两个列向量相乘怎么计算_矩阵:行主序、列主序、行向量、列向量
看龙书的时候发现一个矩阵在传入Shader之前都要转置一下,很好奇为什么要有一步这样的操作。

行主序和列主序
行主序指矩阵在内存中逐行存储,列主序指矩阵在内存中逐列存储。
行主序矩阵内存布局:

列主序矩阵内存布局:

行向量和列向量
行向量指的是把向量当成一个一行n列的矩阵,列向量指的是把向量当成一个n行一列的矩阵。
左乘和右乘
矩阵“左乘”:矩阵和向量相乘时放在左边。
矩阵“右乘”:矩阵和向量相乘时放在右边。
对于同一个矩阵和同一个向量,“左乘”和“右乘”的结果是不一样的,这是因为矩阵不满足交换律。
总结
HLSL中默认是使用列主序存储矩阵的,也就是矩阵的每一列存储在一个常量寄存器中,此时使用矩阵“右乘”效率更高,因为一个float4和一个4x4的矩阵相乘只需要四个点乘就能计算出结果:
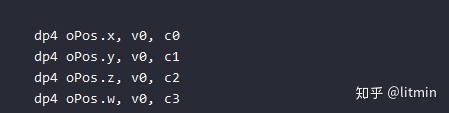
如果使用“左乘”,结果就是:
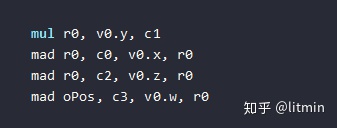
HLSL中可以通过 #pragmapack_matrix指令或者row_major、column_major keyword来修改矩阵的存储方式。在Shader执行之前会加载矩阵的数据,行主序还是列主序的设置只会影响Shader读取输入的矩阵数据,矩阵读取到Shader后矩阵是行主序还是列主序就不会有其他影响(只会影响计算的效率),比如通过代码获取某个元素的值,我们要获取第一行第三列的值,都是通过_m02来获取。
但是为了使效率最高,对于列主序存储的矩阵我们要“右乘”,对于行主序存储的矩阵我们要“左乘”。
因为DirectXMath中使用行主序矩阵,向量和矩阵相乘使用“左乘”,要想在Shader中读取正确的矩阵,我们就要转置一下,比如一个平移变换,在DirectXMath中是这样:

矩阵“左乘”表示平移变换:

那在HLSL中使用的是列主序矩阵,为了效率我们使用“右乘”,要表示相同的平移变换,就要传入上面矩阵的转置矩阵:
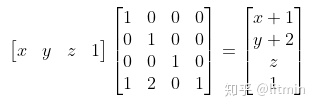
所以在把DirectXMath的矩阵传入HLSL时需要传入原矩阵的转置。
Reference:
https://docs.microsoft.com/zh-cn/windows/win32/direct3dhlsl/dx-graphics-hlsl-per-component-math?redirectedfrom=MSDNdocs.microsoft.comHLSL mul() and row/column major matricies in directxwww.gamedev.net更多相关:
-
ORB-SLAM点云地图中相机的位姿初始化,无论算法工作在平面场景,还是非平面场景下,都能够完成初始化的工作。其中主要是使用了适用于平面场景的单应性矩阵H和适用于非平面场景的基础矩阵F,程序中通过一个评分规则来选择适合的模型,恢复相机的旋转矩阵R和平移矩阵t那么下面主要讲解关于对极几何中的基础矩阵,本质矩阵,和单应矩阵之间的区别与联...
-
矩阵可分为稠密矩阵和稀疏矩阵,对于稀疏矩阵而言,使用同样的内存来存储这个矩阵显然是对内存的浪费,那么我们就可以想办法将矩阵中所有的o元素挥着不相关元素剔除,怎么剔除,第一种方法是通过三个一维矩阵来存储原二维矩阵中的所有非0元素,三个矩阵分别为value、column、row, value 数组存储所有的非零元素, column 数...
-
void convertTo( OutputArray m, int rtype, double alpha=1, double beta=0 ) const; m – 目标矩阵。如果m在运算前没有合适的尺寸或类型,将被重新分配。rtype – 目标矩阵的类型。因为目标矩阵的通道数与源矩阵一样,所以rtype也可以看做是目标...
-
https://blog.csdn.net/jiangdf/article/details/8460012 glMatrixMode()函数的参数,这个函数其实就是对接下来要做什么进行一下声明,也就是在要做下一步之前告诉计算机我要对“什么”进行操作了,这个“什么”在glMatrixMode的“()”里的选项(参数)有3种模式: GL...
-
因为要设计AR系统,但是纠结是用cube还是Sphere mapping,cube mapping比较熟悉,但是网上关于sphere mapping的资料少之又少,只怪智商太低太原理的又看不懂,所以花了很长时间,主要是靠下面几个链接和那篇论文理解透的。总之,还是用Cube吧。。。。 参考资料: http://www.twinkli...
-
2009年3月17日 阅读评论 发表评论 这个应该算是补遗漏,去年在MSN Space上写过一篇关于凹凸贴图的,当时写了半天其实写的一点也不明白,呵呵,因为有很多细节其实我也没搞太清楚,现在这里发一点关于其中一个用来完成凹凸贴图计算中将光向量转向顶点所在的切向量的细节,这个在当时的例子中是通过API实现的,这里简单描述一...