目录
1. Scene Graph Generation with External Knowledge and Image Reconstruction

2. Knowledge Acquisition for Visual Question Answering via Iterative Querying
Author: 李飞飞
publish: CVPR 2017

3. Towards VQA Models That Can Read

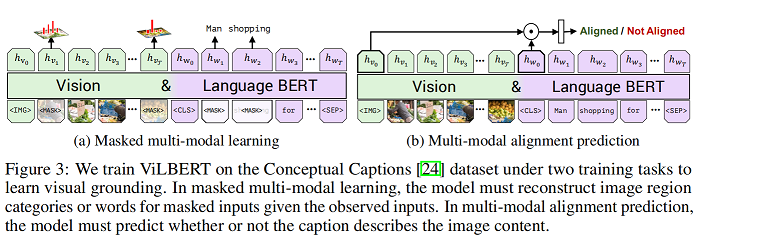
4. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks

1.1 将BERT用于image roi 和text, 然后将text的word embedding和image roi的embedding用于其他任务,取得2-10个百分点的提升。
5. VL-BERT: PRE-TRAINING OF GENERIC VISUAL LINGUISTIC REPRESENTATIONS

6. VISUALBERT: A SIMPLE AND PERFORMANT BASELINE FOR VISION AND LANGUAGE


7.Dynamic Memory Networks for Visual and Textual Question Answering
publlish: ICML 2016

