c++控制台应用每一列数据如何对齐_Python数据分析第五节 pandas入门
这一节将开始学习python的一个核心数据分析支持库---pandas,它是python数据分析实践与实战的必备高级工具。对于使用 Python 进行数据分析来说,pandas 几乎是无人不知,无人不晓的。今天,我们就来认识认识数据分析界鼎鼎大名的 pandas。
目录
一. pandas主要数据结构
Series
DataFrame
二. 列的查改增删
查看列
修改列
新增列
删除列
三. 导入Excel表格

一. pandas主要数据结构
想要了解pandas,我们需要先了解它的主要数据结构Series(一维数据)和DataFrame(二维数据),这两种数据足够用来处理金融,统计,社会工作工程等领域绝大多数案例!
在开始之前我们需要了解怎么导入pandas库
import pandas as pd将 pandas 简写成 pd 几乎成了一种不成文的规定。因此,只要你看到 pd 就应该联想到这是 pandas。
Series
Series 是一种类似于 Numpy 中一维数组的对象,它由一组任意类型的数据以及一组与之相关的数据标签(即索引)组成。举个最简单的例子:

输出的结果中:左边的是数据的标签,默认从 0 开始依次递增。右边是对应的数据,最后一行表明了数据类型。
我们也可以像下面这样使用 index 参数自定义数据标签:
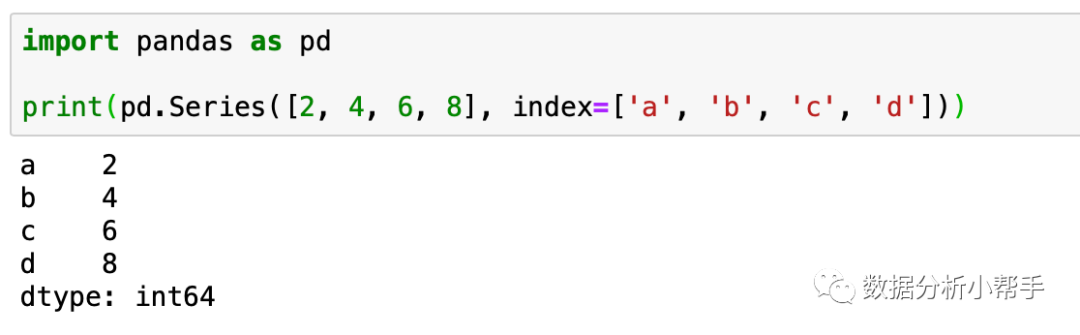
我们还可以直接使用字典同时创建带有自定义数据标签的数据,pandas 会自动把字典的键作为数据标签,字典的值作为相对应的数据。

可以看出运行结果和上面是一样的!
访问 Series 里的数据的方式,也是使用中括号加数据标签的方式来获取里面的数据
import pandas as pds1 = pd.Series([2, 4, 6, 8])s2 = pd.Series({ 'a': 2, 'b': 4, 'c': 6, 'd': 8})print(s1[0])# 输出:2print(s2['b'])# 输出:4标签的作用很强大,我们可以对相同标签的两组数据进行加减乘除运算
假设有两个租车公司,我们要计算一下两家公司各种汽车的数量总和:

pandas 自动帮我们将相同数据标签的数据进行了计算,这就是数据对齐。
你可能会有疑问,如果两家租车公司汽车种类不一样怎么办,pandas 还能进行数据对齐吗?我们试一下就知道了。

可以看到,对于数据标签不相同的数据,运算后结果是 NaN。NaN 是 Not a Number(不是一个数字)的缩写,因为其中一个 Series 中没有对应数据标签的数据,无法进行计算,因此返回了 NaN。
对于这种情况,我们想让没有的数据默认为 0,然后再进行计算。这种需求 pandas 可以实现吗?
当然可以!只需调用 Series 的 add() 方法,并设置好默认值即可。具体用法如下:
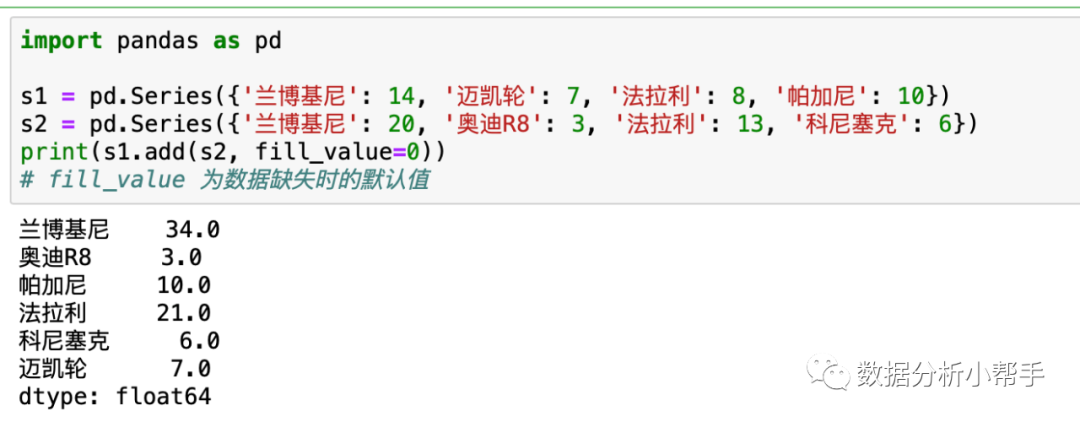
add() 方法对应的是加法,数学中的四则运算在 pandas 中都有一一对应的方法,它们的用法都是类似的。具体对应关系如下图所示:

2. DataFrame
Series 是一维数据,而 DataFrame 是二维数据。什么意思呢?你可以把 DataFrame 想象成一个表格,表格有行和列这两个维度,所以是二维数据。
实际上,表格中的每一行或每一列都是一个 Series,这些 Series 就组成了 DataFrame。按行分,每一行数据加上上面的数据标签就是一个 Series, 或者按列分每一列数据加上左边的数据标签也是一个Series
那么,如何用 DataFrame 实现上图中那样的表格呢?也很简单,请看代码:

接下来是本节的重点——DataFrame。构建 DataFrame 的办法有很多,最常用的一种是传入一个由等长列表组成的字典。即字典里每个值都是列表,且它们的长度必须相等。
这样我们就得到了一个表格,字典的键会作为表格的列名。最左边的是索引,也是默认从 0 开始依次增加。当然,我们也可以在构建 DataFrame 的时候传入 index 参数来自定义索引。

全都写在一行代码就太长了,所以我把表格数据放到了变量 data 中。并且通过 index 参数将日期作为了 DataFrame 的索引。
二. 列的查改增删

1. 查看列
为了减少重复代码的出现,接下来的讲解都基于下面的代码。
import pandas as pddata = { '兰博基尼': [14, 20], '迈凯轮': [7, 3], '法拉利': [8, 13], '帕加尼': [10, 6]}df = pd.DataFrame(data, index=['租车公司A', '租车公司B'])如果我们只想查看有关法拉利的数据,我们可以这样写:
print(df['法拉利'])输出结果为:

我们还能同时选择多列进行查看,只要把多个列名放到列表当中即可。
print(df[['法拉利', '迈凯轮']])输出结果为:

2. 修改列
如果我们发现表格中的数据有错误,想要修改,这其实非常的简单,直接对已有列直接赋值即可。
df['法拉利'] = [18, 23]print(df)输出结果就为修正后的:

3. 新增列
如果想要新增一列同样也非常的简单,对表格中不存在的列直接赋值就能添加新的列了。
df['奥迪R8'] = [3, 5]print(df)输出结果为

4. 删除列
删除列需要用到 drop() 方法。我们先来看一下用法:
df.drop('迈凯轮', axis=1, inplace=True)print(df)# 或者 print(df.drop('迈凯轮', axis=1))drop() 方法的第一个参数是要删除的列名或索引。axis 表示针对行或列进行删除,axis = 0 表示删除对应的行,axis = 1 表示删除对应的列,axis 默认为 0。
最后的 inplace = True 表示直接修改原数据,否则 drop() 方法只是返回删除后的表格,对原表格没有影响。因此上面两种写法的结果是一样的。
三. 导入Excel表格

导入Excel表格只需要一行代码即可:
import pandas as pddf = pd.read_excel('文件所在路径/文件名.xlsx')我们可以用代码:
print(type(df))来查看导入数据是一维数据(Series)还是二维数据(DataFrame)
读取到表格数据后,可能表格数据很多,我们想大致确认一下表格内容,不需要打印出完整的表格。这时我们可以使用 head() 方法来查看前 5 条数据。
代码为:
print(df.head())head() 方法还支持传入参数来控制显示前多少条数据,比如前 2 条数据:
print(df.head(2))除了查看开头的一些数据,还可以使用 tail() 方法查看末尾的数据。用法和 head() 一致,默认显示 5 条,可以传入参数来改变显示的条数。
print(df.tail())我们还能通过 info() 方法查看整个表格的大致信息。
print(df.info())运行结果及主要含义如下图所示:(用季度销售额的数据举例)
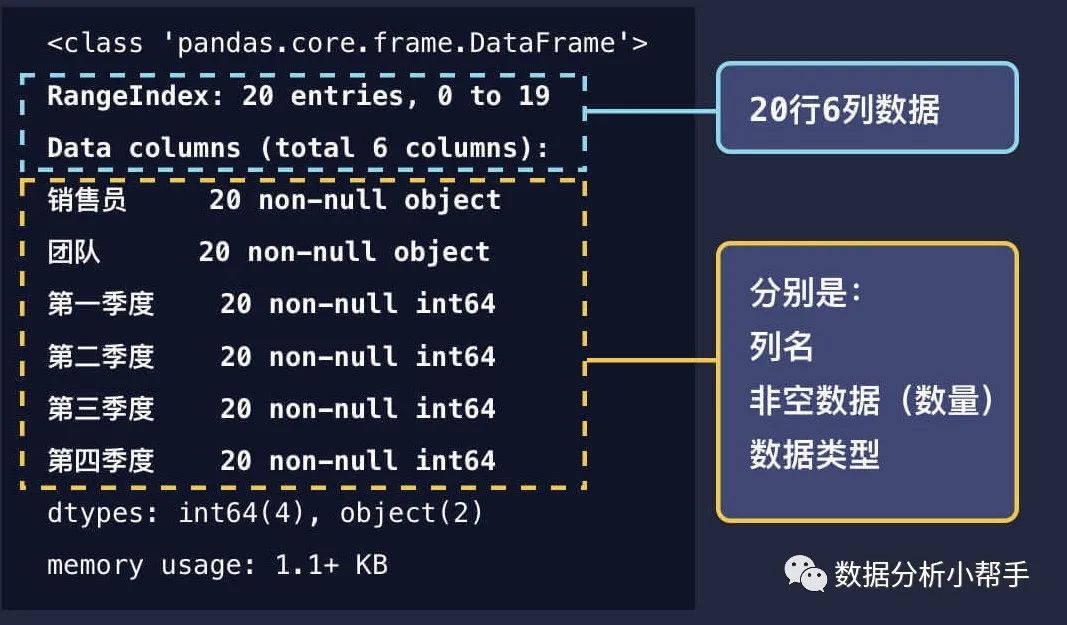
通过 info() 方法我们可以对表格大致有个了解,知道有几行几列,以及哪列有多少条缺失数据。
除此之外,我们还能通过 describe() 方法来快速查看数据的统计摘要,方便我们对数据有一个直观上的认识。
print(df.describe())生成的摘要从上往下分别表示数量、平均数、标准差、最小值、25% 50% 75% 位置的值和最大值。
?
长按关注公众号
欢迎留言交流

更多相关:
-
本文是西门子开放式TCP通信的第2篇,上一篇我们讲了使用西门子1200PLC作为TCP服务器的程序编写,可以点击下方链接阅读:【公众号dotNet工控上位机:thinger_swj】基于Socket访问西门子PLC系列教程(一)在完成上述步骤后,接下来就是编写上位机软件与PLC之间进行通信。上位机UI界面设计如下图所示:从上图可以看出...
-
我有一个大型数据集,列出了在全国不同地区销售的竞争对手产品。我希望通过使用这些新数据帧名称中的列值的迭代过程,根据区域将该数据帧分成几个其他区域,以便我可以分别处理每个数据帧-例如根据价格对每个地区的信息进行排序,以了解每个地区的市场情况。我给出了以下数据的简化版本:Competitor Region ProductA Product...
-
作为一名IT从业者,我来回答一下这个问题。首先,对于具有Java编程基础的人来说,学习Python的初期并不会遇到太大的障碍,但是要结合自己的发展规划来制定学习规划,尤其要重视学习方向的选择。Java与Python都是比较典型的全场景编程语言,相比于Java语言来说,当前Python语言在大数据、人工智能领域的应用更为广泛一些,而且大...
-
这段时间通过学习相关的知识,最大的变化就是看待事物更加喜欢去了解事物后面的本质,碰到问题后解决问题思路也发生了改变。举个具体的例子,我在学习数据分析,将来会考虑从事这方面的工作,需要掌握的相关专业知识这个问题暂且按下不表,那哪些具体的问题是我需要了解的呢,以下简单罗列:1、了解数据分析师这个岗位在各个地区的需求情况?2、数据分析师的薪...
-
英语的重要性,毋庸置疑!尤其对广大职场人士,掌握英语意味着就多了一项竞争的技能。那,对于我们成人来说,时间是最宝贵的。如何短时间内在英语方面有所突破,这是我们最关心的事情。英语学习,到底有没有捷径可以走,是否可以速成?周老师在这里明确告诉大家,英语学习,没有绝对的捷径走,但是可以少走弯路。十多年的教学经验告诉我们,成功的学习方法可以借...
-
展开全部 其实IDLE提供了一个显32313133353236313431303231363533e78988e69d8331333365663438示所有行和所有字符的功能。 我们打开IDLE shell或者IDLE编辑器,可以看到左下角有个Ln和Col,事实上,Ln是当前光标所在行,Col是当前光标所在列。 我们如果想得到文件代码...
-
前言[1]从 Main 方法说起[2]走进 Tomcat 内部[3]总结[4]《Java 2019 超神之路》《Dubbo 实现原理与源码解析 —— 精品合集》《Spring 实现原理与源码解析 —— 精品合集》《MyBatis 实现原理与源码解析 —— 精品合集》《Spring MVC 实现原理与源码解析 —— 精品合集》《Spri...
-
【本文摘要】【注】本文所述内容为学习Yjango《学习观》相关视频之后的总结,观点归Yjango所有,本文仅作为学习之用。阅读本节,会让你对英语这类运动类知识的学习豁然开朗,你会知道英语学习方面,我们的症结所在。学习英语这类运动类知识,需要把握四个原则第一,不要用主动意识。第二,关注于端对端第三,输入输出符合实际情况第四,通过多个例子...
-
点云PCL免费知识星球,点云论文速读。文章:RGB-D SLAM with Structural Regularities作者:Yanyan Li , Raza Yunus , Nikolas Brasch , Nassir Navab and Federico Tombari编译:点云PCL代码:https://github.co...