五、锁与事务隔离级别
事务隔离级别简单的说,就是当激活事务时,控制事务内因SQL语句产生的锁定需要保留多入,影响范围多大,以防止多人访问时,在事务内发生数据查询的错误。设置事务隔离级别将影响整条连接。
SQL Server 数据库引擎支持所有这些隔离级别:
· 未提交读(隔离事务的最低级别,只能保证不读取物理上损坏的数据)
· 已提交读(数据库引擎的默认级别)
· 可重复读
· 可序列化(隔离事务的最高级别,事务之间完全隔离)
SQL Server 还支持使用行版本控制的两个事务隔离级别。一个是已提交读隔离的新实现,另一个是新事务隔离级别(快照)。
设置语句如下:
| SET TRANSACTION ISOLATION LEVEL { READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SNAPSHOT | SERIALIZABLE } [ ; ] |
(一)未提交读
未提交读是最低的事务隔离级别,允许读取其他事务已经修改但未提交的数据行。SQL SERVER 当此事务等级进行尝试读取数据时,不会放置共享锁,直接读取数据,所以忽略已存在的互斥锁。换句话说,即使该资源已经受到了独占锁的保护,当使用未提交读隔离级别时,此数据还是可以被读取,加快查询速度,但是会读取到别人未修改的数据,所以此种读取被称为脏读。此种隔离级别适合不在乎数据变更的查询场景。此隔离级别与SELECT 语句搭配 NOLOCK 所起到的效果相同
未提交读示例:
--1.--1.创建测试表
create table tbUnRead
(ID INT,
name nvarchar(20)
)
--2新增记录
insert tbUnRead
select 1,'Tom'
union
select 2,'Jack'
--3开启事务,并进行更新
begin tran
update tbUnRead
set name='Jack_upd'
where ID=2
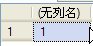
---4查询事务数量(由于没有回滚或提交事务)
SELECT @@TRANCOUNT
事务查询结果如下:
--5打开另一条连接,设置事务隔离级别为(未提交读)
set Transaction isolation level read uncommitted
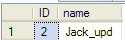
--6查询数据,查询到的数据是修改之后的数据。
select * from tbUnRead where ID=2
如下图:
(二)已提交读
已提交读是SQL SERVER 默认的事务隔离级别。当事务正在读取数据时,SQL SERVER 会放置共享锁以防止其他事务修改数据,当数据读取完成之后,会自动释放共享锁,其他事务可以进行数据修改。因为共享锁会同时封锁封锁语句执行,所以在事务完成数据修改之前,是无法读取该事务正在修改的数据行。因此此隔离级别可以防止脏读。
在SQL SERVER 2005以上版本中,如果设置READ_COMMITTED_SNAPSHOT为ON,则已提交读的事务全使用数据行版本控制的隔离下读取数据。读取操作不会获取正被读取的数据上的共享锁(S 锁),因此不会阻塞正在修改数据的事务。同时,由于减少了所获取的锁的数量,因此最大程度地降低了锁定资源的开销。使用行版本控制的已提交读隔离和快照隔离旨在提供副本数据的语句级或事务级读取一致性。
示例一:设置READ_COMMITTED_SNAPSHOT为OFF
--1.创建测试表
create table tbUnRead
(ID INT,
name nvarchar(20)
)
--2新增记录
insert tbUnRead
select 1,'Tom'
union
select 2,'Jack'
--3开启事务,并进行更新
begin tran
update tbUnRead
set name='Jack_upd'
where ID=2
---4查询事务数量(由于没有回滚或提交事务)
SELECT @@TRANCOUNT
--5打开另一条连接,设置事务隔离级别为(已提交读)
set Transaction isolation level read committed
--6查询数据,由于当前事务没有提交,所以无法查询数据
select * from tbUnRead where ID=2
6查询数据的结果 如下图:
示例二:设置READ_COMMITTED_SNAPSHOT为ON
use master
go
---创建测试数据库
create database read_committed_SNAPSHOT_Test
go
---激活数据行版本控制
alter database read_committed_SNAPSHOT_Test set read_committed_SNAPSHOT on
go
use read_committed_SNAPSHOT_Test
go
--1.创建测试表
create table tbReadLevel
(ID INT,
name nvarchar(20)
)
--2新增记录
insert tbReadLevel
select 1,'测试'
go
select ID,name as "修改前数据" from tbReadLevel
如下图:
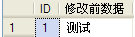
go
--3开启事务,并进行更新
begin tran
update tbReadLevel
set name='Jack_upd'
where ID=1
---4查询事务数量(由于没有回滚或提交事务)
SELECT @@TRANCOUNT
--5打开另一条连接,设置事务隔离级别为(已提交读)
--查询数据,查询到的数据是上一次提交的数据
select * from tbReadLevel where ID=1
5的查询结果如下图:
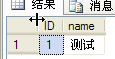
(三)可重复读
可重复读事务隔离级别在事务过程中,所有的共享锁均保留到事务结束,而不是读取结束就释放,这与已提交读的行为截然不同,虽然在事务过程中,重复查询相同记录时不受其他事务的影响,但可能由于锁定数据过久,而导致其他人无法处理数据,影响并发率,更严重的可能提高发生死锁的机率。
总之,如果使用可重复读隔离级别读取数据,数据读出之后,其他事务只能对此范围中的数据进行读取或新增,但不可以进行修改,直到读取事务完成。因此,使用此隔离级别需要谨慎小心,根据实际情况进行设置。
示例:
--1.创建测试表
create table tbUnRead
(ID INT,
name nvarchar(20)
)
--2新增记录
insert tbUnRead
select 1,'Tom'
union
select 2,'Jack'
--3设置事务隔离级别为(可重复读)
set Transaction isolation level REPEATABLE READ
--4开启事务,并进行更新
begin tran
--5查询数据
select * from tbUnRead where ID=2
---6查询事务数量(没有回滚或提交事务)
SELECT @@TRANCOUNT
5与6的执行结果如下图
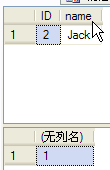
---7开启另一条连接,查询数据与修改数据
---事务虽然没有完成,但可以查询到之前的数据
select * from tbUnRead where ID=2
Go
---8,修改数据,由于事务没有完成,所以无法进行修改
update tbUnRead
set name='Jack_upd'
where ID=2
go
--7、8的执行结果如下,可以查询数据,但无法更新数据,如下图。
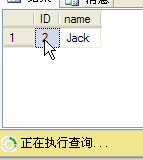
(四)快照
快照隔离级别是SQL SERVER 2005之后版本新增的隔离级别,开启之后,允许事务过程中读取操作不受异动影响,事务中任一语句所读取的数据,均予事务激活时,就已经完成提交,符合事务一致性的数据行版本。所以只能查核事务激活之前已经完成提交的数据,也就是说可以查询已经完成提交的数据行快照集,但看不见已激活的事务正在进行修改的数据行。当使用快照隔离级别读取数据时不会要求对数据进行锁定,如果所读取的记录正在被某事务进行修改,它也会读取此记录之前已经提交的数据。故当某记录被事务进行修改时,SQL SERVER的TEMPDB数据库会存储最近提交的数据行,以供快照隔离级别的事务读取数据时使用。将Allow_SNAPSHOT_isolation设为ON,事务就会设置快照隔离级别。
use master
go
---创建测试数据库(快照)
create database SNAPSHOT_Test
go
---激活数据行版本控制
alter database SNAPSHOT_Test set Allow_SNAPSHOT_isolation on
go
use SNAPSHOT_Test
go
--1.创建测试表
create table tbReadLevel
(ID INT,
name nvarchar(20)
)
--2新增记录
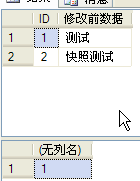
insert tbReadLevel
select 1,'测试'
union
select 2,'快照测试'
go
select ID,name as "修改前数据"
from tbReadLevel
go
--3开启事务,并进行更新
begin tran
update tbReadLevel
set name='Jack_upd_快照'
where ID=1
---4查询事务数量(没有回滚或提交事务)
SELECT @@TRANCOUNT
--2、4的执行结果,如下图。
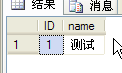
--5打开另一条连接,设置事务隔离级别为(快照)
set Transaction isolation level SNAPSHOT
--6查询数据,查询的数据是上一次提交的数据
select * from tbReadLevel where ID=1
(五)可序列化
可序列化是事务隔离级别中最高的级别,为最严谨的隔离级别,因为它会锁定整个范围的索引键,使事务与其他事务完全隔离。在现行事务完成之前,其他事务不能插入新的数据行,其索引键值存在于现行事务所读取的索引键范围之中。此隔离级别与Select 搭配holdlock效果一样。
示例:
--1.创建测试表
create table tbUnRead
(ID INT,
name nvarchar(20)
)
--2新增记录
insert tbUnRead
select 1,'Tom'
union
select 2,'Jack'
--3设置事务隔离级别为(可序列化)
set Transaction isolation level SERIALIZABLE
--5开启事务,并进行更新
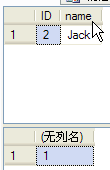
begin tran
select * from tbUnRead where ID=2
---6查询事务数量(没有回滚或提交事务)
SELECT @@TRANCOUNT
5、6执行结果如下图。
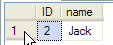
---7,开启另一条连接,查询数据,可以查询到之前的数据
select * from tbUnRead where ID=2
---8,修改数据,无法修改数据
update tbUnRead
set name='Jack_upd'
where ID=2
--新增数据,无法插入数据
insert tbUnRead
select 3,'May'