半的数字 数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。 你可以假设数组是非空的,并且给定的数组总是存在多数元素。 示例 1: 输入: [1, 2, 3, 2, 2, 2, 5, 4, 2] 输出: 2 限制: 1 <= 数组长度 <= 50000 解题: cl...
-
题目:二叉搜索树的后序遍历序列 输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历结果。如果是则返回 true,否则返回 false。假设输入的数组的任意两个数字都互不相同。 参考以下这颗二叉搜索树: 5 / 2 6 / 1 3示例 1: 输入: [1,6,3,2,5] 输出...
-
Spec: TS36.211 - Table 5.7.1-2...
-
阿里云介绍: 1. 下载安装包。作为阿里主要的数据传输工具Datax,阿里已经完全开源到github上面了。下载地址(https://github.com/alibaba/DataX)。 2. 安装环境: JDK(1.6以上,推荐1.6)Python(推荐Python2.6.X)Apache Maven 3.x (Compile D...
-
xmlns xml namespaces 参考 http://www.w3school.com.cn/tags/tag_prop_xmlns.asp http://www.w3school.com.cn/xml/xml_namespaces.asp
这是一行 1.创建数据库:create database database-name 2.删除数据库:delete database database-name 3.选择:select * from table where ... 4.插入:insert into table(field1,field2) values(value1,value...