数据结构 -- 散列表
散列表作为一种能够提供高效插入,查找,删除 以及遍历的数据结构,被应用在很多不同的存储组件之中。
就像rocksdb中的hashskiplist,redis的有序集合,java的 LinkedHashMap 等 都是一些非常有特色的核心数据结构,来提供线上高效的数据操作能力。
本节对工业级散列表的基本实现 探索一番,希望加深自己对存储产品设计理念的理解。
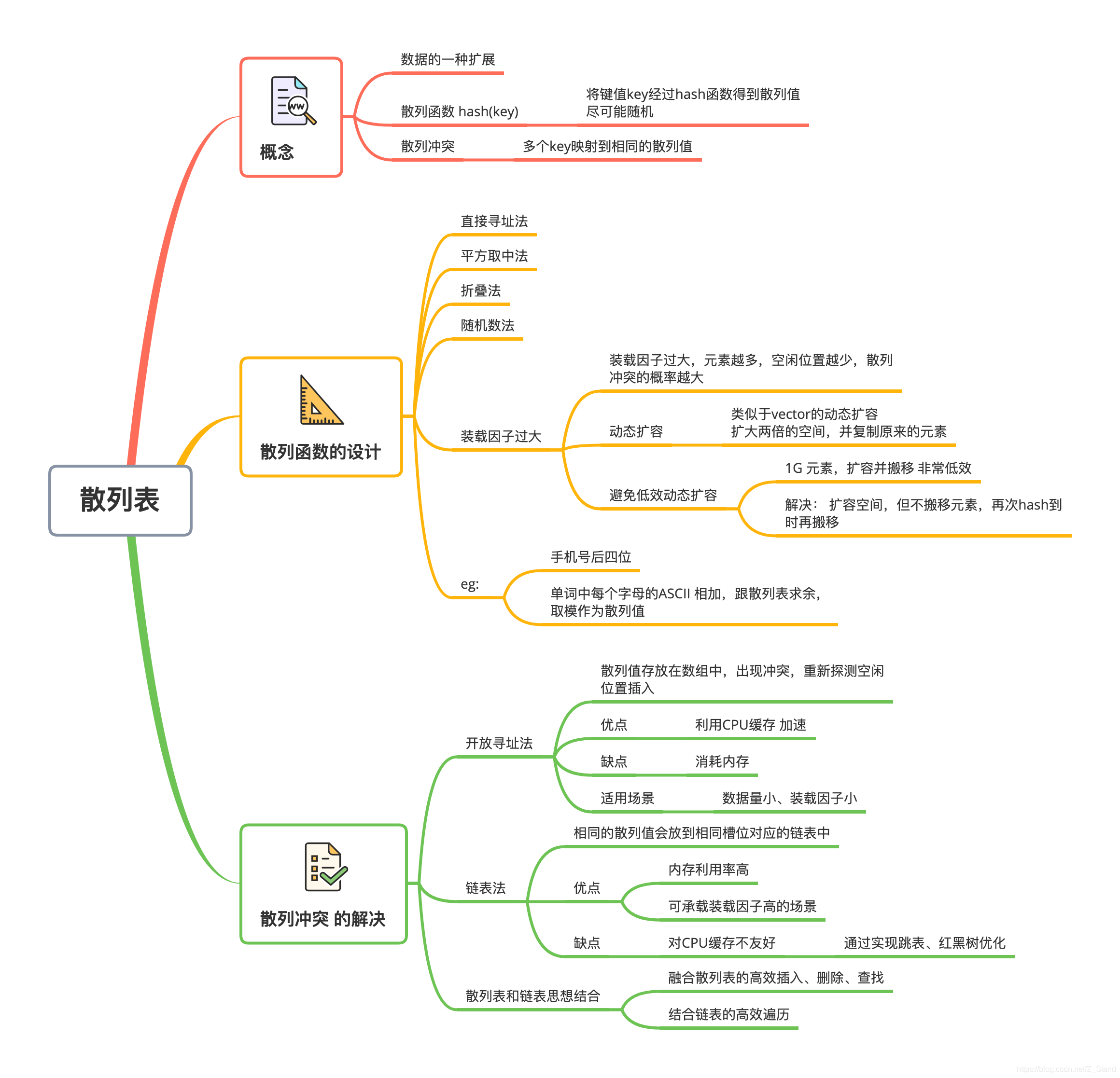
工业级的散列表需要具有如下能力:
-
初始大小
散列表的初始大小,刚开始的时候需要拥有一定量的存储空间,根据实际应用情况可以通过设置散列表的初始大小,从而减少动态扩容的次数,依次提升性能。 -
装载因子 和 动态扩容
最大装载因子默认是0.75, 即散列表中已存储的元素个数达到了总大小的0.75,则开始扩容 -
散列冲突的解决
根据实际情况选择通用的两种方案: 开放寻址法 和 链表法
开放寻址法:使用数组进行底层存储,出现冲突时重新探测数据中的空闲位置,进一步插入,该方法能够利用CPU缓存功能进行加速,但是比较耗费内存空间。
基本过程如下:
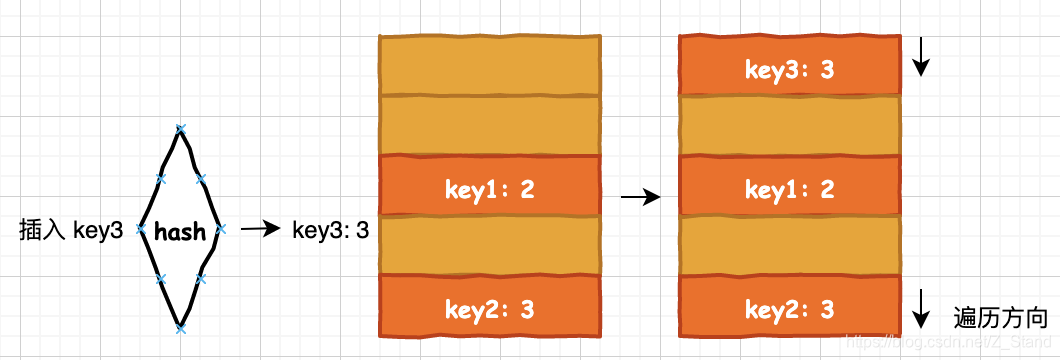
插入key3的时候hash函数计算的散列值也为3,和key2的散列值冲突,那么将向key2之后插入,但是发现key2之后没有空间了,则跳到数据开头重新遍历找到第一个空闲的位置插入。链表法:将相同散列值的元素放入到相同的槽位,每一个槽位用链表管理相同hash值的元素
该方法能够高效利用内存(链表节点生成新节点的时候才会分配空间),只是对CPU缓存不太友好,地址之间并不是连续的,CPU缓存基本不能生效。(这里可以通过一些有序的数据结构进行优化-- 跳表和红黑树)
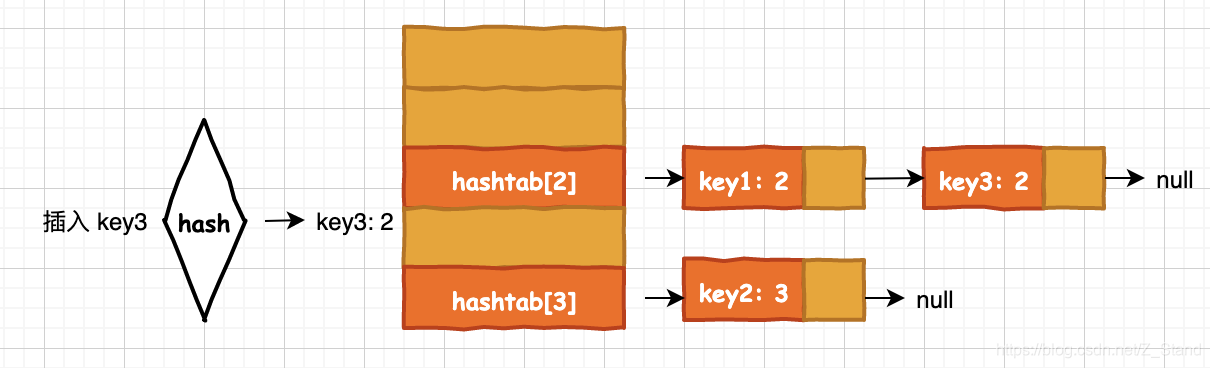
插入的key3有和key1相同的散列值,则将key3直接插入到key1对应的bucket链表末尾,实际过程需要有序,所以这里插入到hashtab[2]的时候还需要找到对应的链表节点前驱。
-
散列函数
散列函数的设计不追求复杂,但是需要高效,计算但散列值要分布均匀。
java的LinkedHashMap的散列函数设计如下:int hash(Object key) { int h = key.hashCode();return (h ^ (h >>> 16)) & (capitity -1); //capicity表示散列表的大小 }其中,hashCode()返回的是Java对象的hash code。比如String类型的对象的hashCode()就是下面这样:
public int hashCode() { int var1 = this.hash;if(var1 == 0 && this.value.length > 0) { char[] var2 = this.value;for(int var3 = 0; var3 < this.value.length; ++var3) { var1 = 31 * var1 + var2[var3];}this.hash = var1;}return var1; }设计的过程中尽可能保证数据的随机性,就像手机号的后四位 一般是随机均匀分布,这样取用数据的过程即可作为hash函数。
通过以上四点的设计,我们基本能够完成一个工业级的散列表实现,再做一个总结,工业级的散列表的特性:
- 支持快速的查询、插入、删除操作;
- 内存占用合理,不能浪费过多的内存空间;
- 性能稳定,极端情况下,散列表的性能也不会退化到无法接受的情况
工业级散列表的设计实现思路:
- 设计一个合适的散列函数;
- 定义装载因子阈值,并且设计动态扩容策略
- 选择合适的散列冲突解决方法
通过以上设计,使用C语言编写一个简单的工业级散列表实现如下,散列冲突是通过链表解决的
listhash.h
#ifndef __HASHTAB_H__
#define __HASHTAB_H__typedef struct _hashtab_node
{ void * key;void * data;struct _hashtab_node *next;
}hashtab_node;typedef struct _hashtab
{ hashtab_node **htables; /*哈希桶*/int size; /*哈希桶的最大数量*/int nel; /*哈希桶中元素的个数*/int (*hash_value)(struct _hashtab *h,const void *key); /*哈希函数*/int (*keycmp)(struct _hashtab*h,const void *key1,const void *key2);/*哈希key比较函数,当哈希数值一致时使用*/void (*hash_node_free)(hashtab_node *node);
}hashtab;#define HASHTAB_MAX_NODES (0xffffffff)typedef int (*hash_key_func)(struct _hashtab *h,const void *key); /*哈希函数*/
typedef int (*keycmp_func)(struct _hashtab*h,const void *key1,const void *key2);/*哈希key比较函数,当哈希数值一致时使用*/
typedef void (*hash_node_free_func)(hashtab_node *node);
/*根据当前结构体元素的地址,获取到结构体首地址*/
#define offsetof(TYPE,MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
#define container(ptr,type,member) ({const typeof( ((type *)0)->member) *__mptr = (ptr);(type *) ( (char *)__mptr - offsetof(type,member));})hashtab * hashtab_create(int size,hash_key_func hash_value,keycmp_func keycmp,hash_node_free_func hash_node_free);
void *hashtab_expand(hashtab*h);
void hashtab_destory(hashtab *h);
int hashtab_insert(hashtab * h,void *key,void *data);
hashtab_node *hashtab_delete(hashtab *h, void *key);
void *hashtab_search(hashtab*h,void *key);#endif
listhash.c
#include更多相关:
-
前言 近期在做on nvme hash引擎相关的事情,对于非全序的数据集的存储需求,相比于我们传统的LSM或者B-tree的数据结构来说 能够减少很多维护全序上的计算/存储资源。当然我们要保证hash场景下的高写入能力,append-only 还是比较友好的选择。 像 Riak的bitcask 基于索引都在内存的hash引擎这种,...
-
前言 最近在读 MyRocks 存储引擎2020年的论文,因为这个存储引擎是在Rocksdb之上进行封装的,并且作为Facebook 内部MySQL的底层引擎,用来解决Innodb的空间利用率低下 和 压缩效率低下的问题。而且MyRocks 在接入他们UDB 之后成功达成了他们的目标:将以万为单位的服务器集群server个数缩减了一...
-
参考自: https://www.cnblogs.com/zeng1994/p/03303c805731afc9aa9c60dbbd32a323.html 1、maven依赖
springboot redis配置
1、引入maven依赖
org.springframework.boot spring-boot-starter-data-redis json 键值对增加、删除 obj.key='value'; // obj.key=obj[key]=eval("obj."+key); delete obj.key; vue中新增和删除属性 this.$set(object,key,value) this.$delete( object, key ) 触发视图更新 遍历键值 for...
在使用空时,习惯这么赋值 int *p = NULL; 编译器进行解释程序时,NULL会被直接解释成0,所以这里的参数根本就不是大家所想的NULL,参数已经被编译器偷偷换成了0,0是整数。 因此这面的问题就尴尬了 不好意思图片引用于网络中。 为啥呢不是this is the ptr function…这个。这就是C++中的...
var d= {a: 1,b: null,c: 3,d: undefined };Object.keys(d).forEach(k=>d[k]==null&&delete d[k]);//去掉值为null或undefined的对象属性//Object.keys(d).forEach(k=>(d[k]==null||d[k]==='')...
//ES6获取浏览器url跟参 public getUrlParam = a => (a = location.search.substr(1).match(new RegExp(`(^|&)${a}=([^&]*)(&|$)`)),a?a[2]:null);...
文章目录1. 解决问题2. 应用场景3. 实现如下C++实现C语言实现4. 缺点 1. 解决问题 在简单工厂模式中,我们使用卖衣服进行举例,同一种工厂可以卖很多不同种类的衣服,工厂只是将衣服的生产过程进行了封装。 当我们增加衣服种类的时候,在简单工厂模式中需要修改工厂的代码,破坏了类的开闭原则(对扩展开发, 对修改关闭),...
在服务端数据库的处理当中,涉及中文字符的结构体字段,需要转为Utf8后再存储到表项中。从数据库中取出包含中文字符的字段后,如果需要保存到char *类型的结构体成员中,需要转为Ansi后再保存。从数据库中取出类型数字的字段后,如果需要保存到int型的结构体成员中,需要调用atoi函数进行处理后再保存。 1 static char *...