ceph bluestore源码分析:非对齐写逻辑
文章目录
- 环境
- 原理说明
- 总结
环境
ceph:12.2.1
场景:ec 2+1
部署cephfs,执行如右写模式:dd if=/dev/zero of=/xxx/cephfs bs=6K count=4 oflag=direct
关键配置:
bluestore_min_alloc_size_hdd = 65536 bluestore分配空间的最小粒度 单位:B
bdev_block_size = 4096 磁盘分配空间的最小粒度 单位:B
原理说明
以上dd写方式总共直写四次6K大小的io,每一个io在经过PG落到bluestore层次会根据分片大小2副本+1校验块 被拆分为3K大小的 io到每个osd上
-
第一次写3K io 由于未chuck(bdev_size 4K )对齐,则对3K io补零后和bdev_size对齐,然后写入bluestore按照bluestore_min_alloc_size_hdd大小分配的blob中

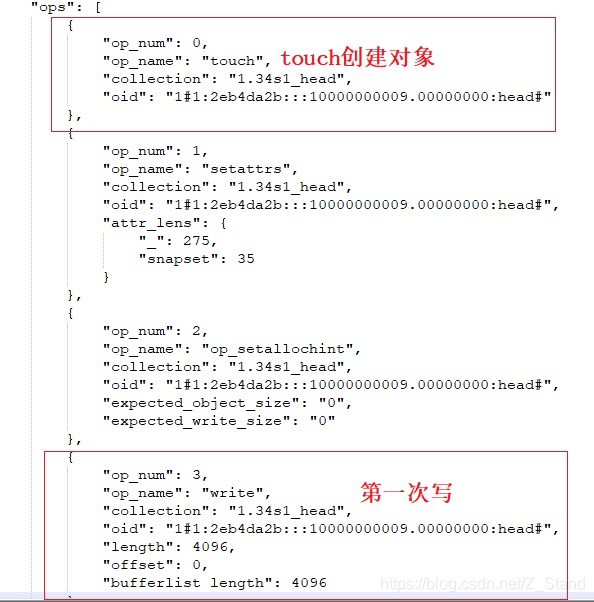
bluestore.cc :_txc_add_transaction–> _write --> _do_write–>_do_write_data --> _do_write_small
直接写入一个新的blob中
_do_alloc_write txc 0x7fcb6e6443c0 1 blobs

-
第二次写3K io主要执行如下步骤:
a. 会先进行clone blob1
b. 使用前1K 数据补齐blob1中的lextent1,再重新分配一个blob,写入补齐后的lextent3
c. 剩下的2K io用0补齐后写入新的lextent4
d. 移除lextent1对临时onode的引用,remove临时onde,进而释放lextent1对blob1的引用,进而释放blob1回收磁盘空间a. 执行clone
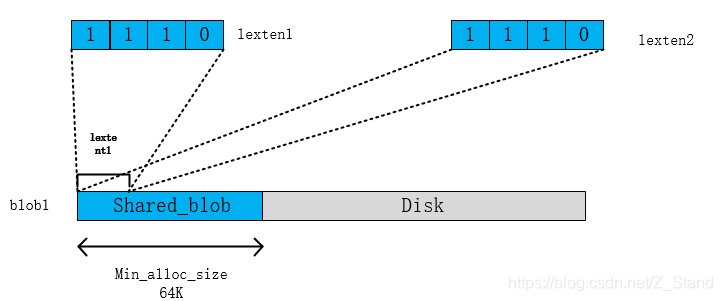
这里clone是为当前extent创建一个单独的onode,即一个新的对象 空间来存储,所以这里可以看到offset从0开始分配
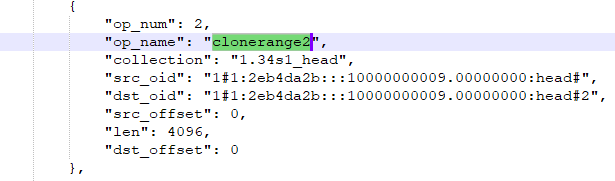
这里在执行clone的时候根据bluestore配置参数bluestore_clone_cow来判断是否执行cow机制:即当前io补齐上一个extent之后,为其重新分配一个blob并写入。RMW:需要有额外的写,即先读出当前blob的extent数据,使用第二次io的前1K补齐改blob,再写入当前blob空间。bluestore为了提升性能,减少小写次数,这里默认使用了cow机制。
bluestore.cc :_txc_add_transaction–> _clone --> _do_clone

b. 此时blob1即被两个逻辑段lexten共享,则blob1成为sharedblob
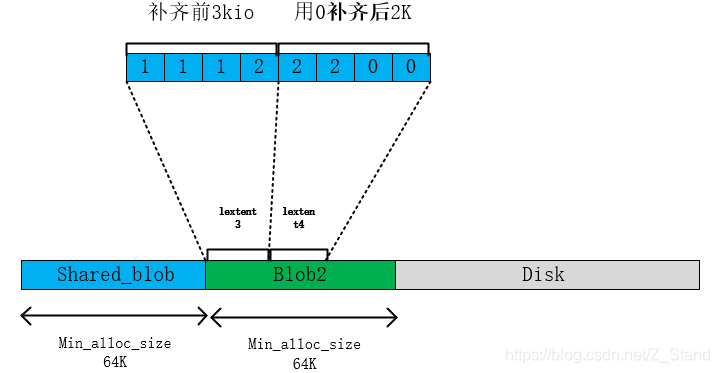
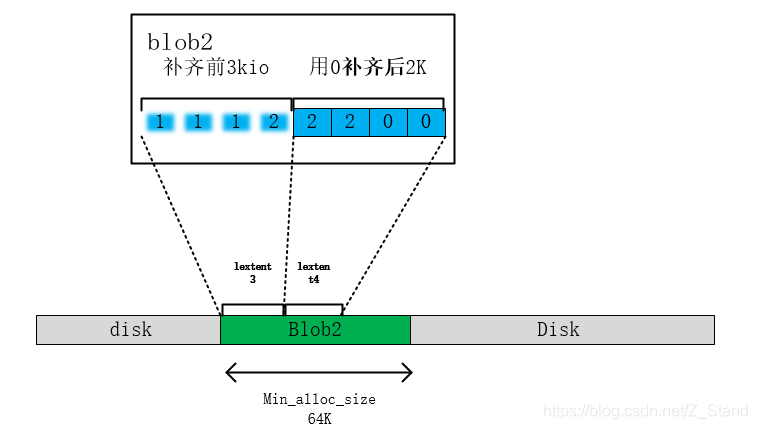
接下来使用1K数据补齐lextent1的3K,同时使用0补齐当前剩余2K,补齐后的数据如下
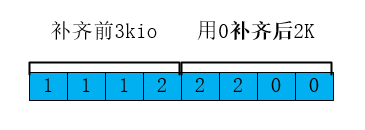
c. 将补齐后的第一个4K IO写入到lextent3中,第二次io剩余的数据写入到lextent4中
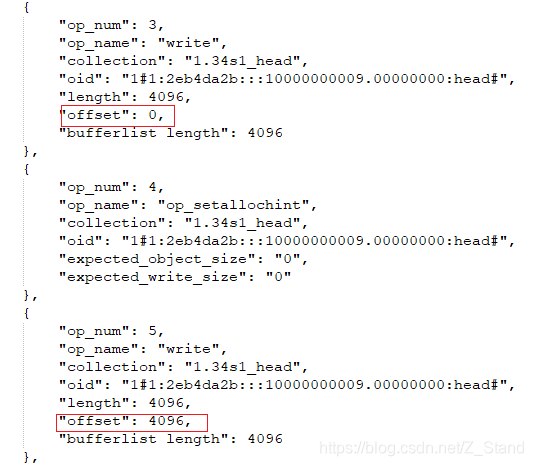
可以看到这里进行了两次写,第一次是写clone之后补齐的数据,第二次写剩余用0补齐的数据。因为第一次写是重新分配了blob,所以offset 为0,第二次写是紧接着第一次的写,所以这里offset为4096
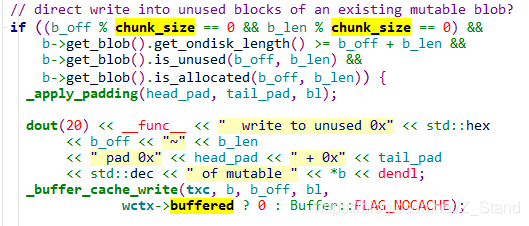
补齐后的第一次写 ,执行小写,分配了一个新的blob
bluestore.cc :_txc_add_transaction–> _write --> _do_write–>_do_write_data --> _do_write_small
第二次写为直接写入blob中未使用的块
bluestore.cc :_txc_add_transaction–> _write --> _do_write–>_do_write_data --> _do_write_small
写完之后的blob和extent引用关系如下

d. 此时释放lextent1对blob1的引用如下:
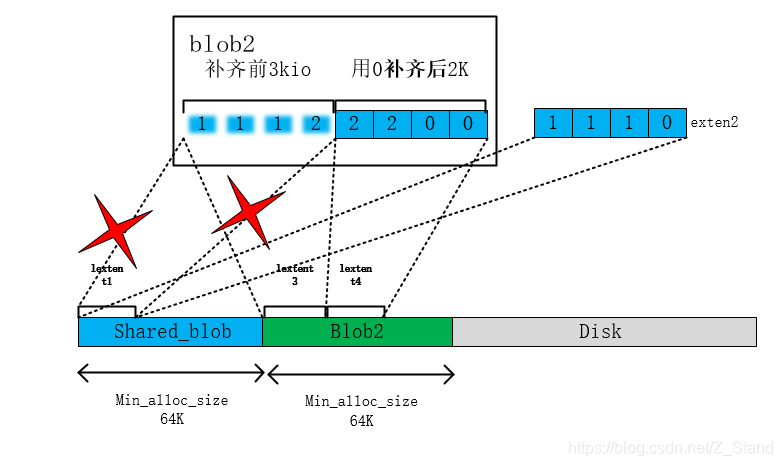
垃圾回收,进而释放lextent1
bluestore.cc :_txc_add_transaction–> _write --> _do_write

_txc_add_transaction–> _write --> _do_write --> _wctx_finish
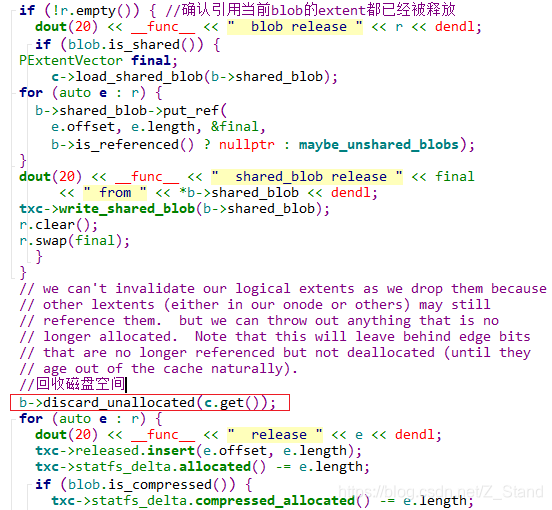
释放blob1中lexten1对blob1的引用
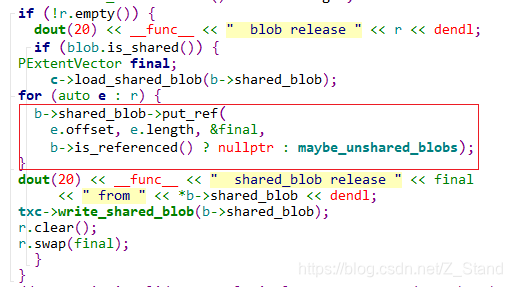
同时remove临时onode(clone后的extent2所在的内存元数据结构),并释放blob1的空间.最终第二个3k io写完效果如下
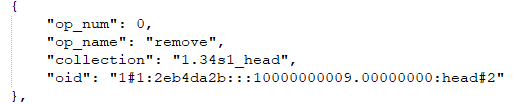
_txc_add_transaction–> _remove --> _do_remove -->
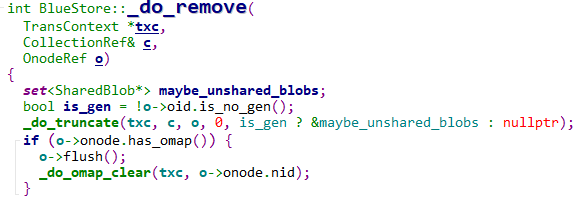
回收磁盘空间 _txc_add_transaction–> _remove --> _do_remove --> _do_truncate --> _wctx_finish
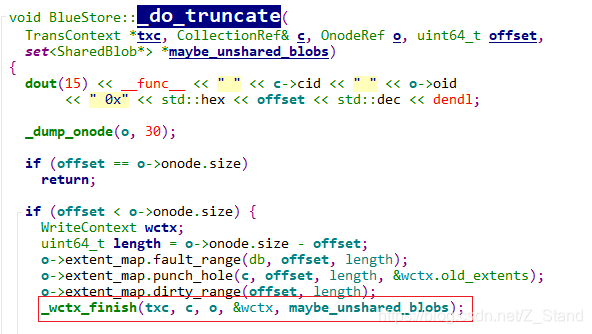
_txc_add_transaction–> _remove --> _do_remove --> _do_truncate --> _wctx_finish
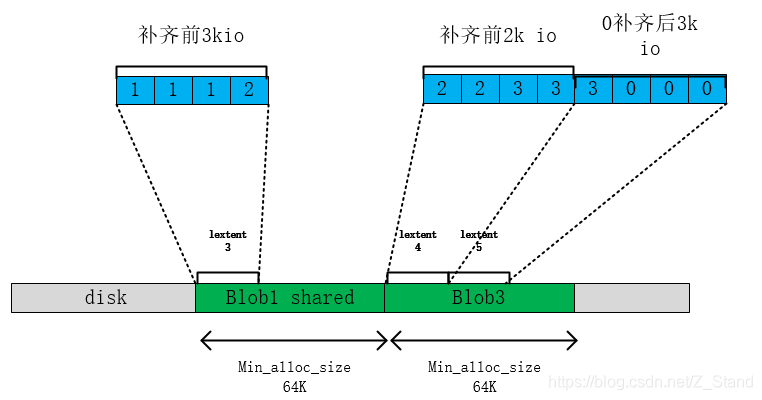
第三次写 3K io同样会进行一次clone,不过clone完成之后的补齐上一次io的写lextent4和新的补零写lextent5之后blob2成为sharedblob,但是由于shareblob仍然再被lextent3引用,所以此时无法remove blob2
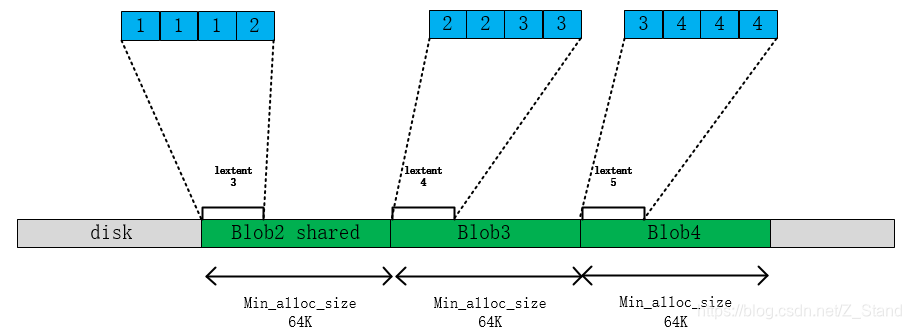
第四次写3k io,同上最后的映射关系如下
源码调用栈如下,本调用栈只打到了_do_write_small这一层,具体如何向源码加入函数调用栈可以参考ceph bluestore源码梳理:C++ 获取线程id:
ceph-osd(BlueStore::_do_write_small(BlueStore::TransContext*,
ceph-osd(BlueStore::_do_write(BlueStore::TransContext*,
ceph-osd(BlueStore::_write(BlueStore::TransContext*,
ceph-osd(BlueStore::_txc_add_transaction(BlueStore::TransContext*,
ceph-osd(BlueStore::queue_transactions(ObjectStore::Sequencer*,
ceph-osd(PrimaryLogPG::queue_transactions(std::vector<ObjectStore::Transaction,
ceph-osd(ECBackend::handle_sub_write(pg_shard_t, boost::intrusive_ptr<OpRequest>,
ceph-osd(ECBackend::_handle_message(boost::intrusive_ptr<OpRequest>)+0x327)
ceph-osd(PGBackend::handle_message(boost::intrusive_ptr<OpRequest>)+0x50)
ceph-osd(PrimaryLogPG::do_request(boost::intrusive_ptr<OpRequest>&,
ceph-osd(OSD::dequeue_op(boost::intrusive_ptr<PG>, boost::intrusive_ptr<OpRequest>,
ceph-osd(PGQueueable::RunVis::operator()(boost::intrusive_ptr<OpRequest> const&)+0x57)
ceph-osd(OSD::ShardedOpWQ::_process(unsigned int, ceph::heartbeat_handle_d*)
ceph-osd(ShardedThreadPool::shardedthreadpool_worker(unsigned int)+0x839)
总结
综上,我们可以看到bluestore在非对齐写4个io时会进行3次clone,总共执行6次do_write_small方式的小写。这里是因为clone时使用了cow机制,然而我们使用RMW时会额外增加一次写。可以参考_clone函数中的逻辑。所以按照如上测试方式,每经过4次io,bluestore会进行9次的小写。这里bluestore为了性能稳定,牺牲磁盘空间来将cow机制作为默认的非对齐写处理方式。
更多相关:
-
文章目录先看看性能AIO 的基本实现io_ring 使用io_uring 基本接口liburing 的使用io_uring 非poll 模式下 的实现io_uring poll模式下的实现io_uring 在 rocksdb 中的应用总结参考...
-
文章目录用户空间IO缓冲区产生IO缓冲区 描述IO缓冲区的写模式自定义IO缓冲区 用户空间IO缓冲区产生 系统调用过程中会产生的开销如下: 切换CPU到内核态进行数据内容的拷贝,从用户态到内核态或者从内核态到用户态切换CPU到用户态 以上为普通到系统调用过程中操作系统需要产生的额外开销,为了提升系统调用的性能,这里推出用...