目录
整理最近学习 visual-reasoning的笔记
1. 关注 ACL、EMNLP、NAACLI等会议文章
未开始
2. Cyc项目
2.1 cyc知识库介绍:
该知识库包含了320w条人类断言,30w概念,15000谓词。
Cyc知识库中表示的知识一般形如“每棵树都是植物”、“植物最终都会死亡”。当提出“树是否会死亡”的问题时,推理引擎可以得到正确的结论,并回答该问题。
cyc中的概念被称为常量,主要有以下几种常量。
个体
集合
真值函数
函数
谓词
- 最重要的谓词是#isa 以及 #genls。 #isa 表示某个对象是某个集合的个体,#genls表示某个集合是另一个集合的子集。
句子中可以包含变量,变量字符串以 "?"开头,这些句子被称为“规则”。
2.2 对Cyc项目的批评:(我们可以借鉴吸收的经验)
- 该系统具有创建百科全书式知识库的野心,但却手动添加所有的知识到系统中
- 我们是否可以通过程序、脚本等辅助工具尽量自动化完成这一工作
- 其他都是一些技术难点,比如对物质概念的解释难以令人满意,缺乏测试系统,该系统在广度和深度上都有待完善。
3. WordNet
3.1 介绍
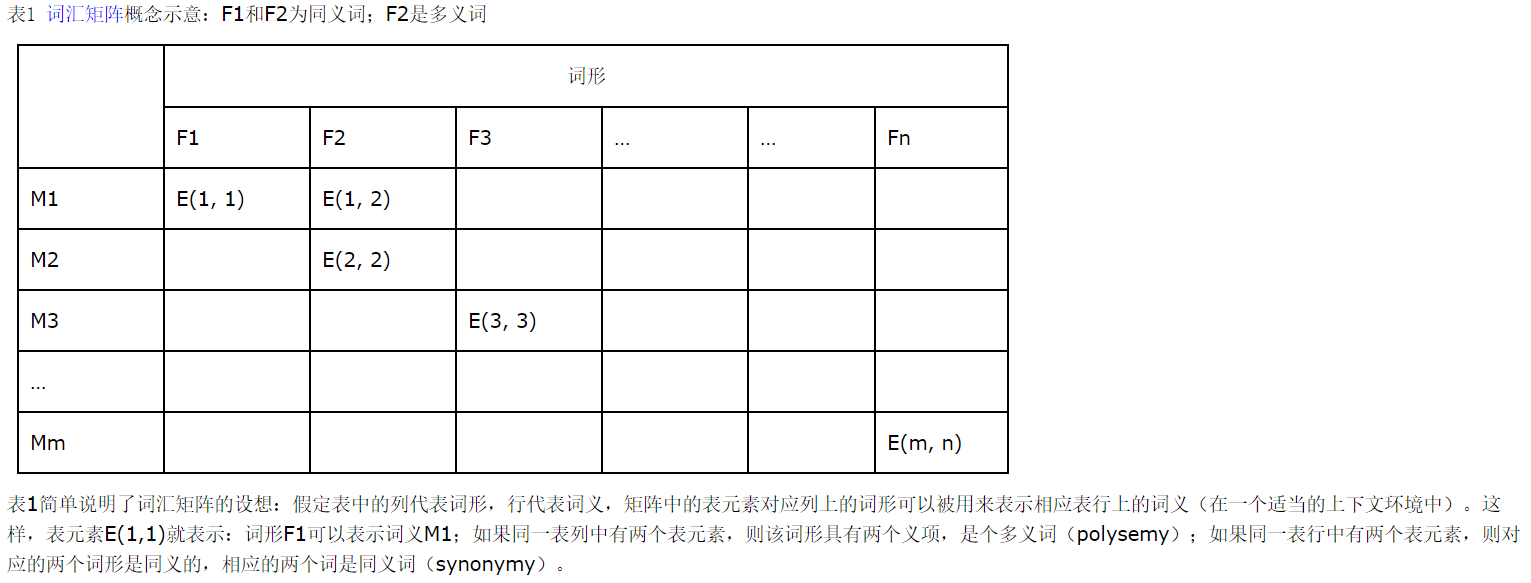
常规词典忽略了词典中同义信息的组织问题。WordNet将词汇分成五个大类:名词、动词、形容词、副词和虚词。 特色之处在于根据词义来组织词汇信息,按照词汇的矩阵模型组织的。
WordNet中单词关系包括如下几种:同义关系、反义关系、上下位关系、部分关系。
词形之间的词汇关系:同义关系、反义关系
词义之间的语义关系:上位关系(父集)、下位关系(子集)
WordNet 按照词汇的矩阵模型组织
4. Conceptnet
ConceptNet 是一个大规模的多语言常识知识库,其本质为一个以自然语言的方式描述人类常识的大型语义网络。ConceptNet 起源于一个众包项目 Open Mind Common Sense,自 1999 年开始通过文本抽取、众包、融合现有知识库中的常识知识以及设计一些游戏从而不断获取常识知识。ConceptNet 中共拥有 36 种固定的关系,如 IsA、UsedFor、CapableOf 等,图 4 给出了一个具体的例子,从中可以更加清晰地了解 ConceptNet 的结构。ConceptNet 目前拥有 304 个语言的版本,共有超过 390 万个概念,2800 万个声明(statements,即语义网络中边的数量),正确率约为 81%。另外,ConceptNet 目前支持数据集的完全下载。
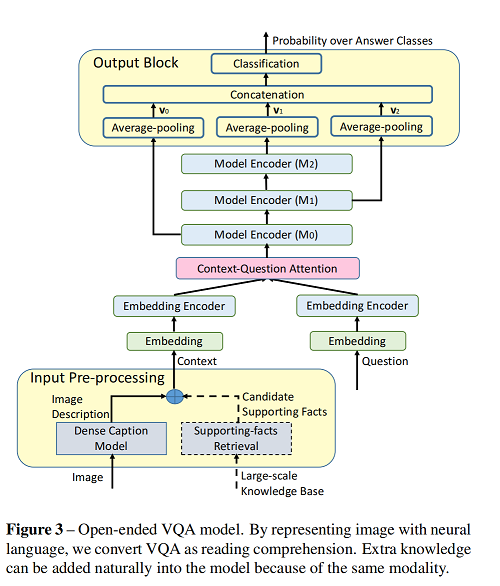
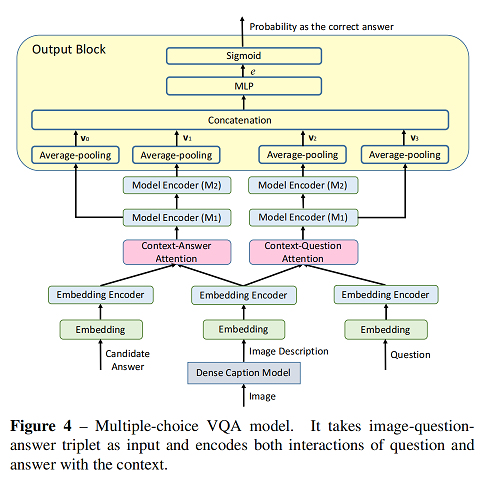
5. visual question answering as reading comprehension 李晖老师文章
main contribution
- 将 vqa 转换为 tqa任务,可以tqa的技术解决问题
- propose two type of vqa model
- it is easy to extend to adress knowledge based vqa
6. From Recognition fo Cognition: Visual Commonsense Reasoning
R2C Model
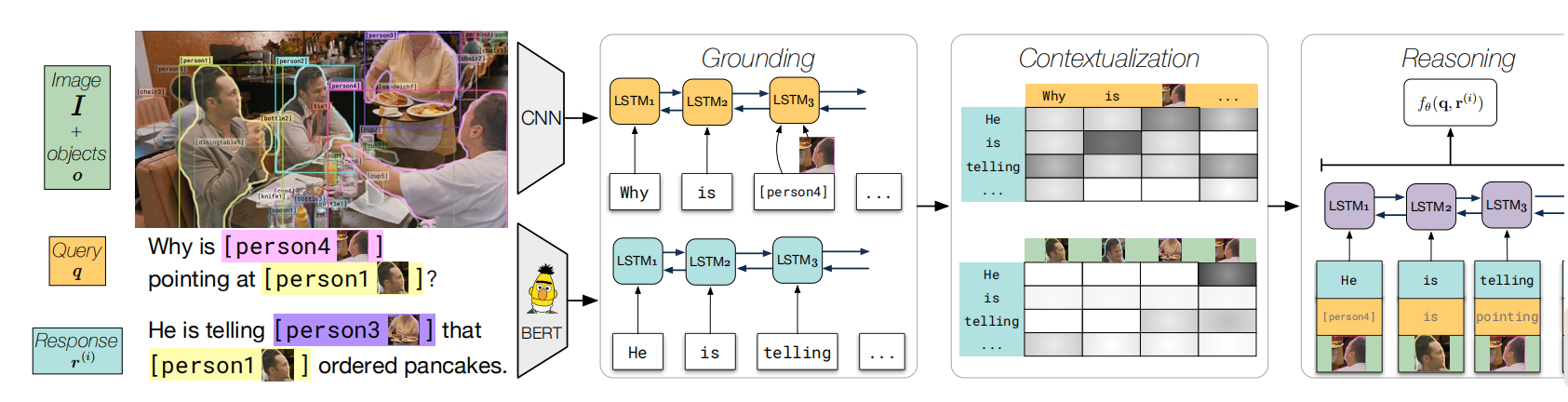
task
- 给定image, objects bbox ,query(question), four responses(answers), rationale,
- task 1:(Q -> A)对于一个query, 从四个候选response 中选择一个
- task 2: (QA -> R)如果选择出正确的response, 从四个候选 retionale中选择一个
可取之处:
- 利用到object bbox
- Grounding 中:把名词对应roi image 的feature 加入 LSTM中,如上图的【person 4】的 object feature
- Contextualization: 让 response 跟所有 object bbox feature 进行attention
不理解的地方:
- BERT 在网络中发挥什么作用?对输入的文本信息进行编码??
- Contextualization输出的是什么信息???
7. FVQA
作者从 coco和imagenet 中挑选了 2190张图片,这些图片主要包含三类 visual concept :
- Object: 图片中的真实实体(例如人、汽车、狗等)。它们是由两个分别在MS-COCO和ImageNet上训练的Fast-RCNN模型得到的。同时还利用了一个image attribute model在没有在图像中定位的情况下标注了92个objects。一共有326个不同的object class。
- Image Scene: 关于图像中的场景信息(例如办公室、卧室、海滩、森林等)。这是通过VGG-16在MIT Place 205-class数据集上训练得到的,同时使用了包含25个scene class的attribute classifier。最终一共包含221个不同的scene class。
- Action: Attribute model提供了24类不同的人或动物的动作,例如走路、跳跃、冲浪、游泳等。
而关于这些visual concept的knowledge则是从DBpedia、ConceptNet、WebChild等已有的外部KB中抽取的:
- DBpedia: 在DBpedia中存储的数据是从Wikipedia中抽取的到的。在这个KB中,concepts根据SKOS Vocabulary被link到它们各自的categories或者super-categories。
- ConceptNet: 这个KB是由几个commonsense关系组成的,例如UsedFor, CreatedBy和IsA。这篇文章中作者使用了11个common relationships来产生问题和答案。
- WebChild: 这个数据库中包含了一些比较级关系,例如Faster、Bigger和Havier。
数据集构造
数据集组成:
- knowledge base
- 提供common sense
- image-question-answer
- multiple-choices or other???
knowledge base中信息 类别
- CV 类
- 获取方式
- 从coco数据集中提取 cv common sense
- 用image captioning 的model生成,输入大量图片, 获取cv commense sense
- 类别:
- 位置常识
- action
- image scene
- 获取方式
- 非 CV类
- 获取方式
- 各种常识性知识从 concept net等 knowledge base中抽取
- 类别:
- object
- action
- scene
- 上述出现的名词从kb中抽取 相关信息
- 获取方式
knowledge base 存储形式:
- 初步想法:
- 三元组形式存储
- 进一步:
- 以图的形式存储(如何存储,如何查询 需要考虑)