协方差及PCA降维计算
PCA(Principal Component Analysis,主成分分析),PCA是一种无监督算法,也就是我们不需要标签也能对数据做降维,这就使得其应用范围更加广泛了。那么PCA的核心思想是什么呢?这里我们提到了方差,咱们可以想象一下,如果一群人都堆叠在一起,我们想区分他们是不是比较困难,但是如果这群人站在马路两侧,我们就可以很清晰的判断出来应该这是两伙人。所以基于方差我们可以做的就是让方差来去判断咱们数据的拥挤程度,在这里我们认为方差大的应该辨识度更高一些,因为分的比较开(一条马路给隔开啦)。
降维致力于解决三类问题。
1. 降维可以缓解维度灾难问题;
2. 降维可以在压缩数据的同时让信息损失最小化;
3. 理解几百个维度的数据结构很困难,两三个维度的数据通过可视化更容易理解。


就像我们图上面的,我说有一个向量(3,2),但是为什么这个向量是这样的表示呢?因为它在我们的做标系中,如果我把坐标系换了,它就不是(3,2)了。作为基,首先的一个前提就是要相互垂直,或者说内积为0,因为X和Y它们表达的分别是两种指标,我们不希望它们之间内部存在任何联系,所以必须让他们内积为0,这样就是各自独立的啦!

所谓的降维就是要把我们的数据投影到最合适的基中
方差,协方差和协方差矩阵
方差(Variance)是度量一组数据的分散程度。方差是各个样本与样本均值的差的平方和的均值:

协方差(Covariance)是度量两个变量的变动的同步程度,也就是度量两个变量线性相关性程度。如果两个变量的协方差为0,则统计学上认为二者线性无关。注意两个无关的变量并非完全独立,只是没有线性相关性而已。计算公式如下:

如果协方差大于0表示一个变量增大是另一个变量也会增大,即正相关,协方差小于0表示一个变量增大是另一个变量会减小,即负相关。
对于二维数据降维到一维数据,按照上面的方法找到方差值最大就行。但是对于高维数据来说,仅此一个条件并不能完全决定。三维数据降维到二维时,首先我们希望找到一个方向使得投影后方差最大,这样就完成了第一个方向的选择,继而我们选择第二个投影方向。
如果我们还是单纯只选择方差最大的方向,很明显,这个方向与第一个方向应该是“几乎重合在一起”,显然这样的维度是没有用的,因此,应该有其他约束条件。从直观上说,让两个字段尽可能表示更多的原始信息,我们是不希望它们之间存在(线性)相关性的,因为相关性意味着两个字段不是完全独立,必然存在重复表示的信息。数学上协方差表示两组数据的相关性:
假设有一个矩阵:

然后我们用X乘以X的转置,并乘上系数1/m:

这个矩阵对角线上的两个元素分别是两个字段的方差,而其它元素是a和b的协方差。两者被统一到了一个矩阵的。根据矩阵相乘的运算法则,这个结论很容易被推广到一般情况:
设我们有m个n维数据记录,将其按列排成n乘m的矩阵X,设C=1mXXT,则C是一个对称矩阵,其对角线分别个各个字段的方差,而第i行j列和j行i列元素相同,表示i和j两个字段的协方差。
PCA算法步骤:
设有m条n维数据。
1)将原始数据按列组成n行m列矩阵X
2)将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值
3)求出协方差矩阵
4)求出协方差矩阵的特征值及对应的特征向量
5)将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P
6)Y=PX即为降维到k维后的数据
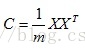
实例:

对其进行0均值化处理:

求协方差矩阵:

求解后特征值为:

特征值和特征向量的求法是这样的:假设A

根据前面的公式AA乘以特征向量,必然等于特征值乘以特征向量。我们建立特征方程求解:

从特征方程可以看出,矩阵与单位矩阵和特征值乘积的矩阵行列式为0,即:

矩阵的两个特征值都等于-1。现在再用特征值来解特征向量。 把λ=−1带入:
![]()
得到:

所以:


对特征值分解后按照特征值大小排序,取前多少个。通过特征值排列 ,我们可以得到数据在这些特征向量上的分布和多样性。
其对应的特征向量分别是:

其中对应的特征向量分别是一个通解,c1和c2可取任意实数。那么标准化后的特征向量为:

因此我们的矩阵P是:

可以验证协方差矩阵C的对角化:

最后我们用P的第一行乘以数据矩阵,就得到了降维后的表示:

更多相关:
-
一、统计学的基本概念 统计学里最基本的概念就是样本的均值、方差、标准差。首先,我们给定一个含有n个样本的集合,下面给出这些概念的公式描述: 均值: 标准差: 方差: 均值描述的是样本集合的中间点,它告诉我们的信息是有限的,而标准差给我们描述的是样本集合的各个样本点到均值的距离之平均。 以这两个集合为例,[0, 8, 12, 20]和...
-
看龙书的时候发现一个矩阵在传入Shader之前都要转置一下,很好奇为什么要有一步这样的操作。行主序和列主序行主序指矩阵在内存中逐行存储,列主序指矩阵在内存中逐列存储。行主序矩阵内存布局:列主序矩阵内存布局:行向量和列向量行向量指的是把向量当成一个一行n列的矩阵,列向量指的是把向量当成一个n行一列的矩阵。左乘和右乘矩阵“左乘”:矩阵和向...
-
ORB-SLAM点云地图中相机的位姿初始化,无论算法工作在平面场景,还是非平面场景下,都能够完成初始化的工作。其中主要是使用了适用于平面场景的单应性矩阵H和适用于非平面场景的基础矩阵F,程序中通过一个评分规则来选择适合的模型,恢复相机的旋转矩阵R和平移矩阵t那么下面主要讲解关于对极几何中的基础矩阵,本质矩阵,和单应矩阵之间的区别与联...
-
矩阵可分为稠密矩阵和稀疏矩阵,对于稀疏矩阵而言,使用同样的内存来存储这个矩阵显然是对内存的浪费,那么我们就可以想办法将矩阵中所有的o元素挥着不相关元素剔除,怎么剔除,第一种方法是通过三个一维矩阵来存储原二维矩阵中的所有非0元素,三个矩阵分别为value、column、row, value 数组存储所有的非零元素, column 数...
-
void convertTo( OutputArray m, int rtype, double alpha=1, double beta=0 ) const; m – 目标矩阵。如果m在运算前没有合适的尺寸或类型,将被重新分配。rtype – 目标矩阵的类型。因为目标矩阵的通道数与源矩阵一样,所以rtype也可以看做是目标...
-
https://blog.csdn.net/jiangdf/article/details/8460012 glMatrixMode()函数的参数,这个函数其实就是对接下来要做什么进行一下声明,也就是在要做下一步之前告诉计算机我要对“什么”进行操作了,这个“什么”在glMatrixMode的“()”里的选项(参数)有3种模式: GL...
-
英语的重要性,毋庸置疑!尤其对广大职场人士,掌握英语意味着就多了一项竞争的技能。那,对于我们成人来说,时间是最宝贵的。如何短时间内在英语方面有所突破,这是我们最关心的事情。英语学习,到底有没有捷径可以走,是否可以速成?周老师在这里明确告诉大家,英语学习,没有绝对的捷径走,但是可以少走弯路。十多年的教学经验告诉我们,成功的学习方法可以借...
-
展开全部 其实IDLE提供了一个显32313133353236313431303231363533e78988e69d8331333365663438示所有行和所有字符的功能。 我们打开IDLE shell或者IDLE编辑器,可以看到左下角有个Ln和Col,事实上,Ln是当前光标所在行,Col是当前光标所在列。 我们如果想得到文件代码...
-
前言[1]从 Main 方法说起[2]走进 Tomcat 内部[3]总结[4]《Java 2019 超神之路》《Dubbo 实现原理与源码解析 —— 精品合集》《Spring 实现原理与源码解析 —— 精品合集》《MyBatis 实现原理与源码解析 —— 精品合集》《Spring MVC 实现原理与源码解析 —— 精品合集》《Spri...
-
【本文摘要】【注】本文所述内容为学习Yjango《学习观》相关视频之后的总结,观点归Yjango所有,本文仅作为学习之用。阅读本节,会让你对英语这类运动类知识的学习豁然开朗,你会知道英语学习方面,我们的症结所在。学习英语这类运动类知识,需要把握四个原则第一,不要用主动意识。第二,关注于端对端第三,输入输出符合实际情况第四,通过多个例子...
-
点云PCL免费知识星球,点云论文速读。文章:RGB-D SLAM with Structural Regularities作者:Yanyan Li , Raza Yunus , Nikolas Brasch , Nassir Navab and Federico Tombari编译:点云PCL代码:https://github.co...