Rocksdb iterator 的 Forward-scan 和 Reverse-scan 的性能差异
前言
最近在读 MyRocks 存储引擎2020年的论文,因为这个存储引擎是在Rocksdb之上进行封装的,并且作为Facebook 内部MySQL的底层引擎,用来解决Innodb的空间利用率低下 和 压缩效率低下的问题。而且MyRocks 在接入他们UDB 之后成功达成了他们的目标:将以万为单位的服务器集群server个数缩减了一半。
MyRocks 在facebook内部的成功实践证明了LSM-tree的存储引擎经过一系列优化之后能够达到和B±tree存储引擎性能接近且节约大量存储成本的目的。对于我们底层存储引擎开发者来说,MyRocks 的实践过程在rocksdb上做了大量的通用型特性的开发。其中就包括针对rocksdb的反向迭代的优化。
迭代器 正向 或者 反向 扫描 描述
关于迭代器的扫描方向,大体代码如下:
- 正向扫描(字节序升序扫描)
最终的结果类似:auto begin_it = db->NewIterator(rocksdb::ReadOptions()); for (begin_it->SeekToFirst(); begin_it->Valid(); begin_it->Next()) { assert(begin_it->Valid()); } delete begin_it;3499211612 3586334585 3890346734 545404204 581869302 - 反向扫描(字节序降序扫描)
最终的扫描结果类似:auto it = db->NewIterator(rocksdb::ReadOptions()); for (it->SeekToLast(); it->Valid(); it->Prev()) { assert(it->Valid()); } delete it;581869302 545404204 3890346734 3586334585 3499211612
这两种扫描方式中我们使用单机存储引擎大多数的scan都是第一种方式,即按照key写入的顺序,从头开始遍历。
然而方向扫描 则是在数据库使用单机存储引擎中出现的需求,单机引擎没办法在分布式场景支持MVCC,所以一般上层分布式数据库会为每一个写入到引擎的key都会增加一个时间戳,来支持多版本。很多时候需要按照key的更新时间降序扫描key,这个时候一般情况就需要通过第二种方式来进行扫描。这个问题在 MyRocks 接入 UDB 的实现过程中就是一个痛点,UDB 会有固定的场景需要按照更新时间降序获取好友关系。
先不说两种方式的实现,我们先看看两种方式的扫描性能。
性能测试
测试描述:完全随机写入2百万 条key,扫描的时候不打开block-cache。
测试代码:
#include 测试结果:
...
87
Finish open !
Finish write !
ForwardTraverse use time: 496311
BackwardTraverse use time: 565935
88
Finish open !
Finish write !
ForwardTraverse use time: 447470
BackwardTraverse use time: 565372
89
Finish open !
Finish write !
ForwardTraverse use time: 441705
BackwardTraverse use time: 563440
...
测试了100次,基本都是这个耗时的量级,可以发现两种扫描的耗时相差15%-25%。如果MyRocks 中使用传统的反向扫描,性能则相比于本身的正向扫描损失15-25%,这对于想要节约50% 集群server的目标来收显然不可忍。
当然,还有更为方便的测试方式,就是使用db_bench,可以使用它的readseq和readreverse两种benchmark进行测试,因为我是在mac上,rocksdb的完整编译不太方便,跑db_bench有点麻烦,就写一个简单的小脚本测试就可以了。
正反 扫描迭代器 实现
通过使用两种迭代器,我们能够很容易发现两种扫描的方式差异主要体现在获取下一个key的方式,一个是Next,一个是Prev。
我们将刚才的sst文件dump出来,可以发现sst内部的datablock 存储的key的方式本身就是字节升序存储,而且为了节约存储成本,底层实际采用的是delta方式的存储。即如果两个key拥有公共前缀,则两个key的实际形态是公共前缀+后面一个不同的字符进行存储,并非存储完整的两个key,所以 在prev的时候不仅仅需要读当前key,还需要找到前面第比他小的key来进行key的delta补全。
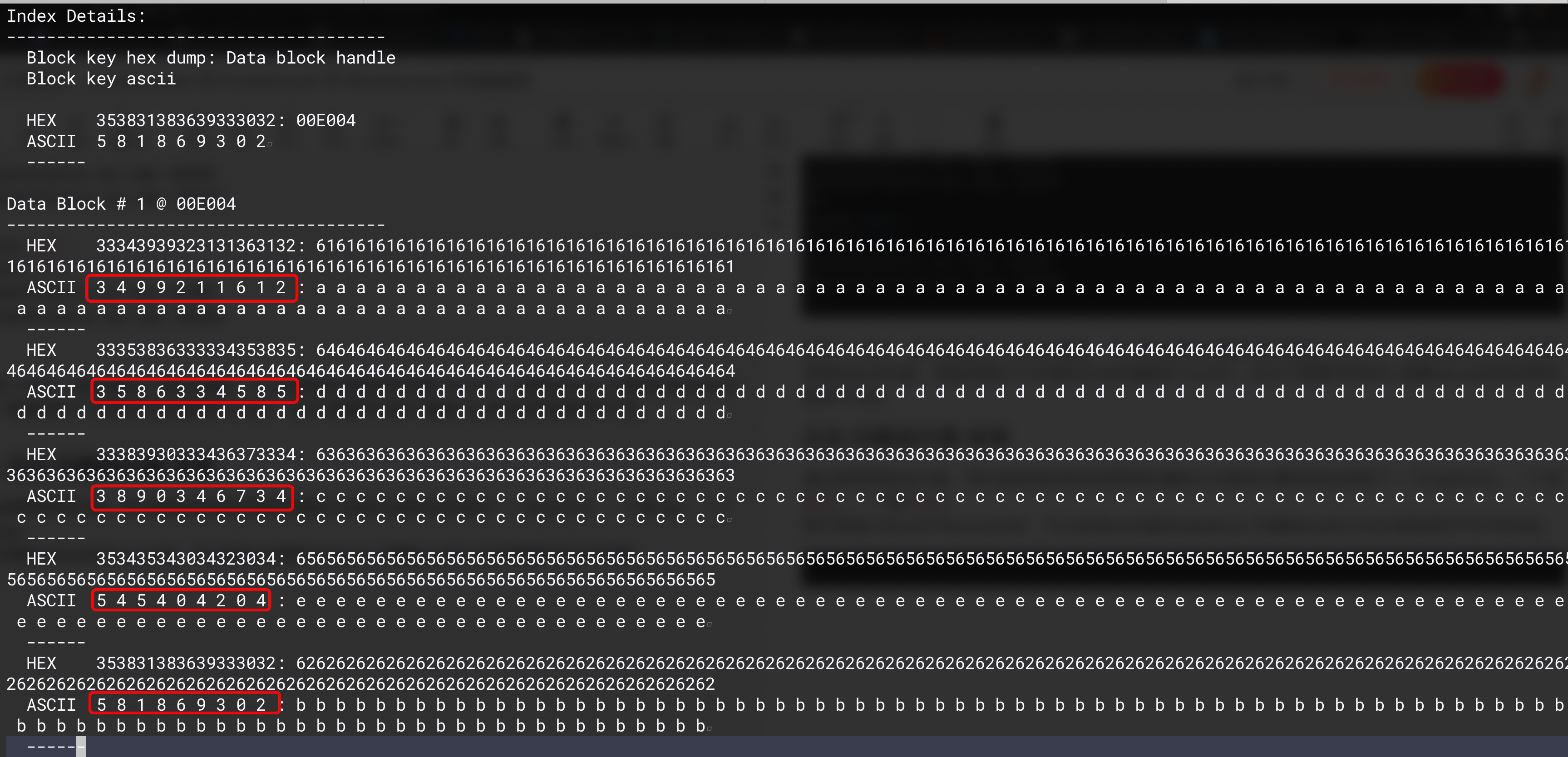
再分别看看我们的Next和 Prev的实现
在Next中,无需考虑其他,只需要按照顺序拿到key,并根据key的类型进行相应的处理就可以了。
void DBIter::Next() { assert(valid_);assert(status_.ok());PERF_CPU_TIMER_GUARD(iter_next_cpu_nanos, env_);// Release temporarily pinned blocks from last operation// 释放上一次Next占用的资源ReleaseTempPinnedData();local_stats_.skip_count_ += num_internal_keys_skipped_;local_stats_.skip_count_--;num_internal_keys_skipped_ = 0;bool ok = true;if (direction_ == kReverse) { is_key_seqnum_zero_ = false;if (!ReverseToForward()) { ok = false;}} else if (!current_entry_is_merged_) { // If the current value is not a merge, the iter position is the// current key, which is already returned. We can safely issue a// Next() without checking the current key.// If the current key is a merge, very likely iter already points// to the next internal position.assert(iter_.Valid());iter_.Next();PERF_COUNTER_ADD(internal_key_skipped_count, 1);}local_stats_.next_count_++;if (ok && iter_.Valid()) { // 根据key的类型处理就可以了。FindNextUserEntry(true /* skipping the current user key */,prefix_same_as_start_);} else { is_key_seqnum_zero_ = false;valid_ = false;}if (statistics_ != nullptr && valid_) { local_stats_.next_found_count_++;local_stats_.bytes_read_ += (key().size() + value().size());}
}
而Prev的实现则没有这么单一了,因为底层的存储本身是升序存储,Next只需要在mem/imm/l0(多个iter)/l1/l2… 这一些迭代器做堆排序就可以了。prev还需要不断得向前读,直到读到一个restart点(读完完整的data-block)确认好当前key的delta部分。
如下代码是Prev的核心部分实现:
void DBIter::PrevInternal() { while (iter_.Valid()) { saved_key_.SetUserKey(ExtractUserKey(iter_.key()),!iter_.iter()->IsKeyPinned() || !pin_thru_lifetime_ /* copy */);if (prefix_extractor_ && prefix_same_as_start_ &&prefix_extractor_->Transform(saved_key_.GetUserKey()).compare(prefix_start_key_) != 0) { // Current key does not have the same prefix as startvalid_ = false;return;}assert(iterate_lower_bound_ == nullptr || iter_.MayBeOutOfLowerBound() ||user_comparator_.Compare(saved_key_.GetUserKey(),*iterate_lower_bound_) >= 0);if (iterate_lower_bound_ != nullptr && iter_.MayBeOutOfLowerBound() &&user_comparator_.Compare(saved_key_.GetUserKey(),*iterate_lower_bound_) < 0) { // We've iterated earlier than the user-specified lower bound.valid_ = false;return;}// 对当前key的type进行处理,确保读到的key是最新的// 如果读到的是merge类型,则需要不断得向前mege// 如果读到的是Delete类型,则需要不断得向前读,// 直到遇到一个大于这个key版本的key//(reverse过程中遇到的delete版本较低,需要继续向前读才能读到同一个userkey的更新版本)if (!FindValueForCurrentKey()) { // assigns valid_return;}// Whether or not we found a value for current key, we need iter_ to end up// on a smaller key.// 不断得向前扫描,直到找到了一个小于当前key的key才结束。if (!FindUserKeyBeforeSavedKey()) { return;}if (valid_) { // Found the value.return;}if (TooManyInternalKeysSkipped(false)) { return;}}// We haven't found any key - iterator is not validvalid_ = false;
}
总结下来就是Prev的过程需要读额外的key,因为prev的过程同一个user key的更新版本需要不断得向前读,才能读到。相比于Next原生 就能读到当前userkey的最新版本来说 scan的代价确实大了不少。
更底层的迭代器的Prev和Next可以看block.cc中的DataBlockIter,它提供了在不同 datablock 之间如何通过和 indexblock 的 restart点来读取指定的key。
优化
MyRocks 开发之前的性能测试 就发现了Rocksdb的这个问题,那他们也提出了比较友好的解决方案,那就是Reverse Comparator。我们知道Rocksdb 的key的写入/读取顺序是依赖 Comparator ,也就是sst内部的有序是由Comparator决定的。
就像是 我们为一个vector排序,可以通过一个自定义comparator来决定vector中元素的排序行为。对于Rocksdb来说,这个Comparator 作用的地方主要是 memtable中skiplist的构建以及 compaction过程中将key写入一个新的sst。所以这个comparator 决定了keys在sst文件中的顺序。所以,MyRocks 针对 Reverse-scan 痛点 实现了Reverse Comparator : ReverseBytewiseComparator,它就是指定key的存储顺序和原来相反。
可以通过options.comparator = rocksdb::ReverseBytewiseComparator();指定,因为UDB的这种reverse-scan 模式比较固定,所以可以在构建db的时候直接用这个comparator。很明显这个优化的好处就是将原来的Reverse-scan 变更为 Forward-scan,性能能够提升10-15%的样子(可以使用上面的代码进行测试)。
总结
这里MyRocks 开发团队 仅仅实现了一个ReverseBytewiseComparator 在MyRocks 的 scan 痛点中 得到这样的优化提升,所以能够看出来 Rocksdb 的可扩展性。在MyRocks 的论文中也有很多次表示对Rocksdb 可扩展性的认可。
同样,我们也能理解到rocksdb 这个引擎的定位 并不是说实现了一个全方位性能超越B±tree 的引擎,而是针对 任何用户的workload 经过非常简单的开发或者参数调整 能够达到超越其他引擎 或者 与其他引擎持平 的性能/功能。Rocksdb 将应用的可扩展性做到了极致,这是它广受欢迎的关键。
更多相关:
-
前言 近期在做on nvme hash引擎相关的事情,对于非全序的数据集的存储需求,相比于我们传统的LSM或者B-tree的数据结构来说 能够减少很多维护全序上的计算/存储资源。当然我们要保证hash场景下的高写入能力,append-only 还是比较友好的选择。 像 Riak的bitcask 基于索引都在内存的hash引擎这种,...
-
参考自: https://www.cnblogs.com/zeng1994/p/03303c805731afc9aa9c60dbbd32a323.html 1、maven依赖
springboot redis配置
1、引入maven依赖
org.springframework.boot spring-boot-starter-data-redis json 键值对增加、删除 obj.key='value'; // obj.key=obj[key]=eval("obj."+key); delete obj.key; vue中新增和删除属性 this.$set(object,key,value) this.$delete( object, key ) 触发视图更新 遍历键值 for...
文章目录概览1. UDB 架构2. UDB 表格式3. Rocksdb:针对flash存储优化过的第三方库3.1 Rocksdb架构3.2 为什么选择Rocksdb4. MyRocks / Rocksdb 开发历程4.1 设计目标4.2 性能挑战4.2.1 降低CPU的消耗4.2.2 降低range-scan 的延时消耗4.2.3 磁...
Compaction过程中 产生大量读I/O 的背景 项目中因大value 需求,引入了PingCap 参考Wisckey 思想实现的key-value分离存储 titan, 使用过程中因为有用到Rocksdb本身的 CompactionFilter功能,所以就直接用TitanDB的option 传入了compaction filt...
简单记录一些 在linux下 统计进程内部函数运行耗时的统计工具,主要是用作性能瓶颈分析。当然以下工具除了pstack功能单一之外,其他的工具都非常强大,这里仅仅整理特定场景的特定用法,用作协同分析。 以下工具需要追踪具体的进程,如果想要打印信息更全,建议编译的时候将符号信息都编译到二进制文件之中,-g选项 strace str...
想要自己随时随地写一写rocksdb的代码,并且快速测试,但是公司的物理机登陆过于麻烦,想要验证功能的话其实在自己的电脑就完全可以了。 安装 brew install rocksdb,默认二进制文件安装在/usr/local/bin在~/.bashrc或者自己正在使用的shell的rc文件中 加入rocksdb的bin文件所在路径...