关于Titandb Ratelimiter 失效问题的一个bugfix
本文简单讨论一下在TitanDB 中使用Ratelimiter的一个bug,也算是一个重要bug了,相关fix已经提了PR到tikv 社区了pull-210。
这个问题导致的现象是ratelimiter 在titandb Flush/GC 生成blobfiled的过程中无法生效,也就是无法限制titandb的主要写 I/O。而我们想要享受Titandb在大value的写放大红利,却会引入巨量的写带宽(GC),这个时候对于大多数读敏感的场景 titandb GC出现时就是一场长尾灾难。
而ratelimiter则是这个场景的救星,它能够有效控制磁盘写入,降低了大量排队的写请求对读的影响。我们现在使用的非Intel Optane系列的ssd/NVM等设备,请求在磁盘内部其实都是顺序处理,也就是写请求多了,后续跟着的读请求延时必然会上涨。这个时候,我们能够有效控制磁盘的写入带宽,再加上titandb的GC并非持续性的波峰,而是间断性得调度,这样我们通过ratelimiter做一个均衡的限速,将GC出现时的磁盘I/O波峰打平到一段时间内处理完成,这样我们的读请求延时就很棒了。
然而,事与愿违,titan的ratelimiter有一些细节上的bug。
使用如下测试脚本:
./titandb_bench --benchmarks="fillrandom,stats" --max_background_compactions=32 --max_background_flushes=4 --max_write_buffer_number=6 --target_file_size_base=67108864 --max_bytes_for_level_base=536870912 --statistics=true --stats_dump_period_sec=5 --num=5000000 --duration=300 --threads=10 --value_size=8192 --key_size=16 --key_id_range=10000000 --enable_pipelined_write=false --db=./db_bench_test --wal_dir=./db_bench_test --num_multi_db=1 --allow_concurrent_memtable_write=true --disable_wal=true # 写入的过程中磁盘带宽仅由flush/GC产生--use_titan=true # 使用titandb--titan_max_background_gc=2 --rate_limiter_bytes_per_sec=134217728 # 开启ratelimiter,限速到128M--rate_limiter_auto_tuned=false
测试1:
测试rocksdb的ratelimiter是否生效 ,将--use_titan=false
能够看到磁盘写I/O行为非常稳定得被限制到128M左右: 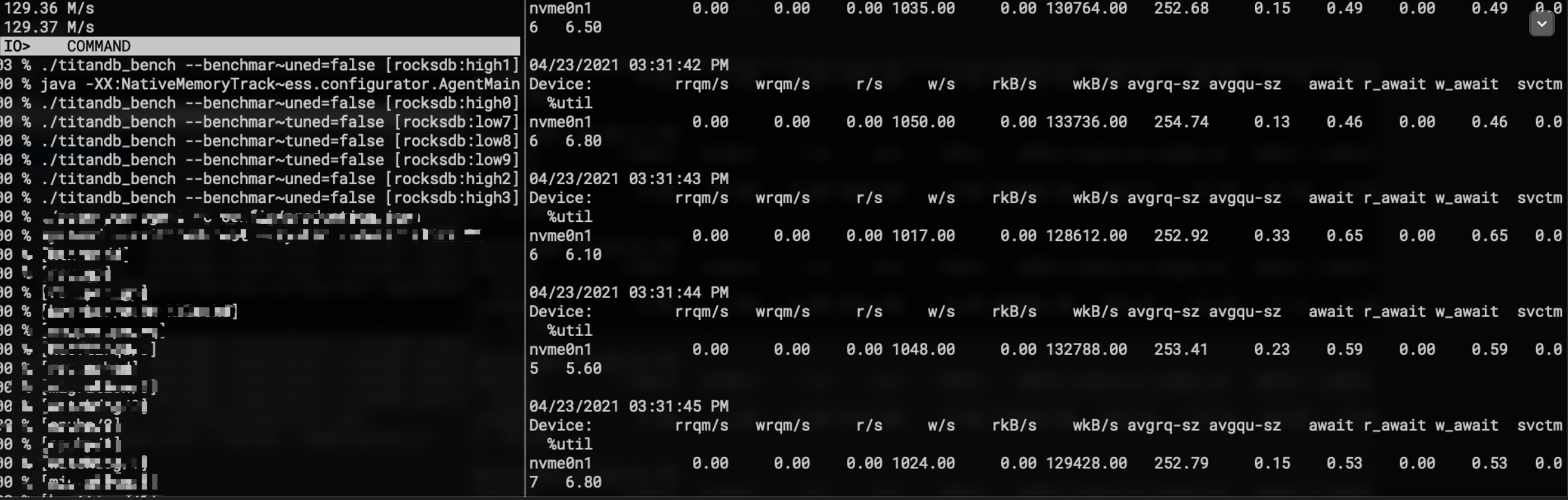
测试2:
测试titan的ratelimiter是否生效,将--use_titan=true直接打开
可以看到此时IO完全无法有效控制住,I/O线程有high和user线程池,也就是titandb的flush和GC
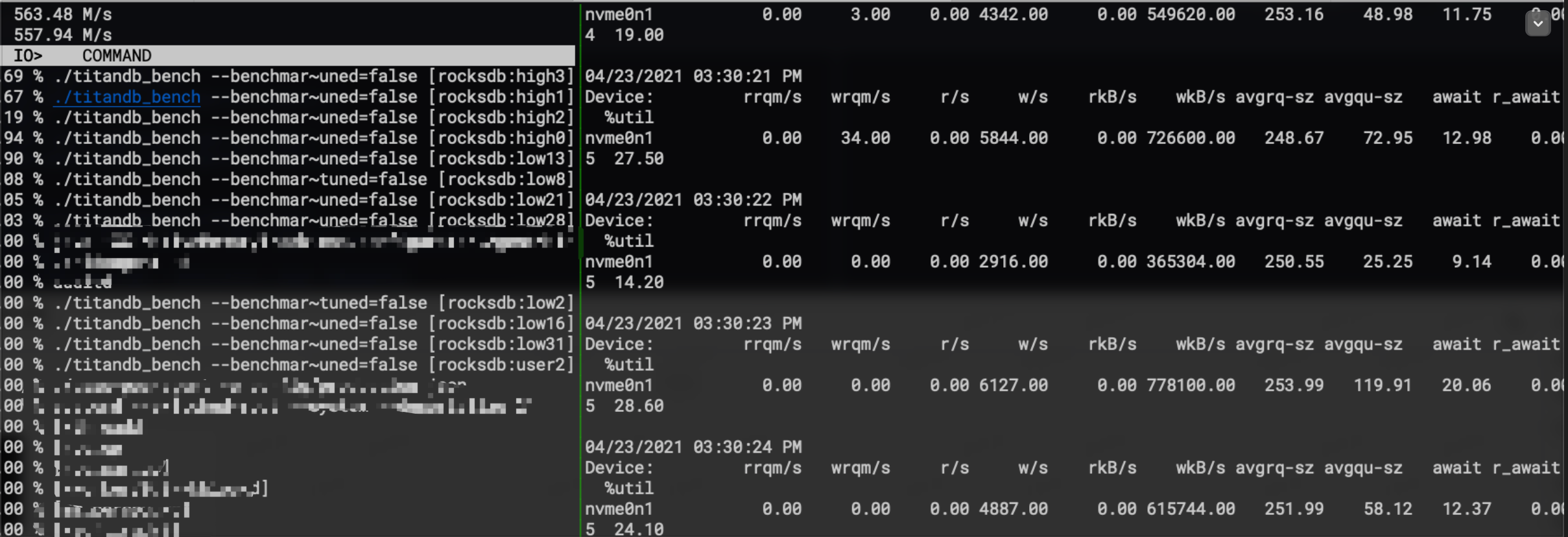
发现了问题,接下来看看问题原因:
我们上层传入了ratelimiter,而ratelimiter的调度则在数据写入具体文件之前调度的,titan这里复用了rocksdb的ratelimiter,也就是ratelimiter的调度最终都会通过同一个入口WritableFileWriter::Append函数。
Titan这里到达这个入口的途径就是在Flush/GC 创建Blobfile的时候进入的。
void BlobFileBuilder::Add(const BlobRecord& record, BlobHandle* handle) { if (!ok()) return;encoder_.EncodeRecord(record);handle->offset = file_->GetFileSize();handle->size = encoder_.GetEncodedSize();live_data_size_ += handle->size;// 写blobfilestatus_ = file_->Append(encoder_.GetHeader());if (ok()) { status_ = file_->Append(encoder_.GetRecord());num_entries_++;// The keys added into blob files are in order.if (smallest_key_.empty()) { smallest_key_.assign(record.key.data(), record.key.size());}assert(cf_options_.comparator->Compare(record.key, Slice(smallest_key_)) >=0);assert(cf_options_.comparator->Compare(record.key, Slice(largest_key_)) >=0);largest_key_.assign(record.key.data(), record.key.size());}
}
我们通过systemtap确认一下titandb这里的ratelimiter指针是否为空, 如果为空,那问题就不在writablefile那里了。
!#/bin/stapglobal timesprobe process("/home/test_binary").function("rocksdb::titandb::BlobFileBuilder::Add").call { printf("rate_limiter addr : %x
", $file_->ratelimiter_$)
}
发现有地址,且和LOG文件中打出的rate_limiter地址一样,说明ratelimiter确实是下发到了底层文件写入这里。
那就继续深入呗,看看是否执行到了ratelimiter逻辑里面。
这里被titan写的单测误导了很久
blob_gc_job_test.cc,他们自己实现了一个ratelimiter的RequestToken,乍一看和rocksdb的RequestToken很像,但少了一个条件,一般人还看不出来:size_t RequestToken(size_t bytes, size_t alignment,Env::IOPriority io_priority, Statistics* stats,RateLimiter::OpType op_type) override { // 少了一个对io_priority 的判断if (IsRateLimited(op_type)) { if (op_type == RateLimiter::OpType::kRead) { read = true;} else { write = true;}}return bytes; }
因为这个单测除了少了一个判断之外,其他逻辑都没有问题,结果老是认为问题出在了RequestToken上某一个函数里,可能是从Append到RequestToken之间的某一个逻辑没有进入到,也就是无法进入到实际的RequestToken里面。
然而抓遍了中间部分函数的调用栈,人正常的逻辑,,,没有丝毫问题,通过Append进入之后需要不断填充一个buffer,当这个buffer达到1M之后(可以通过参数writable_file_max_buffer_size配置)会调用一次WritableFileWriter::Flush,没有direct_io的配置的话这里面必然会进入到WriteBufferred函数中,和rocksdb的逻辑一毛一样。。。wtf
万般无奈,只能回到RequestToken逻辑中了,stap打印了一下进入函数之后的各个参数的值。。。发现io_priority为啥大多数是2,偶尔是0/1。。。而rocksdb都是0/1,显然2肯定是无法进入到实际的Request逻辑的,被屏蔽在了外面。
如下是rocksdb的令牌桶限速入口:
size_t RateLimiter::RequestToken(size_t bytes, size_t alignment,Env::IOPriority io_priority, Statistics* stats,RateLimiter::OpType op_type) { // 必须保证io_priority < 2才能实际进入到 Request逻辑if (io_priority < Env::IO_TOTAL && IsRateLimited(op_type)) { bytes = std::min(bytes, static_cast<size_t>(GetSingleBurstBytes()));if (alignment > 0) { // Here we may actually require more than burst and block// but we can not write less than one page at a time on direct I/O// thus we may want not to use ratelimiterbytes = std::max(alignment, TruncateToPageBoundary(alignment, bytes));}Request(bytes, io_priority, stats, op_type);}return bytes;
}
问题显然出现在了io_priority这里,然后大概看了一下什么时候会对io_priority进行赋值。
它描述的是一个文件被ratelimiter拿到的时候该以什么样的优先级处理,如果设置的是高优先级IO_HIGH,则ratelimiter会优先满足这个文件的写入,不会限速得太狠;如果是IO_LOW则会尽可能得对它进行限速;而IO_HIGH则是文件创建时的默认优先级, 不会进行任何限速。
WritableFile(): last_preallocated_block_(0),preallocation_block_size_(0),io_priority_(Env::IO_TOTAL),write_hint_(Env::WLTH_NOT_SET),strict_bytes_per_sync_(false) { }
所以,rocksdb实际会在compaction/Flush 创建sst文件的时候对他们进行各自的优先级赋值,保证能够被限速。
逻辑分别在WriteL0Table–>BuildTable 和 OpenCompactionOutputFile–>writable_file->SetIOPriority(Env::IO_LOW)中,然而我们在titan中的主体IO在blobfile的写入上,也就是创建Blobfile 的handle之后需要对blobfile的io_priority进行设置,才能保证ratelimiter能够拿到有效的I/O优先级。
看一下titan的FileManager::NewFile的逻辑:
Status NewFile(std::unique_ptr<BlobFileHandle>* handle) override { auto number = db_->blob_file_set_->NewFileNumber();auto name = BlobFileName(db_->dirname_, number);Status s;std::unique_ptr<WritableFileWriter> file;{ std::unique_ptr<WritableFile> f;s = db_->env_->NewWritableFile(name, &f, db_->env_options_);if (!s.ok()) return s;file.reset(new WritableFileWriter(std::move(f), name, db_->env_options_));}handle->reset(new FileHandle(number, name, std::move(file)));{ MutexLock l(&db_->mutex_);db_->pending_outputs_.insert(number);}return s;}
到这里基本就清楚问题的原因了,显然titan创建blobfile并没有添加有效的io_priority,而且ratelimiter的单测写的不够严谨导致误导了很多人。
修复的话可以之间看这个pull-210 就可以了。
更多相关:
-
1. 定义网络的基本参数 定义输入网络的是什么: input = Input(shape=(240, 640, 3)) 反向传播时梯度下降算法 SGD一定会收敛,但是速度慢 Adam速度快但是可能不收敛 [link](https://blog.csdn.net/wydbyxr/article/details/84822806...
-
size_t和int size_t是一些C/C++标准在stddef.h中定义的。这个类型足以用来表示对象的大小。size_t的真实类型与操作系统有关。 在32位架构中被普遍定义为: typedef unsigned int size_t; 而在64位架构中被定义为: typedef unsigned lo...
-
我在 https://blog.csdn.net/wowricky/article/details/83218126 介绍了一种内存池,它的实现类似于linux 中打开slub_debug (1. make menuconfig: Kenel hacking -> Memory Debugging, 2. comand line中传入...
-
项目开发中需要从引擎 获取一定范围的数据大小,用作打点上报,测试过程中竟然发现写入了一部分数据之后通过GetApproximateSizes 获取写入的key的范围时取出来的数据大小竟然为0。。。难道发现了一个bug?(欣喜) 因为写入的数据是小于一个sst的data-block(默认是4K),会不会因为GetApproximate...
-
文章目录先看看性能AIO 的基本实现io_ring 使用io_uring 基本接口liburing 的使用io_uring 非poll 模式下 的实现io_uring poll模式下的实现io_uring 在 rocksdb 中的应用总结参考...
-
文章目录用户空间IO缓冲区产生IO缓冲区 描述IO缓冲区的写模式自定义IO缓冲区 用户空间IO缓冲区产生 系统调用过程中会产生的开销如下: 切换CPU到内核态进行数据内容的拷贝,从用户态到内核态或者从内核态到用户态切换CPU到用户态 以上为普通到系统调用过程中操作系统需要产生的额外开销,为了提升系统调用的性能,这里推出用...