windows下如何查看磁盘IO性能
http://www.51testing.com/?uid-211722-action-viewspace-itemid-233892
服务器性能瓶颈如何判断、CPU瓶颈、内存泄漏、内存不足、硬件问题、磁盘瓶颈——LoadRunner负载测试之Windows常见性能计数器,分析服务器性能瓶颈
判断瓶颈
一、判断应用程序的问题
如果系统由于应用程序代码效率低下或者系统结构设计有缺陷而导致大量的上下文切换(context switches/sec显示的上下文切换次数太高)那么就会占用大量的系统资源,如果系统的吞吐量降低并且CPU的使用率很高,并且此现象发生时切换水平在15000以上,那么意味着上下文切换次数过高.
{kind=link}
contextswitches/sec
从图的整体看.context switches/sec变化不大,throughout曲线的斜率较高,并且此时的contextswitches/sec已经超过了15000.程序还是需要进一步优化.
二、判断CPU瓶颈
如果processor queue length显示的队列长度保持不变(>=2)个并且处理器的利用率%Processortime超过90%,那么很可能存在处理器瓶颈. 如果发现processor queue length显示的队列长度超过2,而处理器的利用率却一直很低,或许更应该去解决处理器阻塞问题,这里处理器一般不是瓶颈.
{kind=link}
CPU瓶颈
%processor time平均值大于95,processor queue length大于2.可以确定CPU瓶颈.此时的CPU已经不能满足程序需要.急需扩展.
CPU资源成为系统性能的瓶颈的征兆:
很慢的响应时间(slow response time)
CPU空闲时间为零(zero percent idle CPU)
过高的用户占用CPU时间(%User Time)
过高的系统占用CPU时间(%Priviliaged Time:长期大于90%或者95%)
长时间的有很长的运行进程队列(Process Queue Lengt:大于处理器个数+1)
三、判断内存泄露问题
内存问题主要检查应用程序是否存在内存泄漏,如果发生了内存泄漏,processprivate bytes计数器和processworking set 计数器的值往往会升高,同时avaiable bytes的值会降低.内存泄漏应该通过一个长时间的,用来研究分析所有内存都耗尽时,应用程序反应情况的测试来检验.
{kind=link}
内存泄露
图中可以看到该程序并不存在内存泄露的问题.内存泄露问题经常出现在服务长时间运转的时候,由于部分程序对内存没有释放,而将内存慢慢耗尽.也是提醒大家对系统稳定性测试的关注.
Windows资源监控中,如果ProcessPrivate Bytes计数器和ProcessWorking Set计数器的值在长时间内持续升高,同时MemoryAvailable bytes计数器的值持续降低,则很可能存在内存泄漏。
四、判断内存不足
如果队列长度(Avg.Disk Queue Length)增加的同时页面读取速率(Page Reads/sec)并未降低,则内存不足。
如果Available Mbytes(剩余物理内存数)的值很小(4 MB 或更小),则说明计算机上总的内存可能不足,或某程序没有释放内存。
五、硬件问题
请观察 Processor Interrupts/sec 计数器的值,该计数器测量来自输入/输出 (I/O) 设备的服务请求的速度。如果此计数器的值明显增加,而系统活动没有相应增加,则表明存在硬件问题。
六、I/O资源成为系统性能的瓶颈的征兆
IO Data Bytes/sec(处理从I/O操作读取/写入字节的速度。这个计数器为所有由本处理产生的包括文件、网络和设备I/O的活动计数。)
IO Data Operations/sec
IO Other Bytes/sec
IO Other Operations/sec
IO Read Bytes/sec(每秒IO读取字节数)
IO Read Operations/sec
IO Write Bytes/sec(每秒IO写出字节数)
IO Write Operations/sec
过高的磁盘利用率(high disk utilization)
太长的磁盘等待队列(Physical Disk Current Disk Queue Length,正在等待磁盘访问的系统请求数量)
等待磁盘I/O的时间所占的百分率太高(Average Disk Queue Length)
太高的物理I/O速率:large physical I/O rate(not sufficient in itself)
过低的缓存命中率(low buffer cache hit ratio(not sufficient in itself))
太长的运行进程队列,但CPU却空闲(Process Queue Length)
在方案运行中,如果出现了大于3个用户的业务操作失败,或出现了服务器shutdown的情况,则说明在当前环境下,系统承受不了当前并发用户的负载压力,那么最大并发用户数就是前一个没有出现这种现象的并发用户数
七、监视磁盘的使用情况
监视磁盘活动涉及两个主要方面:
监视磁盘 I/O 及检测过度换页
隔离 SQL Server 产生的磁盘活动
监视磁盘 I/O 及检测过度换页
可以对下面两个计数器进行监视以确定磁盘活动:
PhysicalDisk: % Disk Time
PhysicalDisk: Avg. Disk Queue Length
在系统监视器中,PhysicalDisk:% Disk Time计数器监视磁盘忙于读/写活动所用时间的百分比。如果PhysicalDisk: % Disk Time计数器的值较高(大于 90%),请检查PhysicalDisk: Current Disk Queue Length计数器了解等待进行磁盘访问的系统请求数量。等待 I/O 请求的数量应该保持在不超过组成物理磁盘的轴数的 1.5 到 2 倍。大多数磁盘只有一个轴,但独立磁盘冗余阵列 (RAID) 设备通常有多个轴。硬件 RAID 设备在系统监视器中显示为一个物理磁盘。通过软件创建的多个 RAID 设备在系统监视器中显示为多个实例。
可以使用Current Disk Queue Length和% Disk Time计数器的值检测磁盘子系统中的瓶颈。如果Current Disk Queue Length和% Disk Time计数器的值一直很高,则考虑下列事项:
使用速度更快的磁盘驱动器。
将某些文件移至其他磁盘或服务器。
如果正在使用一个 RAID 阵列,则在该阵列中添加磁盘。
如果使用 RAID 设备,% Disk Time计数器会指示大于 100% 的值。如果出现这种情况,则使用PhysicalDisk: Avg.Disk Queue Length计数器来确定等待进行磁盘访问的平均系统请求数量。
I/O 依赖的应用程序或系统可能会使磁盘持续处于活动状态。
监视 Memory: Page Faults/sec计数器可以确保磁盘活动不是由分页导致的。在 Windows 中,换页的原因包括:
配置进程占用了过多内存。
文件系统活动。
如果在同一硬盘上有多个逻辑分区,请使用Logical Disk计数器而非Physical Disk计数器。查看逻辑磁盘计数器有助于确定哪些文件被频繁访问。当发现磁盘有大量读/写活动时,请查看读写专用计数器以确定导致每个逻辑卷负荷增加的磁盘活动类型,例如,Logical Disk: Disk Write Bytes/sec。
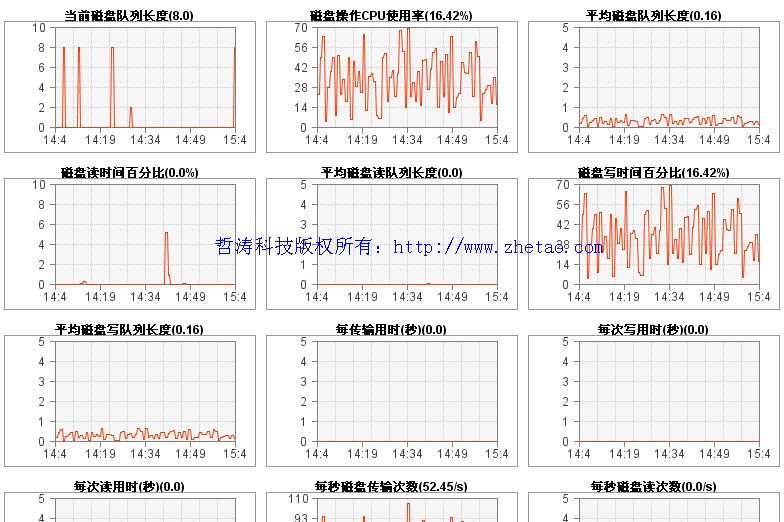
八、判断磁盘瓶颈
Disk Time和Avg.Disk Queue Length的值很高,而Page Reads/sec页面读取操作速率很低,则可能存在磁盘瓶径。
Physical Disk Disk Reads/sec and Disk Writes/sec
Physical Disk Current Disk Queue Length
Physical Disk % Disk Time
LogicalDisk % Free Space
测试磁盘性能时,将性能数据记录到另一个磁盘或计算机,以便这些数据不会干扰您正在测试的磁盘。
可能需要观察的附加计数器包括 Physical Disk Avg.Disk sec/Transfer 、Avg.DiskBytes/Transfer,和Disk Bytes/sec。
Avg.Disk sec/Transfer 计数器反映磁盘完成请求所用的时间。较高的值表明磁盘控制器由于失败而不断重试该磁盘。这些故障会增加平均磁盘传送时间。对于大多数磁盘,较高的磁盘平均传送时间是大于 0.3 秒。
也可以查看 Avg.Disk Bytes/Transfer 的值。值大于 20 KB 表示该磁盘驱动器通常运行良好;如果应用程序正在访问磁盘,则会产生较低的值。例如,随机访问磁盘的应用程序会增加平均 Disk sec/Transfer 时间,因为随机传送需要增加搜索时间。
Disk Bytes/sec 提供磁盘系统的吞吐率。
决定工作负载的平衡要平衡网络服务器上的负载,需要了解服务器磁盘驱动器的繁忙程度。使用 Physical Disk %Disk Time 计数器,该计数器显示驱动器活动时间的百分比。如果 % Disk Time 较高(超过90%),请检查 Physical Disk Current Disk Queue Length 计数器以查看正在等待磁盘访问的系统请求数量。等待 I/O 请求的数量应当保持在不大于组成物理磁盘的主轴数的 1.5 到2倍。
尽管廉价磁盘冗余阵列 (RAID) 设备通常有多个主轴,大多数磁盘有一个主轴。硬件 RAID设备在“系统监视器”中显示为一个物理磁盘;通过软件创建的 RAID 设备显示为多个驱动器(实例)。可以监视每个物理驱动器(而不是 RAID)的 Physical Disk 计数器,也可以使用 _Total 实例来监视所有计算机驱动器的数据。
使用 Current Disk Queue Length 和 % Disk Time 计数器来检测磁盘子系统的瓶颈。如果Current Disk Queue Length 和 % Disk Time 的值始终较高,可以考虑升级磁盘驱动器或将某些文件移动到其他磁盘或服务器。
Windows操作系统:
(1)%Disk Time %:指所选磁盘驱动器忙于为读或写入请求提供服务所用的时间的百分比。如果Physical Disk % Disk Time 、Physical Disk Avg.Disk Queue Length 、Memory Pages/sec三个计数器都比较大,那么硬盘不是瓶颈。如果只有%Disk Time比较大,另外两个都比较适中,硬盘可能会是瓶颈。在记录该计数器之前,请在Windows 2000 的命令行窗口中运行diskperf -yD。若数值持续超过80%,则可能是内存泄漏。
(2)Avg.Disk Queue Length:指读取和写入请求(为所选磁盘在实例间隔中列队的)的平均数。该值应不超过磁盘数的1.5~2 倍。要提高性能,可增加磁盘。注意:一个Raid Disk实际有多个磁盘。
(3)Average Disk Read/Write Queue Length: 指读取(写入)请求(列队)的平均数。
(4)Disk Reads(Writes)/s: 物理磁盘上每秒钟磁盘读、写的次数。两者相加,应小于磁盘设备最大容量。
(5)Average Disksec/Read: 指以秒计算的在此盘上读取数据的所需平均时间。
(6)verage Disk sec/Transfer: 指以秒计算的在此盘上写入数据的所需平均时间。
(1)%Disk Time %:指所选磁盘驱动器忙于为读或写入请求提供服务所用的时间的百分比。如果Physical Disk % Disk Time 、Physical Disk Avg.Disk Queue Length 、Memory Pages/sec三个计数器都比较大,那么硬盘不是瓶颈。如果只有%Disk Time比较大,另外两个都比较适中,硬盘可能会是瓶颈。在记录该计数器之前,请在Windows 2000 的命令行窗口中运行diskperf -yD。若数值持续超过80%,则可能是内存泄漏。
(2)Avg.Disk Queue Length:指读取和写入请求(为所选磁盘在实例间隔中列队的)的平均数。该值应不超过磁盘数的1.5~2 倍。要提高性能,可增加磁盘。注意:一个Raid Disk实际有多个磁盘。
(3)Average Disk Read/Write Queue Length: 指读取(写入)请求(列队)的平均数。
(4)Disk Reads(Writes)/s: 物理磁盘上每秒钟磁盘读、写的次数。两者相加,应小于磁盘设备最大容量。
(5)Average Disksec/Read: 指以秒计算的在此盘上读取数据的所需平均时间。
(6)verage Disk sec/Transfer: 指以秒计算的在此盘上写入数据的所需平均时间。
| 通常,我们很容易观察到数据库服务器的内存和CPU压力。但是对I/O压力没有直观的判断方法。磁盘有两个重要的参数: Seek time、 Rotational latency。正常的I/O计数为:①1000/(Seek time+Rotational latency)*0.75,在此范围内属正常。当达到85%的I/O计数以上时则基本认为已经存在I/O瓶劲。理论情况下,磁盘的随机读计数为125、顺序读计数为225。对于数据文件而言是随机读写,日志文件是顺序读写。因此,数据文件建议存放于RAID5上,而日志文件存放于RAID10或RAID1中。 下面假设在有4块硬盘的RAID5中观察到的Physical Disk性能对象的部分值: Avg. Disk Queue Length 12 Avg. Disk Sec/Read .035 Avg. Disk Sec/Write .045 Disk Reads/sec 320 Disk Writes/sec 100 Avg. Disk Queue Length,12/4=3,每块磁盘的平均队列建议不超过2。 Avg. Disk Sec/Read一般不要超过11~15ms。 Avg. Disk Sec/Write一般建议小于12ms。 从上面的结果,我们看到磁盘本身的I/O能力是满足我们的要求的,原因是因为有大量的请求才导致队列等待,这很可能是因为你的SQL语句导致大量的表扫描所致。在进行优化后,如果还是不能达到要求,下面的公式可以帮助你计算使用几块硬盘可以满足这样的并发要求: Raid 0 -- I/Os per disk = (reads + writes) / number of disks Raid 1 -- I/Os per disk = [reads + (2 * writes)] / 2 Raid 5 -- I/Os per disk = [reads + (4 * writes)] / number of disks Raid 10 -- I/Os per disk = [reads + (2 * writes)] / number of disks 我们得到的结果是:(320+400)/4=180,这时你可以根据公式①来得到磁盘的正常I/O值。假设现在正常I/O计数为125,为了达到这个结果:720/125=5.76。就是说要用6块磁盘才能达到这样的要求。 但是上面的Disk Reads/sec和Disk Writes/sec是个很难正确估算的值。因此只能在系统比较忙时,大概估算一个平均值,作为计算公式的依据。另一个是你很难从客户那里得到Seek time、 Rotational latency参数的值,这也只能用理论值125进行计算。 |
通常,我们很容易观察到数据库服务器的内存和CPU压力。但是对I/O压力没有直观的判断方法。磁盘有两个重要的参数: Seek time、 Rotational latency。正常的I/O计数为:①1000/(Seek time+Rotational latency)*0.75,在此范围内属正常。当达到85%的I/O计数以上时则基本认为已经存在I/O瓶劲。理论情况下,磁盘的随机读计数为125、顺序读计数为225。对于数据文件而言是随机读写,日志文件是顺序读写。因此,数据文件建议存放于RAID5上,而日志文件存放于RAID10或RAID1中。
下面假设在有4块硬盘的RAID5中观察到的Physical Disk性能对象的部分值:
Avg. Disk Queue Length 12
Avg. Disk Sec/Read .035
Avg. Disk Sec/Write .045
Disk Reads/sec 320
Disk Writes/sec 100
Avg. Disk Queue Length,12/4=3,每块磁盘的平均队列建议不超过2。
Avg. Disk Sec/Read一般不要超过11~15ms。
Avg. Disk Sec/Write一般建议小于12ms。
从上面的结果,我们看到磁盘本身的I/O能力是满足我们的要求的,原因是因为有大量的请求才导致队列等待,这很可能是因为你的SQL语句导致大量的表扫描所致。在进行优化后,如果还是不能达到要求,下面的公式可以帮助你计算使用几块硬盘可以满足这样的并发要求:
Raid 0 -- I/Os per disk = (reads + writes) / number of disks
Raid 1 -- I/Os per disk = [reads + (2 * writes)] / 2
Raid 5 -- I/Os per disk = [reads + (4 * writes)] / number of disks
Raid 10 -- I/Os per disk = [reads + (2 * writes)] / number of disks
我们得到的结果是:(320+400)/4=180,这时你可以根据公式①来得到磁盘的正常I/O值。假设现在正常I/O计数为125,为了达到这个结果:720/125=5.76。就是说要用6块磁盘才能达到这样的要求。
但是上面的Disk Reads/sec和Disk Writes/sec是个很难正确估算的值。因此只能在系统比较忙时,大概估算一个平均值,作为计算公式的依据。另一个是你很难从客户那里得到Seek time、 Rotational latency参数的值,这也只能用理论值125进行计算。
下面假设在有4块硬盘的RAID5中观察到的Physical Disk性能对象的部分值:
Avg. Disk Queue Length 12
Avg. Disk Sec/Read .035
Avg. Disk Sec/Write .045
Disk Reads/sec 320
Disk Writes/sec 100
Avg. Disk Queue Length,12/4=3,每块磁盘的平均队列建议不超过2。
Avg. Disk Sec/Read一般不要超过11~15ms。
Avg. Disk Sec/Write一般建议小于12ms。
从上面的结果,我们看到磁盘本身的I/O能力是满足我们的要求的,原因是因为有大量的请求才导致队列等待,这很可能是因为你的SQL语句导致大量的表扫描所致。在进行优化后,如果还是不能达到要求,下面的公式可以帮助你计算使用几块硬盘可以满足这样的并发要求:
Raid 0 -- I/Os per disk = (reads + writes) / number of disks
Raid 1 -- I/Os per disk = [reads + (2 * writes)] / 2
Raid 5 -- I/Os per disk = [reads + (4 * writes)] / number of disks
Raid 10 -- I/Os per disk = [reads + (2 * writes)] / number of disks
我们得到的结果是:(320+400)/4=180,这时你可以根据公式①来得到磁盘的正常I/O值。假设现在正常I/O计数为125,为了达到这个结果:720/125=5.76。就是说要用6块磁盘才能达到这样的要求。
但是上面的Disk Reads/sec和Disk Writes/sec是个很难正确估算的值。因此只能在系统比较忙时,大概估算一个平均值,作为计算公式的依据。另一个是你很难从客户那里得到Seek time、 Rotational latency参数的值,这也只能用理论值125进行计算。
SUM服务器监控软件对Windows磁盘的IO监控是目前所有监控软件中最全面。每一项监控内容均为Windows磁盘IO最为核心的项目,是运行磁盘操作量大的应用服务器必须监控的项目。