byte endian(biglittle endian)
1. 大小端的区别
little endian:把低位字节存放在内存的低位; //
big endian: 将低位字节存放在内存的高位;
比如:0x1234,则12 就属于高位字节;34 属于低位字节
假如从地址0x0000 0000开始的一个字节中保存数据0x12345678, 这2中字节序在内存当中存放顺序为:
address: 0x0000 0000 0x0000 0001 0x0000 0002 0x0000 0003
big_endian 0x12 0x34 0x56 0x78
lit-endian 0x78 0x56 0x34 0x12
2. 为什么会有大小端模式的区分呢?
因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
当前的存储器,多以byte为访问的最小单元,当一个逻辑上的整理必须分割为物理上的若干单元时就存在了先放谁后放谁的问题,于是endian的问题应运而生了,对于不同的存储方法,就有Big-endian和Little-endian两个描述.
(这两个术语来自于 Jonathan Swift 的《格利佛游记》其中交战的两个派别无法就应该从哪一端--小端还是大端--打开一个半熟的鸡蛋达成一致。在那个时代,Swift是在讽刺英国和法国之间的持续冲突,Danny Cohen,一位网络协议的早期开创者,第一次使用这两个术语来指代字节顺序,后来这个术语被广泛接纳了。)
3. 各种CPU支持的字节序不同
lit-endian: x86
big_endian: Motorola/IBM/SUM cpu
ARM 既能工作于大端也能工作于小端
所有网络协议也都是采用big endian的方式来传输数据的。所以有时我们也会把big endian方式称之为网络字节序。
4. 怎么检测当前的处理器属于哪个字节序?
a. 用VC2005 调试查看short变量在内存中的布局,如下:
int _tmain(int argc, _TCHAR* argv[])
{
short t = 0x1234;
return 0;
}
&t = 0x12ff60, t 在内存当中的布局如下图:
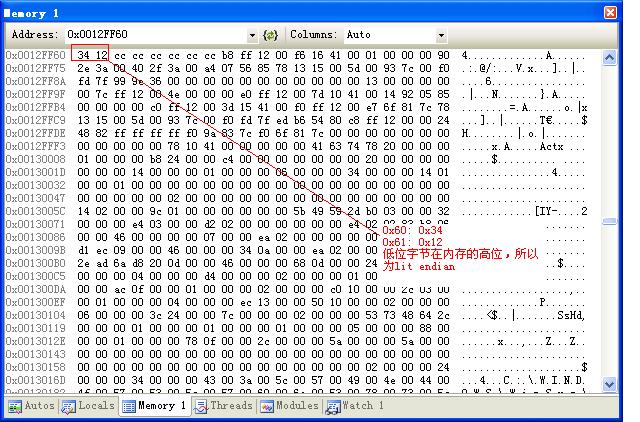
由此可见, x86 CPU 采用的是little endian.
b. 利用字节序的基本规则进行判断
enum BYTE_ENDIAN
{
little_endian,
big_endian,
unknown_error
};
BYTE_ENDIAN check_byte_endian_1()
{
short t = 0x1234;
char c = (*(char *)(&t));
if (0x12 == c)
{
return big_endian;
}
else if(0x34 == c)
{
return little_endian;
}
return unknown_error;
}
3.
/*---------------------------------------------------------------------------
联合体union的存放顺序是所有成员都从低地址开始存放,利用该特性,
轻松地获得了CPU对内存采用Little-endian还是Big-endian模式读写
-----------------------------------------------------------------------------*/
BYTE_ENDIAN check_byte_endian_2()
{
union test_endian
{
char c;
short s;
};
test_endian t;
t.s = 0x1234;
if (0x12 == t.c)
{
return big_endian;
}
else if(0x34 == t.c)
{
return little_endian;
}
return unknown_error;
}
==================================
另外,可以参考百度百科(关键字:字节序):http://baike.baidu.com/view/2194385.htm 获取更多信息。
更多相关:
-
字节串bytes字节串也叫字节序列,是不可变的序列,存储以字节为单位的数据字节串表示方法:b"ABCD"b"x41x42"...字节串的构造函数:bytes() 创建一个空的字节串 ,同b””bytes(整数可迭代对象) 用可迭代对象创建一个字节串bytes(整数n) 生成n个值为0的字节串bytes(字符串,encoding='...
-
Unicode编码 最初的unicode编码是固定长度的,16位,也就是2两个字节代表一个字符,这样一共可以表示65536个字符。显然,这样要表示各种语言中所有的字符是远远不够的。Unicode4.0规范考虑到了这种情况,定义了一组附加字符编码,附加字符编码采用2个16位来表示,这样最多可以定义1048576个附加字符。所以4个字节...
-
Java IO流学习总结三:缓冲流-BufferedInputStream、BufferedOutputStream 转载请标明出处:http://blog.csdn.net/zhaoyanjun6/article/details/54894451 本文出自【赵彦军的博客】 InputStream |__FilterInputSt...
-
一直对编码这块晕晕乎乎,今天终于看到一篇写的很清楚也很风趣的文章,转过来mark一下。 很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物。他们看到8个开关状态是好的,于是他们把这称为”字节“。再后来,他们又做了一些可以处理这些字节的机器,机器开动了,可以用字节来组合出很多状态,状态开始...
-
我们知道在由于大端机和小端机导致网络字节序和主机序有可能是有差异的,我们可以使用系统的ntohs,ntohl,htons和htonl这些处理函数进行转换,下面是我写的一个关于ntohs在处理小端机字节序转换的函数的简单实现. 思想大致如下: 用u_int16_t的2字节16位的整形变量来存储这个整数,首先将第一个字节和该变量进行或运算...
-
中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。 例如, [2,3,4] 的中位数是 3 [2,3] 的中位数是 (2 + 3) / 2 = 2.5 设计一个支持以下两种操作的数据结构: void addNum(int num) - 从数据流中添加一个整数到数据结构中。 double findMedia...
-
前言 堆数据结构 使用的是优先级队列实现,创建堆的时候需要指定堆中元素的排列方式,即最大堆或者最小堆 最大堆即 堆顶元素为堆中最大的元素 最小堆即 堆顶元素为堆中最小堆元素 如下为一个最大堆 中位数: 一组数排序后,如果元素个数如下 奇数个数n:(int) n/2 的数 偶数个数n: (int) n/2 和(int) n/2...