shell --- awk规范 系统总结
文章目录
- awk和sed的区别
- awk脚本的流程控制
- awk 记录和字段
- 字段的引用
- awk表达式
- 赋值操作符
- 算数操作符
- 系统变量(awk本身自定义的系统变量)
- 关系操作符
- 布尔操作符
- awk 条件和循环
- 条件语句
- 循环
- awk 的数组
- 数组的定义
- 数组的遍历
- 删除数组
- 举例,编写awk脚本文件`avg.awk`
- 命令行参数数组
- 复杂数组的使用案例
- awk函数
- 算数函数
- 字符串函数
- 自定义函数
awk和sed的区别
- awk更像是脚本语言
- awk用于“比较规范”的文本处理,用于统计数量并输出指定字段
- 使用sed 将不规范的文本,处理为“比较规范的文本”
awk脚本的流程控制
- 输入数据前 例程 BEGIN{},相当于预处理,进行变量定义
- 主输入循环{} ,一般只写主输入循环
- 所有文件读取完成 例程END{}
awk 记录和字段
- 每一行称为 akw记录
- 使用空格、制表符分隔开的单词称为字段
- 可以自己指定分隔的字段
字段的引用
-
awk中使用$1,$2,$3…$n表示每隔字段
awk '{print $1,$2,$3}' filename -
awk 可以使用-F选项改变字段分隔符
awk -F, '{print $1, $2, $3}' filename
分隔符可以使用正则表达式
使用单引号作为分隔符,读取以menu开头的字段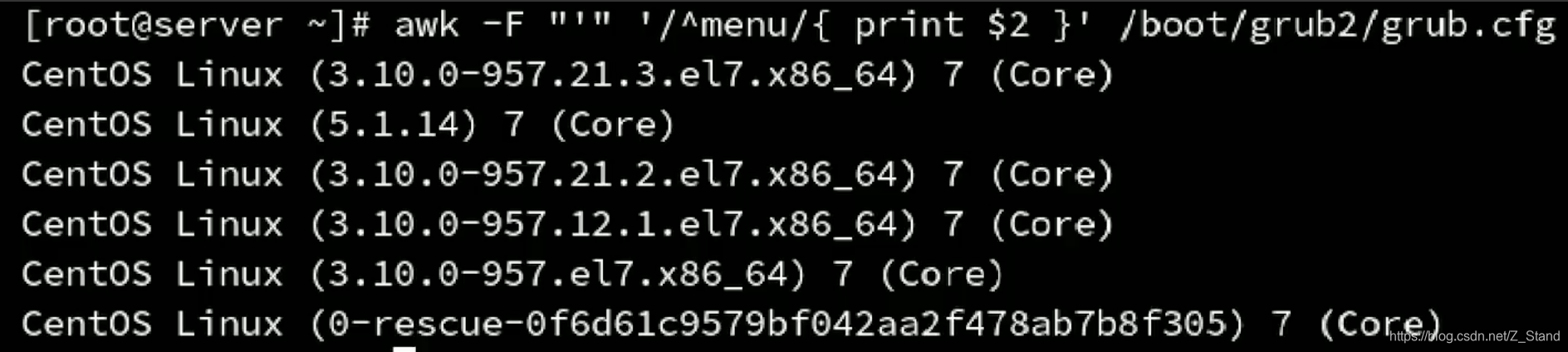
使用x++,可以打印行号

awk表达式
赋值操作符
=最常使用的操作符(等号前后可以增加空格)var1 = "name"var2 = "hello" "world"赋值多个运算符var3 = $1
- 其他赋值运算符
++ , -- , +=, -=, *=, /=, %=, ^=
算数操作符
+, -, *, /, %, ^
系统变量(awk本身自定义的系统变量)
-
FS和OFS系统变量,OFS表示输出的字段分隔符
awk读取每一行的内容之前,都会先读取FS和OFS表示的分隔符,输入时进行字段的提取,输出时根据OFS增加分隔符
举例如下:
head -5 /etc/passwd | awk -F ":" '{print $1}'
使用-F来分隔就等价于
head -5 /etc/passwd | awk 'BEGIN{FS=":"}{print $1}',通过BEGIN读入之前,设置好字段分隔符。
增加OFS输出字段分隔符

-
RS记录分隔符,行之间的合并
将每一行的记录分隔符:,则每当遇到:,即代表一行
head -5 /etc/passwd | awk 'BEGIN{RS=":"}{print $0}' -
NR和FNR行数
当输入为多个文件时,FNR可以重排多个文件,FR则都按照一个文件的行号排列

-
NF字段数量,最后一个字段内容可以用$NF取出字段内容
head -5 /etc/passwd | awk 'BEGIN{FS=":"}{print NF}',输出每一行的字段个数
head -5 /etc/passwd | awk 'BEGIN{FS=":"}{print $NF}',输出最后一个字段的内容
关系操作符
<, >, <=, >=, ==, !=, ~, !~
布尔操作符
&&, ||, !
awk 条件和循环
条件语句
- 条件语句使用
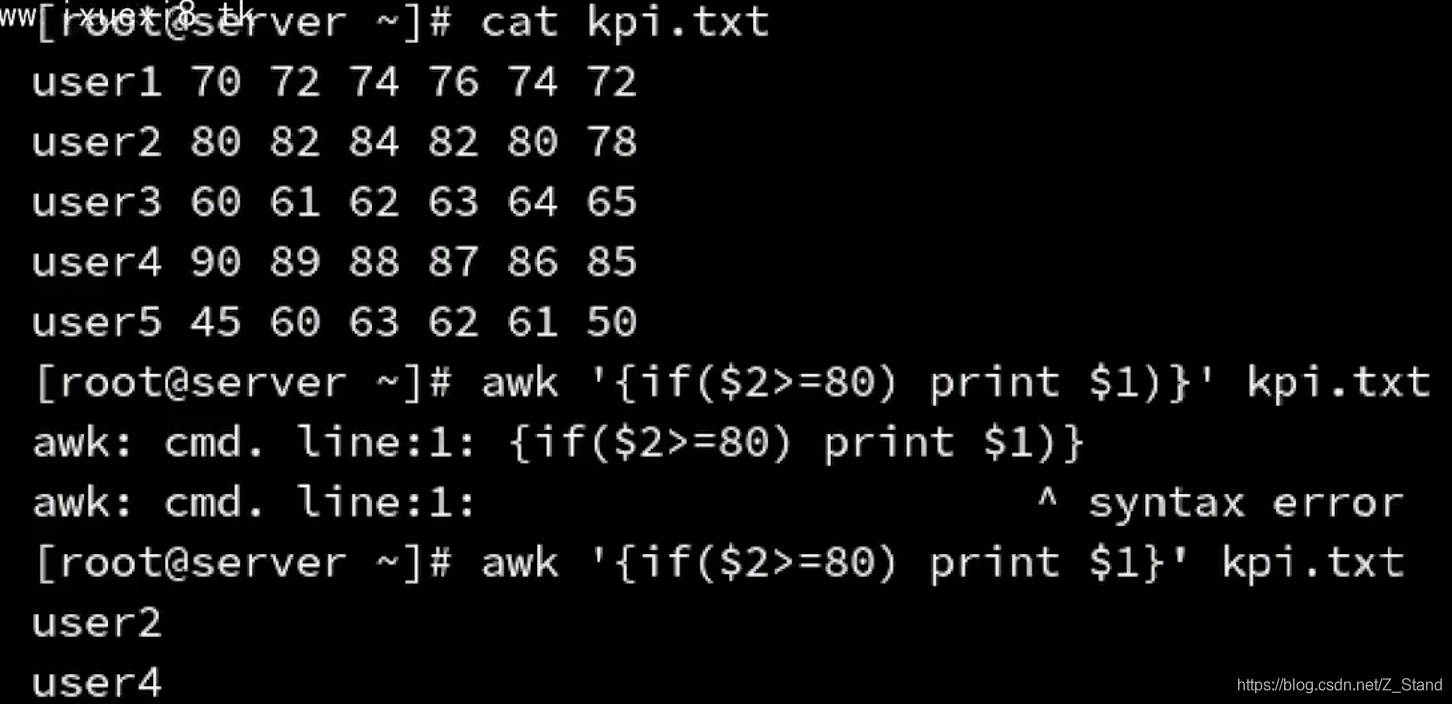
if开头,根据表达式结果判断执行哪一条语句if(表达式)awk 语句1 [elseawk 语句2 ] - 如果有多个语句需要执行,可以使用{}将多个语句括起来
循环
while循环while (表达式)awk 语句1do循环do{ awk 语句1 }while(表达式)for循环
使用for进行求和,并取平均值for(初始值;循环判断条件;累加)awk 语句1
cat kpi.txt | awk '{sum=0;for(c=2;c<=NF;++c) sum+=$c;print sum/(NF-1)}'- 影响控制的其他语句
break
continue
awk 的数组
主要为了对awk进行多行关联,多行之间进行通信
数组的定义
数组:一组有某种关联的数据(变量),通过下标依次访问
数组名[下标]=值
下标可以使用数字,也可以使用字符串。
PS:即使使用的是数字,awk也会将其当作字符串或者字符来处理
数组的遍历
for (变量 in 数组名)
#使用 数组名[变量] 的方式依次对每个数组的元素进行操作
删除数组
delete 数组[下标]
举例,编写awk脚本文件avg.awk
awk '{sum=0;for(c=2;c<=NF;++c)sum+=$c;avg[$1]=sum/(NF-1)}END{for(user in avg)sum2+=avg[user];print sum2/NR}'
kpi.txt
加载awk脚本文件
awk -f avg.awk kpi.txt
命令行参数数组
命令行参数数组:ARGC 参数个数 和ARGV代表的参数内容
主要用来辅助awk的脚本使用
编辑arg.awk
BEGIN{ for(x = 0;x < ARGC;x ++)print ARGV[x] #打印每个参数内容print ARGC #打印参数个数
}
执行命令awk -f arg.awk 11 22 33
输出如下:
awk #第0个参数,命令名称
11
22
33
4 #总共四个参数(当前命令也会被记录进去)
复杂数组的使用案例
编辑result.awk,用来进行总分,平均分、高于且低于平均分人数统计、分数评级、各个级别人数统计,该数据记录在kpi.txt
{
sum = 0
for(c = 2; c <= NF; c++)sum += $cavg[$1] = sum / (NF - 1)if(avg[$1] >= 80) #统计每个人的评级level = "S"
else if(avg[$1] >=70)level = "A"
else if(avg[$1] >= 60)level = "B"
else level = "C"print $1,avg[$1],levelletter_all[level] ++ #关联数组,统计各个评级的人数
}
END {
for(usr in avg)sum2 += avg[usr]avg_all = sum2 / NR #所有人的平均成绩
print "avg_all is :",avg_allfor(usr in avg) #计算超过以及小于平均成绩的人数if(avg[usr] >= avg_all)up++elsedown++print "biger than avg_all",up
print "less than avg_all",downprint "S:",letter_all["S"]
print "A:",letter_all["A"]
print "B:",letter_all["B"]
print "C:",letter_all["C"]
}
运行awk -f result.awk kpi.txt
其中kpi.txt内容如下:
user1 72 56 83 91
user2 55 67 45 89
user3 90 87 85 83
user4 56 57 99 95
user5 55 60 64 32
最终输出如下:
user1 75.5 A
user2 64 B
user3 86.25 S
user4 76.75 A
user5 52.75 C
avg_all is : 71.05
biger than avg_all 3
less than avg_all 2
S: 1
A: 2
B: 1
C: 1
awk函数
算数函数
sin()和cos()int()
awk 'BEGIN{pi=3.14;print int(pi)}'rand()伪随机数 和srand()重新获取种子 0-1之间
awk 'BEGIN{srand();print rand()}'
字符串函数
gsub(r,s,t)字符串替换sub(r,s,t)字符串替换substr(r,s,t)字符串替换split(s,a,sep)字符串分割match(s,r)字符串匹配length(s)字符串长度index(s,t)
通过man awk 搜索函数名称,可以看到具体函数的功能以及详细用法
自定义函数
函数定义的位置,写在 BEGIN ,{},END之外
function 函数名(参数){ awk 语句return awk 变量
}
举例如下:
awk 'function a(){ return 0 } BEGIN{print a()}'
awk 'function twice(str) { return str str} BEGIN{print twice("hello awk")}'
更多相关:
-
在运维过程中,发现portal中出现流量异常曲线, 就从排查ATS的访问日志中的异常域名开始,下面是我截获的对应时段的访问日志截图 发现里面有502,403等异常响应,我们将这段访问日志文件记为exception_peak.log。采用下面的命令来过滤出502的访问记录,并剥离出对应的访问链接的host,统计指定时段中...
-
变量传递 外部变量传入 lsblk|awk -v A=$A -v B=$B '{print A,B}'lsblk | awk '{print A,B}' A=$A B=$B 内部变量传出 eval $(lsblk|awk '{print "A='$1'"}')eval $(lsblk|awk 'printf("A=%s ",$1)...
-
awk的语法 awk [options] ‘Pattern {Actions}’ file1,file2… 之前介绍了三种模式:空模式,关系运算模式,BEGIN/END模式 正则模式 模式可以理解成条件,正则模式就是满足正则表达式条件的,就执行相应的动作,否则不执行。 如果我们想要找到在/etc/passwd文件中,...
-
awk有一些内置变量和外置变量,内置变量就是awk自带的变量,用户可以拿来直接使用,如FS,OFS等 awk常用内置变量如下几种: FS:输入单词分隔符,默认是空格 OFS:输出单词分隔符,默认是空格 RS:指定输入时候的换行符(awk是一行行处理数据的) ORS:指定输出的符号,替代换行符(awk以换行符...
-
#coding:utf-8'''Created on 2017年10月25日@author: li.liu'''import pymysqldb=pymysql.connect('localhost','root','root','test',charset='utf8')m=db.cursor()'''try:#a=raw_inpu...
-
python数据类型:int、string、float、boolean 可变变量:list 不可变变量:string、元组tuple 1.list list就是列表、array、数组 列表根据下标(0123)取值,下标也叫索引、角标、编号 new_stus =['刘德华','刘嘉玲','孙俪','范冰冰'] 最前面一个元素下标是0,最...
-
from pathlib import Path srcPath = Path(‘../src/‘) [x for x in srcPath.iterdir() if srcPath.is_dir()] 列出指定目录及子目录下的所有文件 from pathlib import Path srcPath = Path(‘../tenso...
-
我在使用OpenResty编写lua代码时,需要使用到lua的正则表达式,其中pattern是这样的, --热水器设置时间 local s = '12:33' local pattern = "(20|21|22|23|[01][0-9]):([0-5][0-9])" local matched = string.match(s, "...
-
在分析ats的访问日志时,我经常会遇到将一些特殊字段对齐显示的需求,网上调研了一下,发现使用column -t就可以轻松搞定,比如 找到ATS的access.log中的200响应时间过长的日志 cat access.log | grep ' 200 ' | awk -F '"' '{print $3}' > taoyx.log co...
-
学习目标:了解什么是数组;数组如何访问内存地址(一维,二维);什么是数组是由相同类型的元素的集合所组成的数据结构,分配一块连续的内存来存储。利用元素的索引可以计算出该元素对应的存储地址。 最简单的数据结构类型是一维数组。数组如何实现随机访问?数组是一种线性表数据结构,用一直连续的内存空间来储存一组具有相同类型的数据。根据数组的特性(连...
-
一、静态数据及动态数组的创建 静态数据: int a[10]; int a[]={1,2,3}; 数组的长度必须为常量。 动态数组: int len; int *a=new int...
-
给定一个数组 nums 和一个值 val,你需要原地移除所有数值等于 val 的元素,返回移除后数组的新长度。 不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空间的条件下完成。 元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。 示例 1: 给定 nums = [3,2,2,3], val...
-
给定一个排序数组,你需要在原地删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。 不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空间的条件下完成。 示例 1: 给定数组 nums = [1,1,2], 函数应该返回新的长度 2, 并且原数组 nums 的前两个元素被修改为 1, 2...
-
文章目录1. 数组的声明2. 数组元素的遍历3. 数组的截取4. Go 语言的切片5. 数组 和 切片的共同点...