linux文件IO与内存映射:分散/聚集IO技术(scatter-gather)
前言
根据上文我们学习到的用户空间的IO缓冲区,操作系统为了减少系统调用的次数,节省系统开销,提出了用户空间的IO缓冲区,即为用户空间的文件读写开辟一段可以利用setvbuf配置大小的内存空间来作为文件IO缓冲区。
描述
为了在以上IO缓冲区的基础上更进一步得减少系统调用的次数,提出了分散/聚合IO技术,总体上是使用了单个向量的IO操作代替了多个向量的IO操作。
读文多个件的时候将从page cache中读到的内容先读入到一个IO缓冲区数据结构中,再由一个缓冲区分别分散返回到多个文件缓冲区中;写文件的过程与读文件的过程刚好相反,即将多个文件缓冲区的内容聚合写到一个缓冲区中,写入page cache中,从而更高得提升系统调用效率。
实现
实现scatter-gather技术的系统调用原型如下:
-
头文件
-
函数使用:
ssize_t readv(int fd, const struct iovec *iov, int iovcnt);
ssize_t writev(int fd, const struct iovec *iov, int iovcnt); -
函数参数
fd:打开的文件描述符
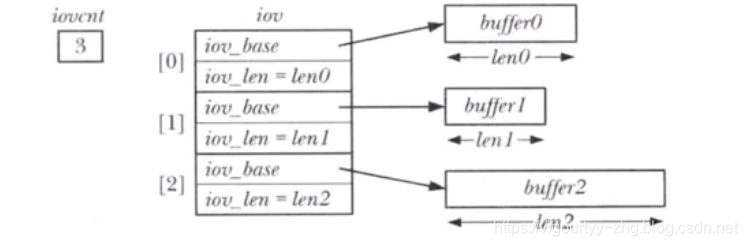
iov: IO向量数据结构内容如下,每个结构体成员代表一个buffer:struct iovec { void *iov_base; /* Starting address */size_t iov_len; /* Number of bytes to transfer */};iovcnt:IO向量的个数这两个系统调用的底层仍然是使用read/write系统调用,只是对IO 缓冲区做了聚合,支持多个IO缓冲区内容聚合到同一个IO向量中
代码如下:
writev.c
#include readv.c
#include 编译输出如下:
gcc writev.c -o writev
gcc readv.c -o readv
zhang@ubuntu:~/Desktop/cpp_practice$ ./writev writevfile
iovec[0] size is 9
iovec[1] size is 9
iovec[2] size is 9
zhang@ubuntu:~/Desktop/cpp_practice$ ./readv writevfile buffer1buffer2buffer3
buf1 buffer1buf2 buffer2buf3 buffer3
更多相关:
-
文章目录先看看性能AIO 的基本实现io_ring 使用io_uring 基本接口liburing 的使用io_uring 非poll 模式下 的实现io_uring poll模式下的实现io_uring 在 rocksdb 中的应用总结参考...
-
文章目录用户空间IO缓冲区产生IO缓冲区 描述IO缓冲区的写模式自定义IO缓冲区 用户空间IO缓冲区产生 系统调用过程中会产生的开销如下: 切换CPU到内核态进行数据内容的拷贝,从用户态到内核态或者从内核态到用户态切换CPU到用户态 以上为普通到系统调用过程中操作系统需要产生的额外开销,为了提升系统调用的性能,这里推出用...
-
串口发送部分代码: //通过信号量的方法发送数据 void usart1SendData(CPU_INT08U ch) {OS_ERR err;CPU_INT08U isTheFirstCh;OSSemPend(&Usart1Sem, 0, OS_OPT_PEND_BLOCKING, NULL, &err);//阻塞型等待串口发送资...