OpenResty中的upstream healthcheck功能沉思录
healthcheck功能本质上还是个定时器,去定期检查指定upstream组的状态,它发送指定的http请求并解析响应码,去探测upstream中每个peer的存活状态,再结合历史请求记录来判断并标记其状态,如果有状态改变,就在共享内存中更新版本记录,下次执行时,所有的worker进程都要更新到最新的peer状态。
下面的表述都假定我们要监控的upstream组名是ats_node_backend, 也就是对应nginx.conf中的这个代码块
upstream ats_node_backend {
server 127.0.0.2;
server 127.0.0.3 backup;
server 127.0.0.4 fail_timeout=23 weight=7 max_fails=200 backup;
}
配置参数解释
hc.spawn_checker(options)
options中包含如下选项,在调用该接口时作为参数传递进来
type 必须存在并且是http,目前只支持http
http_req 必须存在,健康探测的http请求raw字符串
timeout 默认1000,单位ms
interval 健康探测的时间间隔,单位ms, 默认1000,推荐2000
valid_status 合法响应码的表,比如{200, 302}
concurrency 并发数,默认1
fall 默认5,对UP的设备,连续fall次失败,认定为DOWN
rise 默认2,对DOWN的设备,连续rise次成功,认定为UP
shm 必须配置,用于健康检查的共享内存名称,通过ngx.shared[shm]得到共享内存
upstream 指定要做健康检查的upstream组名,必须存在
version 默认0
primary_peers 主组
backup_peers 备组
statuses 存放合法响应码的数组,来自ipairs()得到的valid_status配置项
根据options会构造一个ctx表来存放所有的配置数据,并会作为定时器ngx.timer.at()中的第三个参数
ctx的内容如下
upstream 指定的upstream组名
primary_peers 主组
backup_peers 备组
http_req 健康检查的raw http请求
timeout 超时时间,单位s,注意不是ms
interval 健康检查的间隔,单位s,注意不是ms
dict 存放统计数据的共享内存
fall 认为DOWN之前的连续失败次数,默认5
rise 认为UP之前的连续成功次数,默认2
statuses 认为正常的http状态码的表{200,302}
version 0 每次执行定时任务时的版本号,有peer状态改变,版本号加1
concurrency 创建该数目的轻量线程来并发发送健康检测请求的个数
上面的这些配置项,将作为一个上下文保存下来,在不同的阶段被反复调用
使用方法
在init_worker_by_lua_block阶段,在nginx.conf中放入下面的代码
local hc = require "resty.upstream.healthcheck"local ok, err = hc.spawn_checker{shm = "healthcheck", -- defined by "lua_shared_dict"upstream = "foo.com", -- defined by "upstream"type = "http",http_req = "GET /status HTTP/1.0
Host: foo.com
",-- raw HTTP request for checkinginterval = 2000, -- run the check cycle every 2 sectimeout = 1000, -- 1 sec is the timeout for network operationsfall = 3, -- # of successive failures before turning a peer downrise = 2, -- # of successive successes before turning a peer upvalid_statuses = {200, 302}, -- a list valid HTTP status codeconcurrency = 10, -- concurrency level for test requests}if not ok thenngx.log(ngx.ERR, "failed to spawn health checker: ", err)returnend这里Host可以是127.0.0.1或是其它ip。如果你需要一个查看探测的upstream组的状态,可以再在nginx.conf中配置
server {...# status page for all the peers:location = /status {access_log off;allow 127.0.0.1;deny all;default_type text/plain;content_by_lua_block {local hc = require "resty.upstream.healthcheck"ngx.say("Nginx Worker PID: ", ngx.worker.pid())ngx.print(hc.status_page())}}}然后在外面直接访问
wget 'http://127.0.0.1/status'
就可以看到所有upstream的peer状态,特别是我们检测的ats_node_backend这组,没有配置检测的upstream组前面会有"(NO checkers)"字样。
代码架构
本身是个定时器,该模块对外提供了两个接口
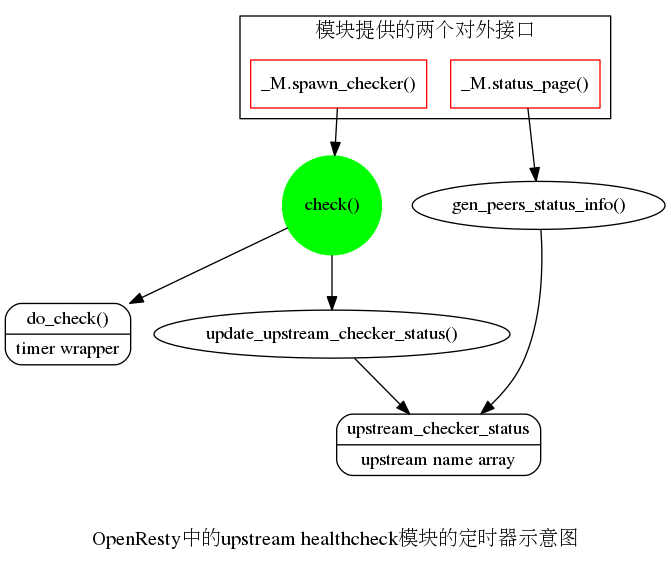
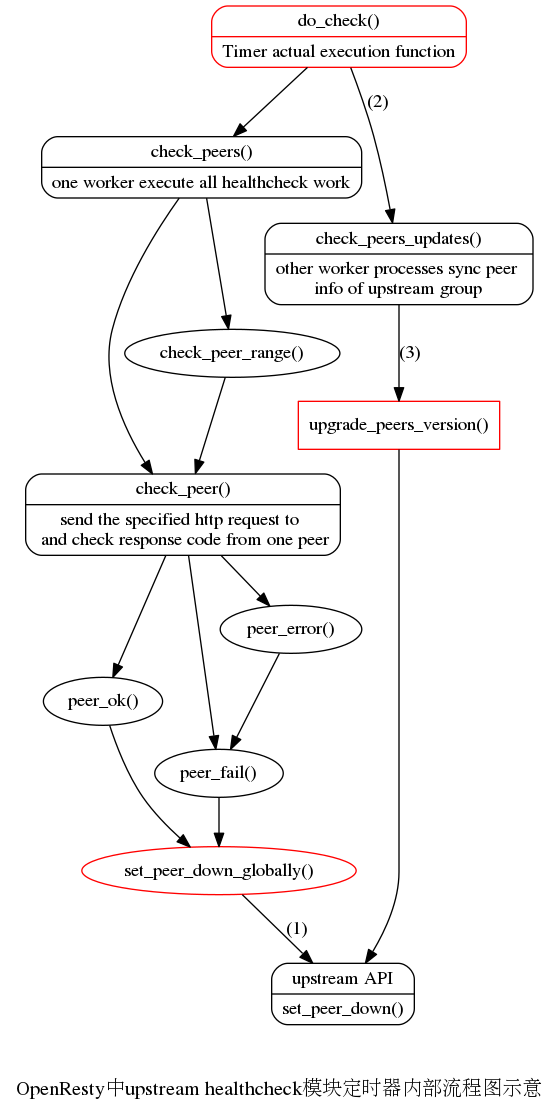
该定时器内干的活儿如下:
自问自答
1.如何对一个peer做健康探测?
通俗的健康探测可以是尝试与peer连接,或者发送http请求。后者是一种比较精确地检查服务是否正常的情况,因为只是做端口探测的话,如果服务僵死了,端口还是探测得通的。
healthcheck模块这里采用lua轻量级线程去专门向要检查的服务发送指定的http请求,并接收服务的响应状态码,根据状态码的情况来判断服务是否是正常的,断定UP或是DOWN
探测的结果无非两种情况:ok或是fail。因此,分为两种情况来对应存放,比如以key为ok:ats_node_backend:p9的记录来primary peers中peer id为9的设备的累计成功次数,同理nok:ats_node_backend:b1表示backup peers中peer id为1的设备的累计失败次数。
如果当前探测结果是成功,会首先去共享内存中查询累计的成功次数,并在原来的次数基础上增加1并更新到共享内存中。修改之后如果次数为0,就需要将对应的失败记录从共享内存中清除。
需要考虑3个因素,参见上面配置的标注(1)(2)(3):
(1)当前peer的状态peer.down, 从upstream模块的接口upstream.get_primary_servers()中获取peer.down的值, 另外也要谨慎处理当前worker中的这个peer.down值
(2)目前成功或是失败的次数
(3)healthcheck模块配置中的判断成功或失败的阈值,从定时器的ctx参数中可以得到, ctx.ok或ctx.fail
下面以判断下线状态为例来说明:
该peer当前是上线状态,也就是peer.down=nil或false,fails次数超过设定失败阈值,认定为下线(DOWN)
进一步的操作为调用set_peer_down_globally()函数,同时更改peer.down=true
关系是一样的
5.节点内多台设备的健康探测是怎样执行的?
采用nginx轻量级线程去并发执行多个检查任务,异步执行完之后,回调处理函数,处理完后该线程死掉。
6.当一个worker在healthcheck过程中发现某个peer掉线了,它是如何处理的?它如何将该peer的状态传递到所有其它worker知道?
在该脚本中是分为三步来完成的,参考上面的图示:(1)在set_peer_down_globally()函数中,对探测做出的结果,来设置一次set_peer_down,同时给出下面的两步来诱发后面的处理
说明ctx.new_version=true;
同时在共享内存中存入对应的记录,标记以d:ats_node_backend:p9为key的记录来表明该peer是UP还是DOWN状态
(2)在do_check()函数中,如果有新版本的话,先查询共享内存中的v:ats_node_backend的记录的值,加1,更新ctx.version,同时置空ctx.new_version。
这里的代码处理非常巧妙:
dict:add(key, 0)
local new_ver, err = dict:incr(key, 1)
使用dict:add()是为了避免插入重复的键值,如果该键已经存在,直接返回nil和和err="exists",如果不存在,直接置0
下一步是在原来的基础上加1,这一步妥妥能执行。
(3)在下一次定时任务执行时,所有worker进程首先去共享内存中查找key为v:ats_node_backend的记录的值,也就是获取ctx.version的精确值。比较当前值与ctx.version,如果ctx.version的值小于共享内存中的值,说明需要更新peer版本。
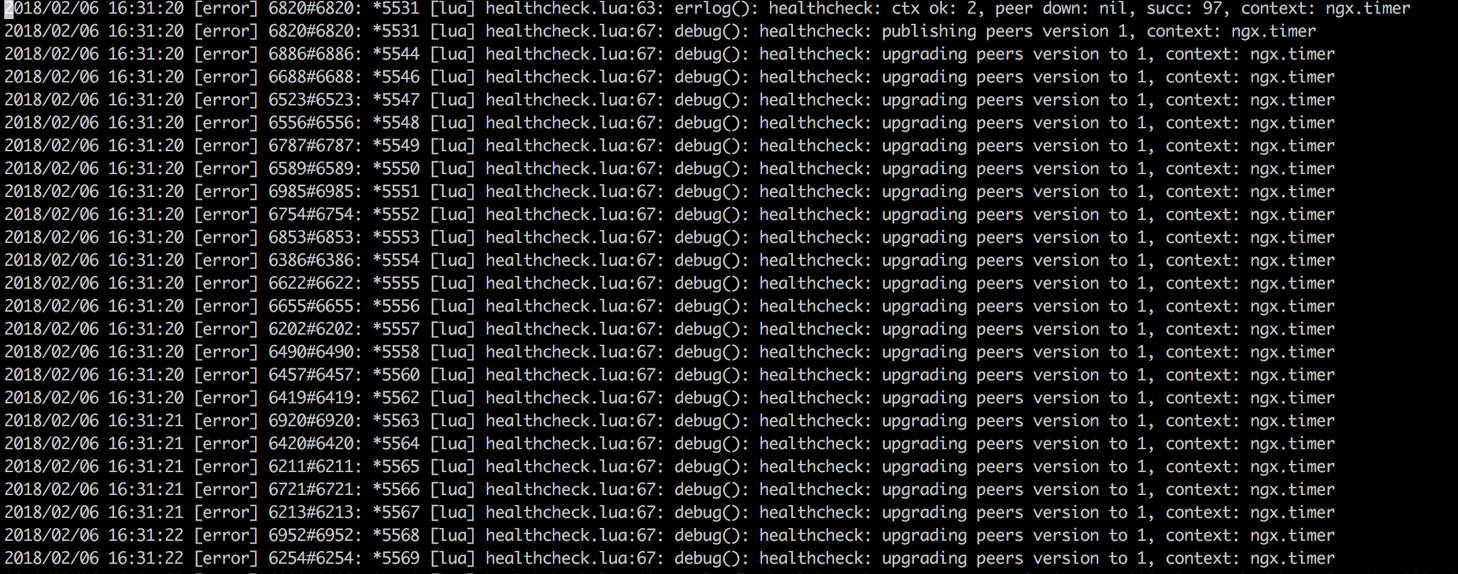
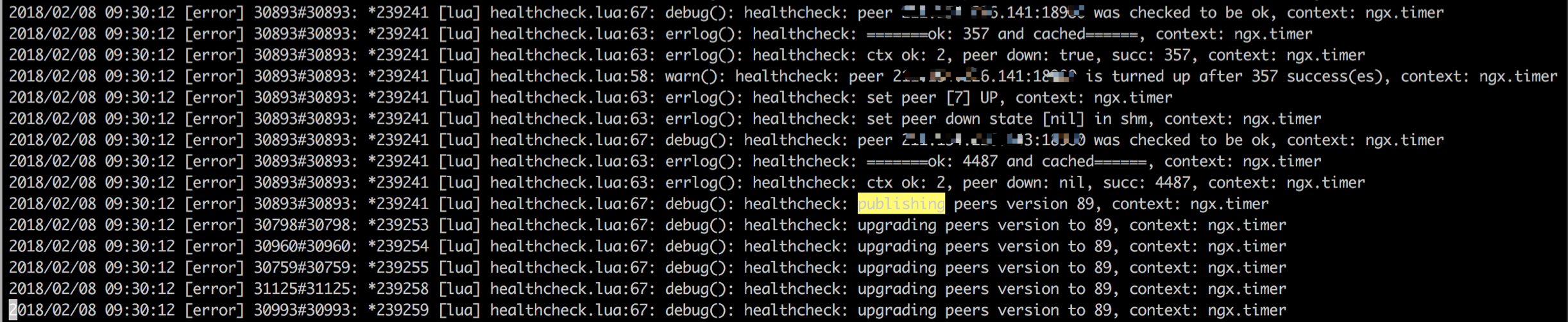
注意每条日志的worker进程号不一样,说明它们都在更新peer版本号。
7.其它的worker如何更新peer版本呢?
就是去共享内存中检查key为d:ats_node_backend:p9的记录,如果存在该记录,说明peer是DOWN,否则peer是UP。只有peer.down和查到的值不同,就需要set_peer_down,同时设置peer.down=down这主要是涉及到nginx中worker进程的执行和配置同步问题。一般来说,通常每份代码都会被所有的worker执行到,但是对peers的健康检查,我们只需要一个worker去执行就够了,一个worker执行完后,其它的worker来同步它的状态就够了。在do_check中我们看到除了下面的get_lock保护的代码是某个worker执行的,其它的代码,所有的worker都会去执行。定时任务采用进程抢占方式,每次执行的worker进程并不固定,这样的话,ctx.version一般是不连续的,通过共享内存方式,可以保证每个worker进程每次都可以得到最新的peer信息,而且peer version是逐渐递增的。
但是在一个worker执行过程中,ctx中的所有的字段都是可以在函数中传递的。
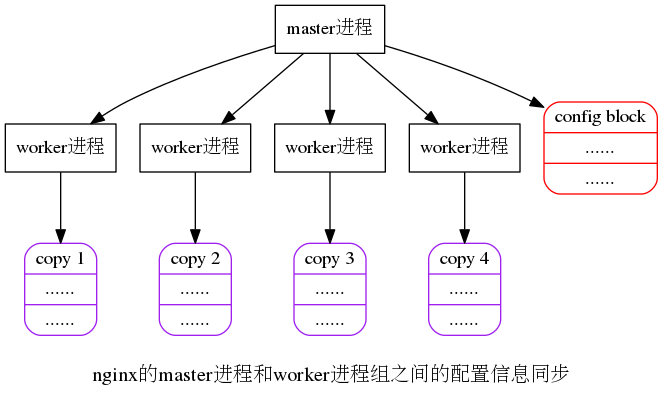
9.为啥要所有的worker进程都执行set_peer_down这个函数?
https://github.com/openresty/lua-upstream-nginx-module#set_peer_down
上面的官方文档强调了,该函数的执行必须所有的worker都执行,才能在server级别上生效。只在一个worker中执行,只能在该worker内部生效。
10.在nginx.conf中调用时,能否采用单进程调用方式,比如使用ngx.worker.id()==0的if条件语句?
这也是我曾经犯过的错误,答案当然是否定的。原因有两个:一个是为了让upstream.set_peer_down接口在server级别生效,必须所有的worker进程都要调用该函数;另一个,就是healthcheck模块内部已经实现了使用单个worker去进行实际的健康检测功能。
11.外部如何获取upstream中各peer之间的状态?
该模块对外提供了一个状态查询接口_M.status_page()下面说下它的处理细节:
在status_page()中会创建一个局部数组类型的表,来获取所有的统计信息,最后将这些数组中的元素拼接成字符串。
local bits = new_tab(n * 20, 0)
n = #us us是upstream的缩写,指upstream的组数,每组upstream会占用20个数组元素
table.concat 将table中的元素按照指定分隔符连接起来
bits数组内容如下
bits[0]="Upstream "
bits[1]="ats_node_backend"
bits[2]=" (NO checkers)"
bits[3]=" Primary Peers "
bits[4]=" "
bits[5]="10.10.101.10:18980"
bits[6]=" DOWN "
……
bits[n]=" Backup Peers "
bits[n+1]=" "
bits[n+2]="10.10.101.12:18980"
bits[n+3]=" up "
……
bits[n+m]=" "
参考文献
[1].https://github.com/openresty/lua-resty-upstream-healthcheck
[2].https://github.com/openresty/lua-upstream-nginx-module#set_peer_down
更多相关:
-
最近从 kvell 这篇论文中看到一些单机存储引擎的优秀设计,底层存储硬件性能在不远的未来可能不再是主要的性能瓶颈,反而高并发下的CPU可能是软件性能的主要限制。像BPS/AEP/Optane-SSD 等Intel 推出的硬件存储栈已经能够在延时上接近DRAM的量级,吞吐在较低的队列深度下更是能够超越当前主流NVMe-ssd 数倍甚至...
-
关于如何在有噪声的数据中进行状态估计的问题的理解,状态估计的问题是指在运动和观测方程中,通常假设两个噪声ωiomega_i和υk,jupsilon_{k,j}满足零均值的高斯分布, xk=f(xk−1,uk)+ωkx_k=f(x_{k-1},u_k)+omega_k其中ωk→N(0,Rk)omega_k ightarro...
-
强化学习(英语:Reinforcement learning,简称RL)是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。这个方法具有普适性,因此在其他许多领域都有研究,例如博弈...
-
文章目录PG 的状态机和peering过程1. PG 状态机变化的时机2. pg的状态演化过程3. pg状态变化实例讲解3.1 pg状态的管理结构3.2 数据的pg状态变化过程3.2.1 NULL -> initial3.2.2 initial -> reset -> Started3.2.3 Started(start) ->St...
-
什么是状态模式? 定义:将事物内部的每个状态分别封装成类,内部状态改变会产生不同行为。 主要解决:对象的行为依赖于它的状态(属性),并且可以根据它的状态改变而改变它的相关行为。 何时使用:代码中包含大量与对象状态有关的条件语句。 如何解决:将各种具体的状态类抽象出来。 应用实例: 1、打篮球的时候运动员可以有正常状态、不正常状态和超...
-
别小看这个功能, 感觉在写一些技术 Blog 的情况下还是挺有用的. 打开QQ拼音: 输入法设置->基本设置->初始状态->中文状态下使用英文标点. 转载于:https://www.cnblogs.com/qrlozte/p/4904087.html...