首页 >
CUDA硬件架构知识
CUDA硬件架构知识
本博文是根据中科大信息学院谭立湘老师的课件加上自己的理解整理出来的
************************************************************************************
1.NVIDIA的GPU显卡历程:
Tesla->Fermi->Kepler->Maxwell->Pascal->Volta->Turing(2018)
2.体系结构相关术语:
-
SP(Streaming Processor):流处理器是GPU运算的最基本计算单元=core。
-
SFU(Special Function Unit):特殊函数单元用来执行超越函数指令,比如正弦、余弦、平方根等函数。
-
Shadercore(渲染核/着色器),SP的另一个名称,又称为CUDA core,始于Fermi架构
-
DP (双精度浮点运算单元)
-
SM(Streaming Multiprocessors):流式多处理器是GPU架构中的基本计算单元,也是GPU性能的源泉,由SP、DP、SFU等运算单元组成。这是一个典型的阵列机,其执行方式为SIMT(单指令多线程),区别于传统的SIMD(单指令流多数据流),能够保证多线程的同时执行。
Tesla的SM:

由8个SP、2个SF和一个执行双精度运算的DP组成,同时还包含了寄存器、共享存储、常量存储等单元。
-
SMX: Kepler架构中的SM
-
SMM: Maxwell架构中的SM
无论是SMM还是SMX还是SM都是一回事
-
TPC(Thread Processing Cluster)线程处理器簇:由SM和L1 Cache组成,存在于Tesla架构中。
-
TPC(Texture Processing Cluster)纹理处理器簇:出现在Pascal架构中。
Tesla架构的TPC:
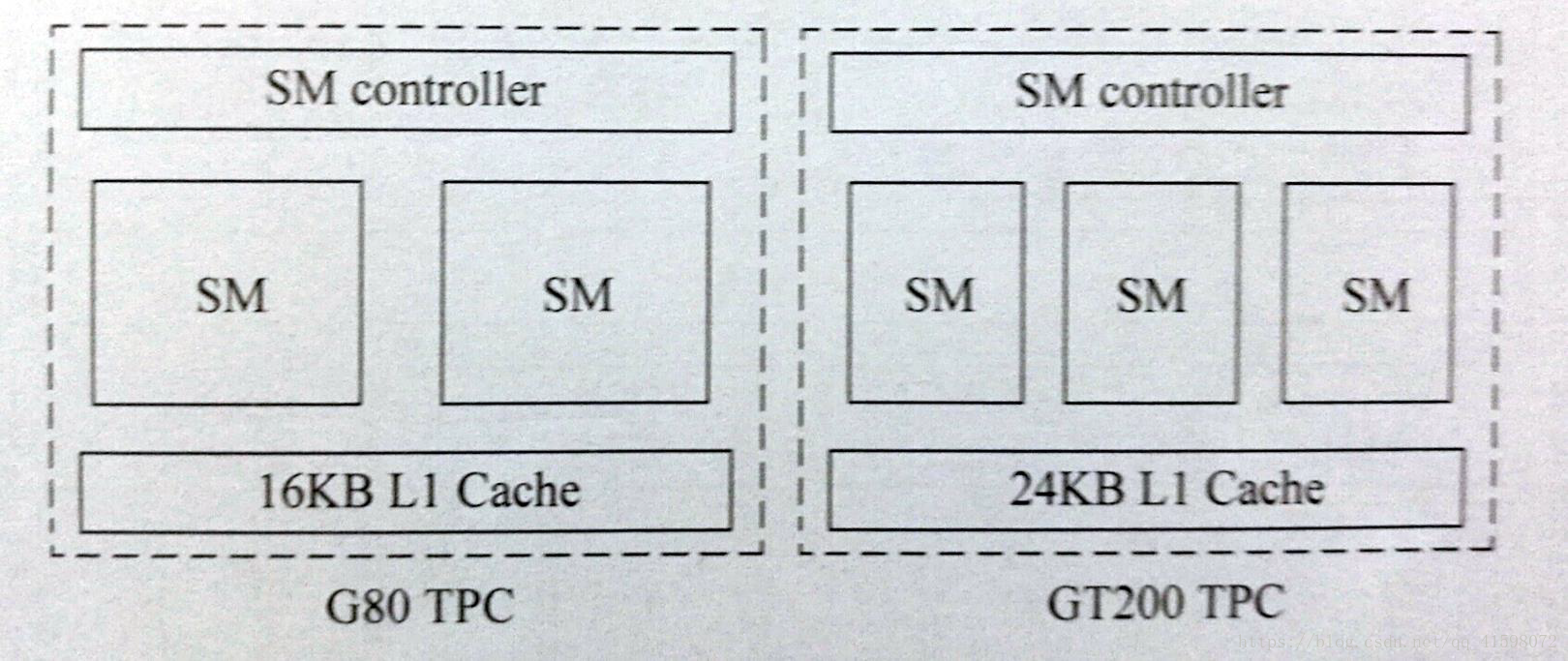
2~3个SM配合L1 Cache构成TPC,Tesla架构主要核心型号有G80和GT200 每个TPC均由一个SM控制器进行统一控制。
-
GPC(Graph Processing Cluster)图形处理器簇:类似于TPC,是介于整个GPU和SM间的硬件单元,始于Fermi构架。
-
SPA(Scalable streaming Processor Array)可扩展的流处理器阵列:所有处理核心和高速缓存的总和,包含所有的SM、TPC、GPC。与存储器系统共同组成GPU构架。
-
MMC(MeMoryController)存储控制器:控制存储访问的单元,合并访存。每个存储控制器可以支持一定位宽的数据合并访存。
-
ROP(raster operation processors)光栅操作单元
-
LD/ST(Load/Store Unit)存储单元
3.双warp调度机制
在每个SM前端都有两个线程束调度器(Warp Scheduler)和两个指令分发单元(Instruction Dispatch Unit),并且和SM 其它部分完全独立,指令分发单元和执行硬件之间有一个完整的交叉开关,每个单元都可以向SM内的任何单元分配线程。
SM 是以warp为单位调度线程的,每一个SM 的两个warp调度单元和两个指令分发单元,允许同时启动和执行两个warp。
Fermi双warp 调度机制可以同时启动两个warp,并且将每个warp的一条指令分发到一组16个CUDA Core上、16 个存取单元中或者是4 个SFU上执行。因为warp 彼此单独执行,所以Fermi的调度单元不需要检查指令流之间的相关性。
-
Warp(线程束):32线程 。SM内以warp为单位并行执行
-
–Warp内的线程执行同一条指令
-
(步调一致)
-
–Half-warp是存储操作的基本单位
- ***************************************************************************************************************
-
CUDA中grid、block、thread、warp与SM、SP的关系<-可以看这里
每一代架构内容太多了,如果有需要具体架构内容,可以留言