本推文主要识别的验证码是这种:
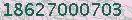


第一步: 二值化
所谓二值化就是把不需要的信息通通去除,比如背景,干扰线,干扰像素等等,只剩下需要识别的文字,让图片变成2进制点阵。
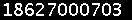

第二步: 文字分割
为了能识别出字符,需要对要识别的文字图图片进行分割,把每个字符作为单独的一个图片看待。



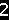

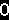

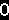

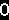
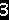
第三步: 标准化
对于部分特殊的验证码,需要对分割后的图片进行标准化处理,也就是说尽量把每个相同的字符都变成一样的格式,减少随机的程度。最简单的比如旋转还原,复杂点的比如扭曲还原等等。比如本文中分割后的数字1和8宽度不一致,把他们的宽度填充一致,就是标准化的一种。
可以看到上面切割后的字符1最右边一列像素都为0。
第四步: 学习 & 识别
这一步可以用很多种方法,最简单的就是模板对比,对每个出现过的字符进行处理后把点阵变成字符串,标明是什么字符后,通过字符串对比来判断相似度。
在文章的后半部分会详细解释我采用的算法。
训练集学习tran.m
width = 132; height = 20;%共10张验证码 x 11个数字 共分割出 110张字符图片
%每个字符图片 高度20 x 宽度9 共 180个像素
data = zeros(110, 180);chars = zeros(180, 10); %用于存储10个数字字符的特征值 每个字符大小为20x9for name = 0:9im = imread(sprintf('%d.jpg', name)); %读取图片im = im2bw(im) == 0; %第一步:二值化 黑色1 白色0%第二步: 分割black = sum(im) ~= 0; %20x132矩阵 从上向下求和为 1x132 不等于0 则横坐标对应的一列有字符像素white = sum(im) == 0; %20x132矩阵 从上向下求和为 1x132 等于0 则横坐标对应的一列没有字符像素lower = find(min([black 0],[1 white])); %获取11个字符的开始下标upper = find(min([0 black],[white 1])) - 1; %获取11个字符的结束下标for i=1:11ch = im(:,lower(i):upper(i)); %截取单个字符ch(20, 9) = 0; %第三步: 字符二值化矩阵大小标准化为20x9data(name*11 + i ,:) = ch(:); %字符图片数据存入dataend
end%第四步: 学习 & 识别
class = clusterdata(data, 10); %将110个字符图片分为10类%各个分类号对应的实际数字(人工识别后写进去的- -)
num = [5 3 6 8 9 0 7 2 1 4];for i = 1:10%各类中的字符图片取均值im = mean(data(class == i, :)) > 0.5; chars(:, num(i) + 1) = im; %存储
end验证码识别ocr.m
function ret = ocr(filename)load;ret = zeros(1, 11);im = imread(filename);im = im2bw(im) == 0; %第一步: 二值化%第二步: 分割black = sum(im) ~= 0;white = sum(im) == 0;lower = find(min([black 0],[1 white]));upper = find(min([0 black],[white 1])) - 1;for i=1:11ch = im(:,lower(i):upper(i));ch = ch(:);ch(180) = 0; %第三步标准化%第四步: 识别[~, num] = max(sum(min(repmat(ch, 1, 10), chars)));ret(i) = num-1;end
end来源: https://cloud.tencent.com/developer/article/1030270
来自为知笔记(Wiz)