jvm 堆外内存_NIO效率高的原理之零拷贝与直接内存映射
更多内容,欢迎关注微信公众号:全菜工程师小辉~
前言
在笔者上一篇博客,详解了NIO,并总结NIO相比BIO的效率要高的三个原因,彻底搞懂NIO效率高的原理。
这篇博客将针对第三个原因,进行更详细的讲解。
首先澄清,零拷贝与内存直接映射并不是Java中独有的概念,并且这两个技术并不是等价的。
零拷贝
零拷贝是指避免在用户态(User-space) 与内核态(Kernel-space) 之间来回拷贝数据的技术。
传统IO
传统IO读取数据并通过网络发送的流程,如下图
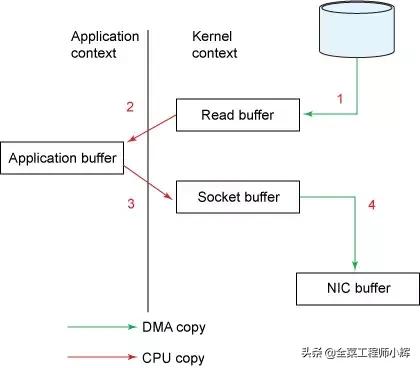
传统IO
- read()调用导致上下文从用户态切换到内核态。内核通过sys_read()(或等价的方法)从文件读取数据。DMA引擎执行第一次拷贝:从文件读取数据并存储到内核空间的缓冲区。
- 请求的数据从内核的读缓冲区拷贝到用户缓冲区,然后read()方法返回。read()方法返回导致上下文从内核态切换到用户态。现在待读取的数据已经存储在用户空间内的缓冲区。至此,完成了一次IO的读取过程。
- send()调用导致上下文从用户态切换到内核态。第三次拷贝数据从用户空间重新拷贝到内核空间缓冲区。但是,这一次,数据被写入一个不同的缓冲区,一个与目标套接字相关联的缓冲区。
- send()系统调用返回导致第四次上下文切换。当DMA引擎将数据从内核缓冲区传输到协议引擎缓冲区时,第四次拷贝是独立且异步的。
内存缓冲数据(上图中的read buffer和socket buffer ),主要是为了提高性能,内核可以预读部分数据,当所需数据小于内存缓冲区大小时,将极大的提高性能。
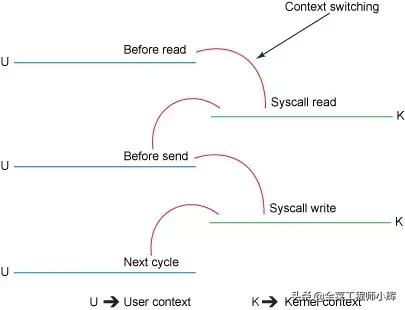
IO的内核切换
磁盘到内核空间属于DMA拷贝,用户空间与内核空间之间的数据传输并没有类似DMA这种可以不需要CPU参与的传输方式,因此用户空间与内核空间之间的数据传输是需要CPU全程参与的(如上图所示)。
DMA拷贝即直接内存存取,原理是外部设备不通过CPU而直接与系统内存交换数据
所以也就有了使用零拷贝技术,避免不必要的CPU数据拷贝过程。
NIO的零拷贝
NIO的零拷贝由transferTo方法实现。transferTo方法将数据从FileChannel对象传送到可写的字节通道(如Socket Channel等)。在transferTo方法内部实现中,由native方法transferTo0来实现,它依赖底层操作系统的支持。在UNIX和Linux系统中,调用这个方法会引起sendfile()系统调用,实现了数据直接从内核的读缓冲区传输到套接字缓冲区,避免了用户态(User-space) 与内核态(Kernel-space) 之间的数据拷贝。
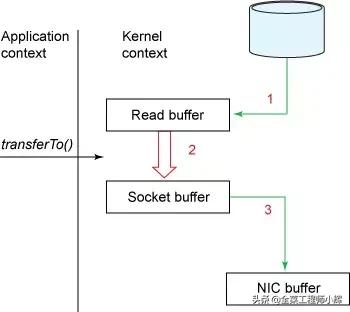
NIO零拷贝
使用NIO零拷贝,流程简化为两步:
- transferTo方法调用触发DMA引擎将文件上下文信息拷贝到内核读缓冲区,接着内核将数据从内核缓冲区拷贝到与套接字相关联的缓冲区。
- DMA引擎将数据从内核套接字缓冲区传输到协议引擎(第三次数据拷贝)。
内核态与用户态切换如下图:
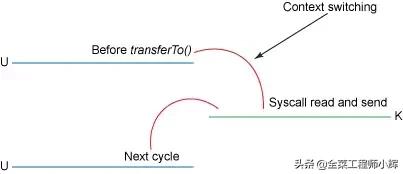
NIO零拷贝的内核切换
相比传统IO,使用NIO零拷贝后改进的地方:
- 我们已经将上下文切换次数从4次减少到了2次;
- 将数据拷贝次数从4次减少到了3次(其中只有1次涉及了CPU,另外2次是DMA直接存取)。
如果底层NIC(网络接口卡)支持gather操作,可以进一步减少内核中的数据拷贝。在Linux 2.4以及更高版本的内核中,socket缓冲区描述符已被修改用来适应这个需求。这种方式不但减少上下文切换,同时消除了需要CPU参与的重复的数据拷贝。
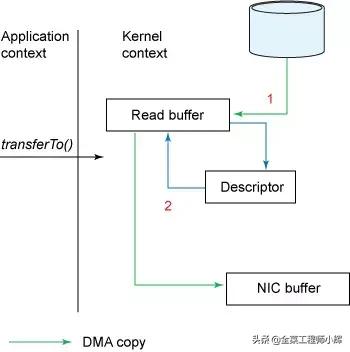
NIO
用户这边的使用方式不变,依旧通过transferTo方法,但是方法的内部实现发生了变化:
- transferTo方法调用触发DMA引擎将文件上下文信息拷贝到内核缓冲区。
- 数据不会被拷贝到套接字缓冲区,只有数据的描述符(包括数据位置和长度)被拷贝到套接字缓冲区。DMA 引擎直接将数据从内核缓冲区拷贝到协议引擎,这样减少了最后一次需要消耗CPU的拷贝操作。
NIO零拷贝适用于以下场景:
- 文件较大,读写较慢,追求速度
- JVM内存不足,不能加载太大数据
- 内存带宽不够,即存在其他程序或线程存在大量的IO操作,导致带宽本来就小
NIO的零拷贝代码示例
/** * filechannel进行文件复制(零拷贝) * * @param fromFile 源文件 * @param toFile 目标文件 */public static void fileCopyWithFileChannel(File fromFile, File toFile) { try (// 得到fileInputStream的文件通道 FileChannel fileChannelInput = new FileInputStream(fromFile).getChannel(); // 得到fileOutputStream的文件通道 FileChannel fileChannelOutput = new FileOutputStream(toFile).getChannel()) { //将fileChannelInput通道的数据,写入到fileChannelOutput通道 fileChannelInput.transferTo(0, fileChannelInput.size(), fileChannelOutput); } catch (IOException e) { e.printStackTrace(); }}static final int BUFFER_SIZE = 1024;/** * BufferedInputStream进行文件复制(用作对比实验) * * @param fromFile 源文件 * @param toFile 目标文件 */public static void bufferedCopy(File fromFile,File toFile) throws IOException { try(BufferedInputStream bis = new BufferedInputStream(new FileInputStream(fromFile)); BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(toFile))){ byte[] buf = new byte[BUFFER_SIZE]; while ((bis.read(buf)) != -1) { bos.write(buf); } }}在不需要进行数据文件操作时,可以使用NIO的零拷贝。但如果既需要IO速度,又需要进行数据操作,则需要使用NIO的直接内存映射。
直接内存映射
Linux提供的mmap系统调用, 它可以将一段用户空间内存映射到内核空间, 当映射成功后, 用户对这段内存区域的修改可以直接反映到内核空间;同样地, 内核空间对这段区域的修改也直接反映用户空间。正因为有这样的映射关系, 就不需要在用户态(User-space)与内核态(Kernel-space) 之间拷贝数据, 提高了数据传输的效率,这就是内存直接映射技术。
NIO的直接内存映射
JDK1.4加入了NIO机制和直接内存,目的是防止Java堆和Native堆之间数据复制带来的性能损耗,此后NIO可以使用Native的方式直接在 Native堆分配内存。
背景:堆内数据在flush到远程时,会先复制到Native 堆,然后再发送;直接移到堆外就更快了。
在JDK8,Native Memory包括元空间和Native 堆。更多有关JVM的知识,点击查看JVM内存模型和垃圾回收机制
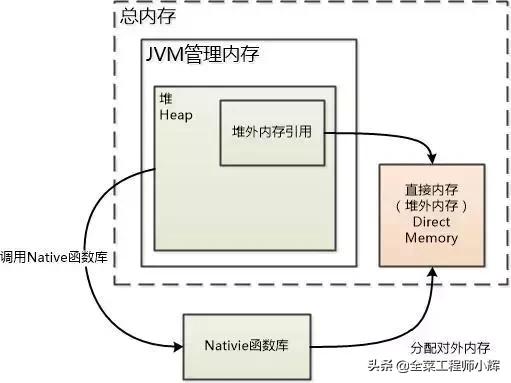
直接内存
直接内存的创建
在ByteBuffer有两个子类,HeapByteBuffer和DirectByteBuffer。前者是存在于JVM堆中的,后者是存在于Native堆中的。
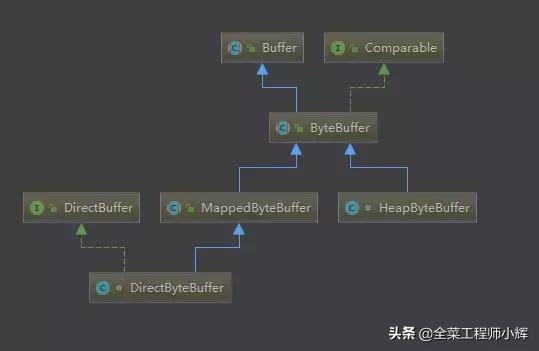
UML
申请堆内存
public static ByteBuffer allocate(int capacity) { if (capacity < 0) throw new IllegalArgumentException(); return new HeapByteBuffer(capacity, capacity);}申请直接内存
public static ByteBuffer allocateDirect(int capacity) { return new DirectByteBuffer(capacity);}使用直接内存的原因
- 对垃圾回收停顿的改善。因为full gc时,垃圾收集器会对所有分配的堆内内存进行扫描,垃圾收集对Java应用造成的影响,跟堆的大小是成正比的。过大的堆会影响Java应用的性能。如果使用堆外内存的话,堆外内存是直接受操作系统管理。这样做的结果就是能保持一个较小的JVM堆内存,以减少垃圾收集对应用的影响。(full gc时会触发堆外空闲内存的回收。)
- 减少了数据从JVM拷贝到native堆的次数,在某些场景下可以提升程序I/O的性能。
- 可以突破JVM内存限制,操作更多的物理内存。
当直接内存不足时会触发full gc,排查full gc的时候,一定要考虑。
有关JVM和GC的相关知识,请点击查看JVM内存模型和垃圾回收机制
使用直接内存的问题
- 堆外内存难以控制,如果内存泄漏,那么很难排查(VisualVM可以通过安装插件来监控堆外内存)。
- 堆外内存只能通过序列化和反序列化来存储,保存对象速度比堆内存慢,不适合存储很复杂的对象。一般简单的对象或者扁平化的比较适合。
- 直接内存的访问速度(读写方面)会快于堆内存。在申请内存空间时,堆内存速度高于直接内存。
直接内存适合申请次数少,访问频繁的场合。如果内存空间需要频繁申请,则不适合直接内存。
NIO的直接内存映射
NIO中一个重要的类:MappedByteBuffer——java nio引入的文件内存映射方案,读写性能极高。MappedByteBuffer将文件直接映射到内存。可以映射整个文件,如果文件比较大的话可以考虑分段进行映射,只要指定文件的感兴趣部分就可以。
由于MappedByteBuffer申请的是直接内存,因此不受Minor GC控制,只能在发生Full GC时才能被回收,因此Java提供了DirectByteBuffer类来改善这一情况。它是MappedByteBuffer类的子类,同时它实现了DirectBuffer接口,维护一个Cleaner对象来完成内存回收。因此它既可以通过Full GC来回收内存,也可以调用clean()方法来进行回收
NIO的直接内存映射的函数调用
FileChannel提供了map方法来把文件映射为内存对象:
MappedByteBuffer map(int mode,long position,long size);
可以把文件的从position开始的size大小的区域映射为内存对象,mode指出了 可访问该内存映像文件的方式
- READ_ONLY,(只读): 试图修改得到的缓冲区将导致抛出 ReadOnlyBufferException.(MapMode.READ_ONLY)
- READ_WRITE(读/写): 对得到的缓冲区的更改最终将传播到文件;该更改对映射到同一文件的其他程序不一定是可见的。 (MapMode.READ_WRITE)
- PRIVATE(专用): 对得到的缓冲区的更改不会传播到文件,并且该更改对映射到同一文件的其他程序也不是可见的;相反,会创建缓冲区已修改部分的专用副本。 (MapMode.PRIVATE)
使用参数-XX:MaxDirectMemorySize=10M,可以指定DirectByteBuffer的大小最多是10M。
直接内存映射代码示例
static final int BUFFER_SIZE = 1024;/** * 使用直接内存映射读取文件 * @param file */public static void fileReadWithMmap(File file) { long begin = System.currentTimeMillis(); byte[] b = new byte[BUFFER_SIZE]; int len = (int) file.length(); MappedByteBuffer buff; try (FileChannel channel = new FileInputStream(file).getChannel()) { // 将文件所有字节映射到内存中。返回MappedByteBuffer buff = channel.map(FileChannel.MapMode.READ_ONLY, 0, channel.size()); for (int offset = 0; offset < len; offset += BUFFER_SIZE) { if (len - offset > BUFFER_SIZE) { buff.get(b); } else { buff.get(new byte[len - offset]); } } } catch (IOException e) { e.printStackTrace(); } long end = System.currentTimeMillis(); System.out.println("time is:" + (end - begin));}/** * HeapByteBuffer读取文件 * @param file */public static void fileReadWithByteBuffer(File file) { long begin = System.currentTimeMillis(); try(FileChannel channel = new FileInputStream(file).getChannel();) { // 申请HeapByteBuffer ByteBuffer buff = ByteBuffer.allocate(BUFFER_SIZE); while (channel.read(buff) != -1) { buff.flip(); buff.clear(); } } catch (IOException e) { e.printStackTrace(); } long end = System.currentTimeMillis(); System.out.println("time is:" + (end - begin));}更多内容,欢迎关注微信公众号:全菜工程师小辉~
更多相关:
-
一、预备知识—程序的内存分配 一个由c/C++编译的程序占用的内存分为以下几个部分 1、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈,如果还不清楚,那么就把它想成数组,它的内存分配是连续分配的,即,所分配的内存是在一块连续的内存区域内.当我们声明变量时,那么编译器...
-
我的爱机是一台ThinkPad T420,原装三星DDR 1333 4G内存一根,还剩一根内存位置,最近趁京东6.18促销,准备增加一根物理内存。为了确保兼容性,觉得仍然选购DDR 1333 4G内存,于是购买了金士顿这款,比如DDR3 1600的还贵。 这个安装过程完全参照该内存的网页提示进行 这里简单记录一下,以备...
-
陪伴我多年的老本ThinkPad T420渐渐垂垂老矣, 我想更新一下可以更新的部分, 比如将2.5寸HDD更换为SSD, 将单条4G内存再增加一根, 凡此种种想法, 可能最后归结为如何获取该笔记本的硬件配置信息, 在windows下面使用鲁大师之类的检测软件, 也许很好搞定,但是在Ubuntu 14.04平台上如果办到呢? 很简单...
-
一.内存错误出现的场景 这几天在重构ATS插件代码的过程中遇到了烦人的内存泄露问题, 周五周六连续两天通过走查代码的方法,未能看出明显的导致内存错误的代码, 同时也觉得C和C++混合编程得到一个动态库, 在一个.cpp主文件中,即用new又用malloc来动态分配内存, 可能会导致内存错误.后来网上调研和查资料发现, new和mal...
-
F5→去项目文件夹Debug里面找到exe文件,拷贝到另外电脑即可运行 ...
-
1.Tcpdive的基本原理 Tcpdive是基于linux内核的探测点机制,使用systemtap脚本语言和内嵌C代码来实现的。 通过定义几类相互关联的探测点和库函数,来收集和处理运行中内核的数据,以及修改内核的处理逻辑。 2.源码目录 https://github.com/fastos/tcpdive 目前的代码基...
-
下面是我结合网上资料摸索出的可行的操作方法,记录在这样,以备后面继续研究。操作系统是CentOS 6.6 x86_64。 1.将内核版本升级到最新版 因为我机器上CentOS 6.6的内核版本号是2.6.32-573.12.1.el6.x86_64,网上根本找不到对应的kernel-devel,kernel-debuginfo和k...
-
在基于CentOS平台的工作过程中,难免有时需要升级或者降级内核以验证功能、调试性能或者更新整个系统。 如果从头重新编译一个内核费时费力,另外加之现在内核特性越来越复杂,依赖的库或者工具也不少,找到一种简单的升级内核方法将非常必要。 下面是我实践过的最简单方法。 系统环境: CentOS 6.6 x86_64 1:查看系统版...
-
关于系统目录树和源码目录树的结构图如下 内核版本: centos 7.0 升级内核之后 3.10.0-957-5.1.e17...
-
下述为UCloud资深工程师邱模炯在InfoQ架构师峰会上的演讲——《UCloud云平台的内核实践》中非常受关注的内核热补丁技术的一部分。给大家揭开了UCloud云平台内核技术的神秘面纱。 如何零代价修复海量服务器的Linux内核缺陷? 对于一个拥有成千上万台服务器的公司,Linux内核缺陷导致的死机屡见不鲜。让工程师们纠结的...