Rocksdb 的 BlobDB key-value 分离存储插件
前言
还是回到传统的 LSM-tree 中,我们key-value 写入时以append形态存放到一个data-block中,多个data-block+metablock 之类的数据组织成一个sst。当我们读数据以及compaction的时候读到key 之后则很方便得读取到对应的value,一次I/O能够将key-value完全从磁盘读上来。但这种存储方式在大value场景下引入了非常多的读写放大,读写性能都会非常差。
所以Wisckey提出了key-value分离,且业界也有了一些不错的实现,包括Tikv/Titan, DGraph/badger等应用在工业界的实现案例。
但是,这一些对于使用rocksdb作为存储生态的用户来说还是不够方便,titan虽然是以rocksdb的插件形态存在的,但是很多rocksdb支持的功能还不够完善(checkpoint/backup, Trasaction 等需求量比较大的场景),所以虽然基本功能实现了,但还是没有办法得到更加广泛的应用。
这个时候rocksdb 社区的BlobDB经过长久的开发和完善,在旧版本的基础上实现了一个全新的BlobDB版本。
支持的特性
文章标题说的是分离存储插件,其实本身并不是插件的形态了, 这个新版本已经完全融入到rocksdb之中,支持的特性:
- rocksdb的基本操作接口不需要任何变动,
DB::Put,DB::Get等仍然继续使用(Merge不支持),开启k/v分离,只需要打开enable_blob_files=true以及设置min_blob_size就可以了(简直不要太方便,当然,titan没有做成这样也可能是因为这样与rocksdb代码耦合太多了, 不方便跟进社区的版本)。 - Recovery 异常重放
- 压缩
- atomic flush
- compaction filter( 支持 用户选择读取value,有一些用户使用compaction filter 只想要key的操作,这个时候不需要将value再回传了 )
- Checkpoints
- 备份
- 事务
- 文件级别的checksum
- sst-filem-manager(后续支持ingest会比较方便)
当然还有一些特性暂时不支持:
- Merge 接口写入大value (这个特性的优先级后续会比较高,主要update场景的需求量还是很大)
- EventListener
- Secondary Instance (离线读取场景)
- ingest blob file(这个场景需求也会大一些,高效的离线导入)
GC 实现
这里简单描述一下BlobDB的key-value分离存储实现。
- 分离场景其实比较简单,在Flush/Compaction过程中判断是否开启key/value分离, 且判读写入的value是否是超过设置的
min_blob_size,超过则通过blob_file_builder 将key-value写入到.blob文件中且对应的key+key-index则仍然存放在sst中,否则key-value都存放在sst中。 - 重点是GC的实现,当然可以通过设置
enable_blob_garbage_collection控制是否开启关闭GC。GC的调度不同于Titan的传统GC,通过EventLister 在Compaction完成之后触发,而是类似于Titan的level merge GC ,在Compaction过程中如果开启了GC,会将大value读出来,写入到新的blobfile,旧的blobfile 则会后续通过后台清理线程集中清理。
这种方式的GC实现 因为没有办法避免大value的读取,当数据量足够大的时候,compaction调度的GC引入的磁盘大量的读写导致的长尾也是无法接受的,所以社区也只能提供了可开启关闭的GC的参数来交给用户控制。
关于BlobDB中的option都是可以通过SetOptions来运行时动态变更。
性能测试
从测试结果来看,大value下的BlobDB和 TitanDB 读写性能接近,对于Rocksdb生态的用户来说BlobDB 在功能上的优势还是更受欢迎的。
测试bench mark:
测试版本:master分支
测试工具:db_bench
硬件:64core cpu + 512G mem + 3T NVMe-SSD
关闭key/value分离 随机写入性能:
numactl --cpubind=0 --membind=0 ./db_bench --benchmarks=fillrandom,stats --num=30000000 --threads=16 --writes=1000000 --db=./db-test --wal_dir=./db-test --duration=120 --key_size=16 --value_size=8192 -max_background_compactions=16 -max_background_flushes=7 -subcompactions=8 -compression_type=none -enable_pipelined_write=true
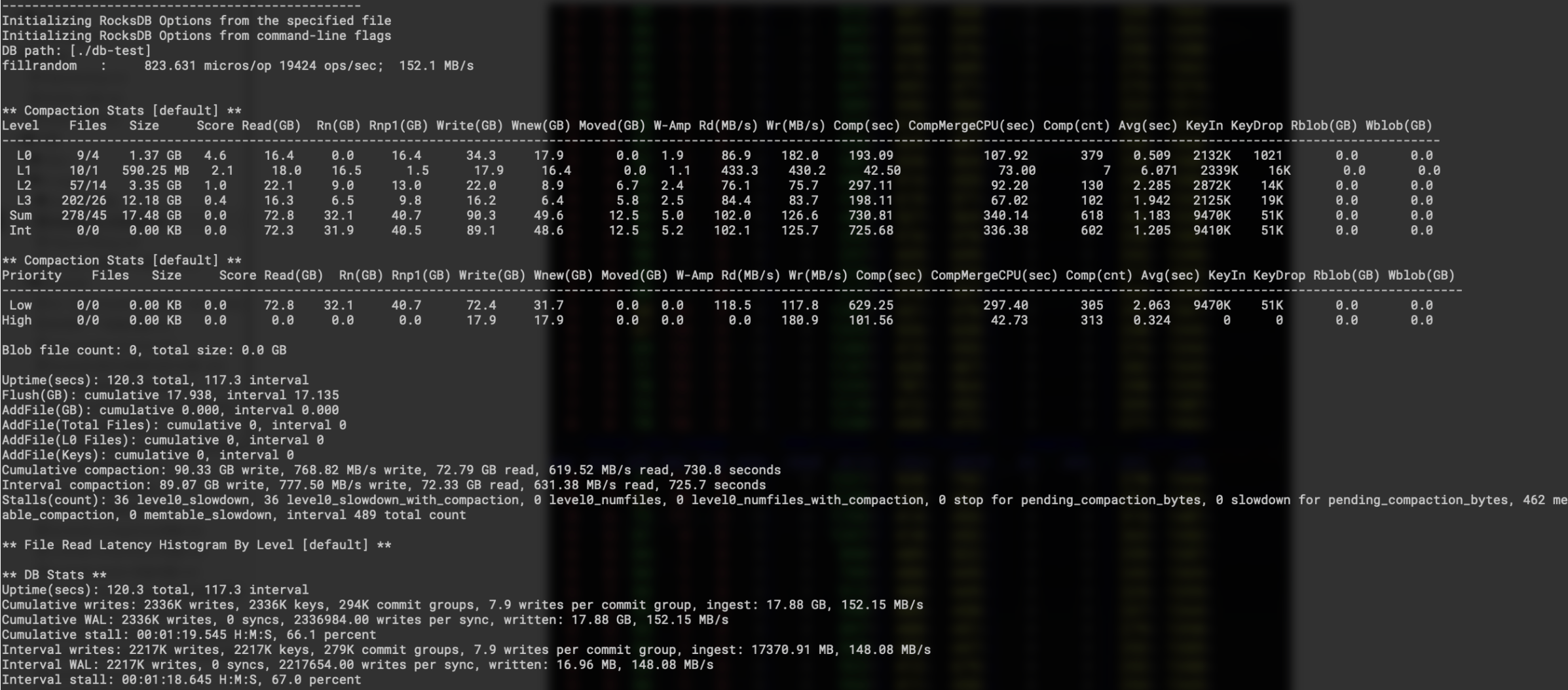
下面是随机写入场景中的磁盘I/O情况,其中磁盘I/O达到1G及以上的时间底层都是有compaction调度的,带着大value 进行compaction,整体的读写代价还是很大的,可以看到磁盘偶尔会有超过2G的带宽占用,这对于只有152M的用户写入来说实在是太大的放大了。
(关于磁盘I/O没有读流量,是因为内存比较大,db数据量比较小,大多数的数据还都会被缓存在操作系统page-cache,所以compaction过程中的读基本都会命中page-cache)
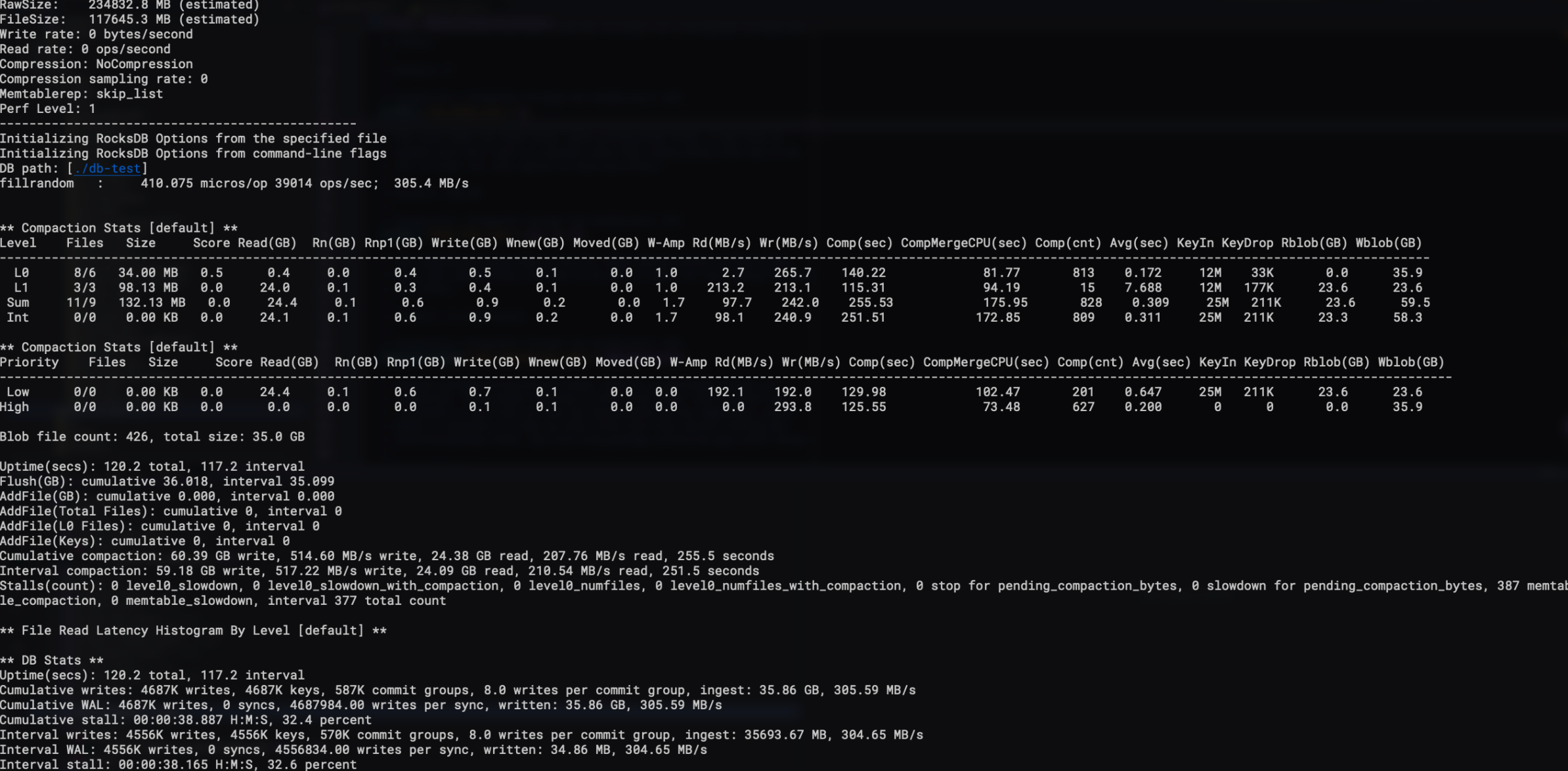
作为对比,开始测试BlobDB,使用如下benchmark
numactl --cpubind=0 --membind=0 ./db_bench --benchmarks=fillrandom,stats --num=30000000 --threads=16 --writes=1000000 --db=./db-test --wal_dir=./db-test --duration=120 --key_size=16 --value_size=8192 -max_background_compactions=16 -max_background_flushes=7 -subcompactions=8 -compression_type=none -enable_pipelined_write=true -enable_blob_files=true -min_blob_size=4096 -enable_blob_garbage_collection=true
很明显,吞吐相比于使用rocksdb来存放大value 提升了倍。
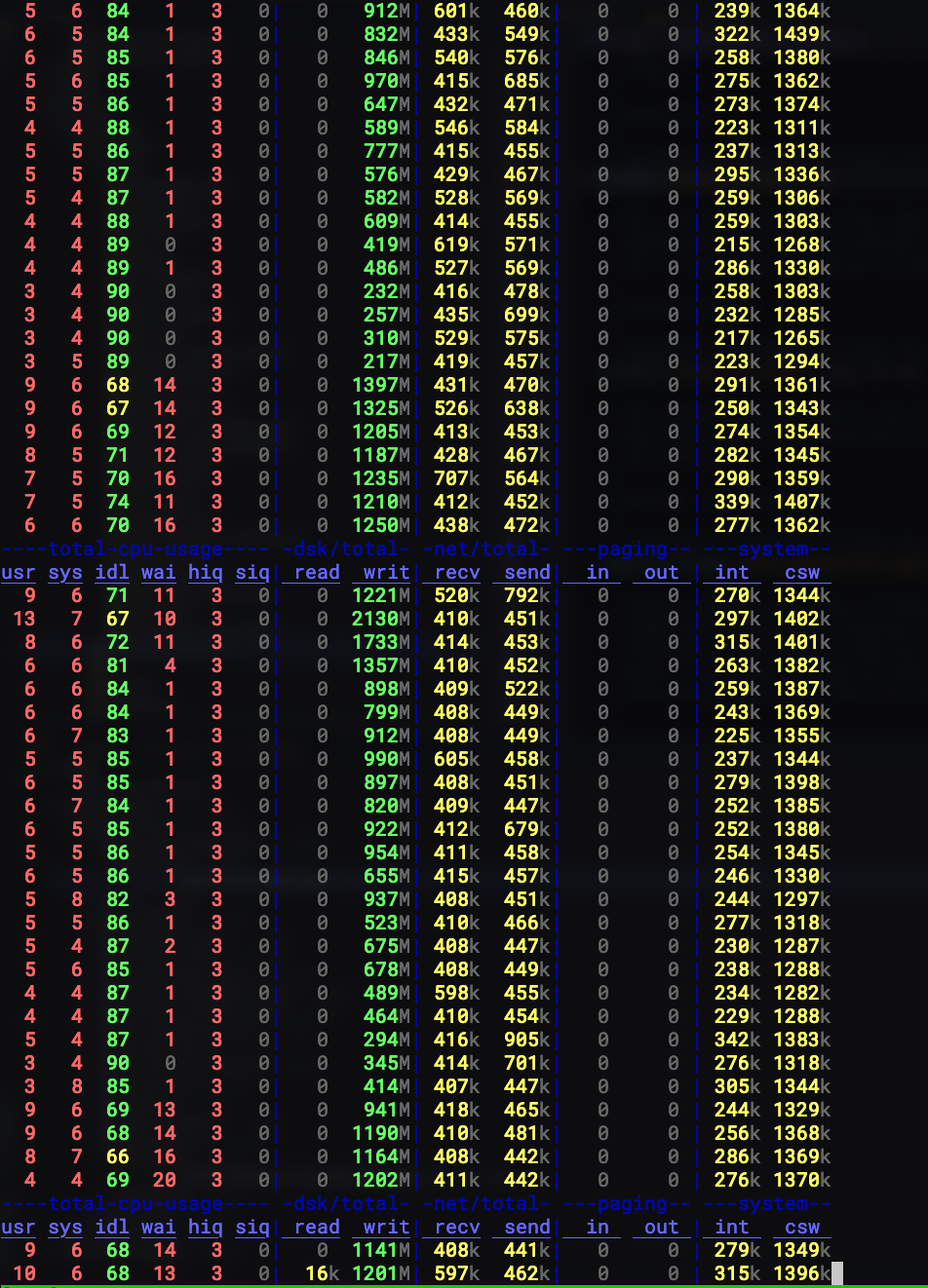
再看看磁盘I/O情况,因为我们也开启了GC,所以这个过程中会有GC的调度。从磁盘带宽来看,整体的吞吐还是比较均匀的,即使compaction + GC 一起存在,并不会有像未开启key/value分离那样的巨量I/O出现,因为不必要的key/value的value读取并不会被调度起来。
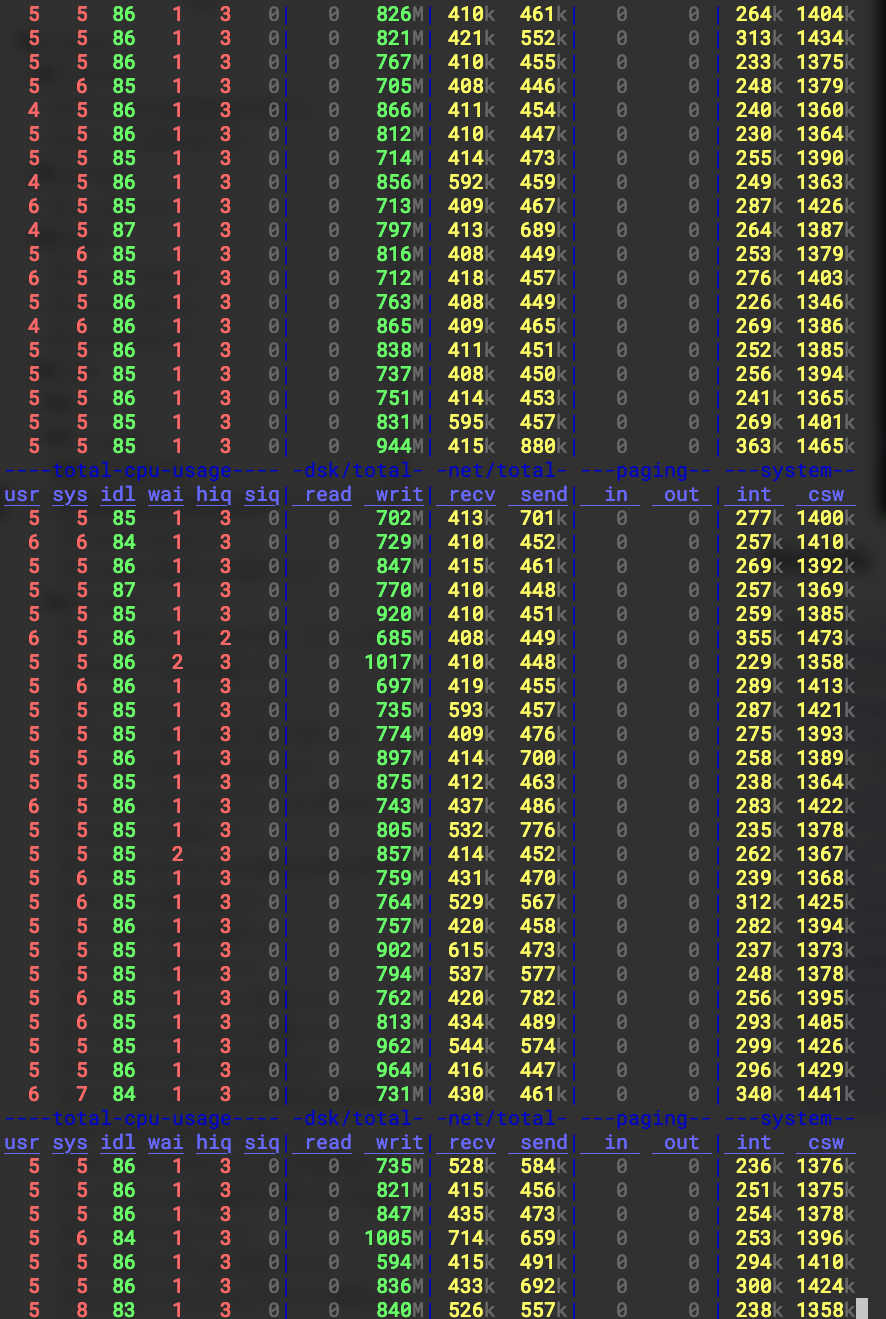
关于读性能的测试,大家可以变更benchmark为--benchmarks=readrandom,指定--use_existing_db=1和--use_existing_keys=1来保证key的100%命中就好。当然,blobdb的使用在一批热点key的集中update场景下还是需要注意GC带来的带宽占用(热点update会让GC调度的频率更高,重复写入的key多,blob文件中失效的key也会很多),如果想要保持稳定的latency,软件层的优化就是限速了,或者动态开启关闭GC(业务低峰开启GC,高峰关闭GC)。
更多相关:
-
文章目录1. 为什么要有GC2. GC的触发条件3. GC的核心逻辑1. blob file形态2. GC Prepare3. GC pick file4. GC run4. GC 引入的问题5. Titan的测试代码...
-
【BZOJ4282】慎二的随机数列 Description 间桐慎二是间桐家著名的废柴,有一天,他在学校随机了一组随机数列, 准备使用他那强大的人工智能求出其最长上升子序列,但是天有不测风云,人有旦夕祸福,柳洞一成路过时把间桐慎二的水杯打翻了…… 现在给你一个长度为 n 的整数序列,其中有一些数已经模糊不清了,现在请你任意确定这些整...
-
CrashReport系统在游戏内测当天出现了异常情况JVM僵死,通过top -p
-H 结合jstack(jstack -m -l pid)查看,发现是VM Thread线程CPU占用100%,线程ID好为18540,线程信息如下:----------------- 18540 -----------------0xb... -
翻页器
-
在src/main/resources/springmvc-servlet.xml中加入
-
本篇仅仅是一个记录 MergeOperator 的使用方式。 Rocksdb 使用MergeOperator 来代替Update 场景中的读改写操作,即用户的一个Update 操作需要调用rocksdb的 Get + Put 接口才能完成。 而这种情况下会引入一些额外的读写放大,对于支持SQL这种update 频繁的场景来说实在是不划...
-
看了很多人写的好几个去重方法,我在这里精简组合下,适用于已排序与未排序的数组。 废话不多说,上代码。
数组去重