Python可以调用Gpu吗_加快Python算法的四个方法:Numba篇

CDA数据分析师 出品
相信大家在做一些算法经常会被庞大的数据量所造成的超多计算量需要的时间而折磨的痛苦不已,接下来我们围绕四个方法来帮助大家加快一下Python的计算时间,减少大家在算法上的等待时间。今天给大家介绍Numba这一块的内容。
1.简介
所以什么是Numba呢?Numba是Python的即时编译器,也就是说当你调用Python
函数时,你的全部或部分代码都会被计时转换成为机器码进行执行,然后它就会以你的本机机器码速度运行,Numba由Anaconda公司赞助,并得到了许多组织的支持。
使用Numba,你可以加速所有以集中计算的、计算量大的python函数(例如循环)的速度。它还支持numpy库!因此,你也可以在计算中使用numpy,并加快整体计算的速度,因为python中的循环非常慢。你还可以使用python标准库中的数学库的许多功能,例如sqrt等。
2.为什么选择Numba?
所以,为什么要选择Numba?特别是当存在有许多其他编译器,例如cython或任何其他类似的编译器,或类似pypy的东西时。
选择Numba的理由很简单,那就是因为你不需要离开使用Python编写代码的舒适区。是的,你没看错,你不需要为了加速数据的运行速度而改变你的代码,这与从具有类型定义的相似cython代码获得的加速相当。那不是更好么?
你只需要在函数周围添加一个熟悉的Python功能,也就是装饰器(包装器)。目前类的装饰器也在开发之中。
所以,你只需要添加一个装饰器就可以了。例如:
from numba import jit@jitdef function(x): # 循环或数值密集型的计算 return x
它看起来仍然像是纯python代码,不是吗?
3. Numba如何工作?
Numb使用LLVM编译器基础结构,从纯Python代码生成优化的机器码。使用Numba的代码运行速度与C,C ++或Fortran中的类似代码相媲美。
这是代码的编译方式:
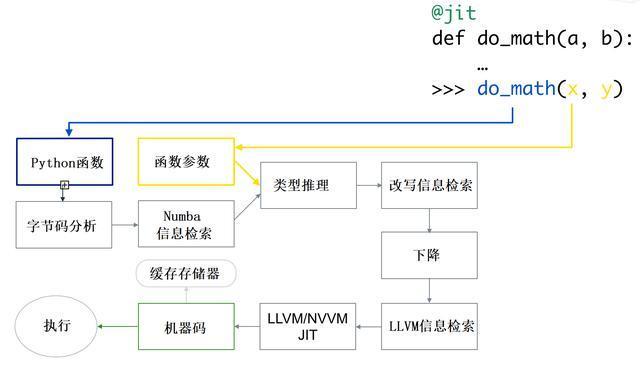
首先,获取,优化Python函数并将其转换为Numba的中间表示形式,然后类似于Numpy的类型推断一样进行类型判断(因此python float为float64),然后将其转换为LLVM可解释的代码。然后,该代码被馈送到LLVM的即时编译器以发出机器代码。
你可以根据需要在运行时生成代码或在CPU(默认)或GPU上导入代码。
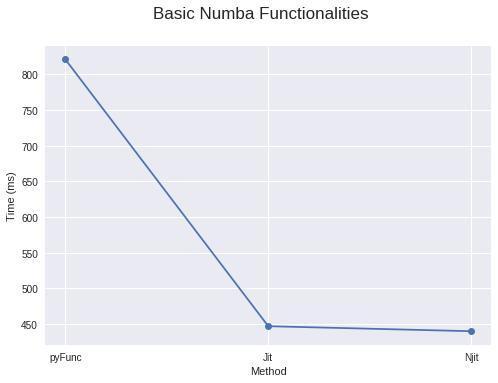
4.使用基本的Numba功能(只需要@jit!)
小菜一碟!
为了获得最佳的性能,numba建议在你的jit包装器中使用参数nopython = True,但它根本不会使用Python解释器。或者你也可以使用@njit。如果你使用nopython = True的包装器失败并出现错误,则可以使用简单的@jit包装器,该包装器将编译部分代码,对其进行循环,然后将其转换为函数,再编译为机器码,然后将其余部分交给python解释器。
因此,你只需要执行以下操作:
from numba import njit, jit@njit # 或者@jit(nopython=True)def function(a, b): # 循环或数值密集型计算 return result
使用@jit时,请确保你的代码具有Numba可以编译的内容,例如计算密集型循环,使用它支持的库(Numpy)及其支持的函数。否则,它将无法编译任何内容。
首先,numba在首次用作机器代码后还会缓存这些函数。因此,在第一次使用之后,它会变得更快,因为你无需再次编译该代码,因为你使用的参数类型和你之前使用的相同。
而且,如果你的代码是可以并行化运行的,那么也可以将parallel = True作为参数传递,但是必须跟参数nopython = True结合使用。目前,它仅可以在CPU上工作。
你也可以指定你想要的函数签名,但是它不会编译你给他的任何其他类型的参数,比如:
你还可以指定你希望函数具有的函数签名,但是对于提供给它的任何其他类型的参数,它将不会编译。例如:
from numba import jit, int32@jit(int32(int32, int32))def function(a, b): #循环或数值型密集型计算 return result#或者你还没有导入类型的名称#你可以将他们作为字符串传递@jit('int32(int32, int32)')def function(a, b): #循环或数值型密集型计算 return result
现在,你的函数将只接受两个int32并返回一个int32。这样,你可以更好地控制自己的函数。你甚至可以根据需要传递多个)函数签名。
你还可以使用numba提供的其他装饰器:
1. @vectorize:允许将标量参数用作numpy ufunc,
1. @guvectorize:产生NumPy广义ufuncs
1. @stencil:将函数声明为类似模板操作的内核,
1. @jitclass:对于支持jit的类,
1. @cfunc:声明一个用作本机回调的函数(从C / C ++等调用),
1. @overload:注册自己的函数实现以在nopython模式下使用,例如@overload(scipy.special.j0)。
Numba还具有预先(AOT)编译功能,它生成一个编译后的扩展模块,该模块不依赖于Numba。但:
1. 它只允许使用常规函数(不能使用ufuncs),
1. 你必须指定一个函数签名。你只能指定一个,因为许多指定使用不同的名称。
它还会为你的CPU架构系列生成通用代码。
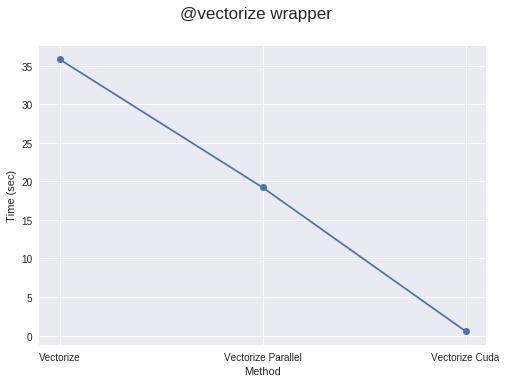
5. @vectorize包装器
通过使用@vectorize包装器,你可以将对标量进行操作的函数转换为数组,例如,如果你正在使用math仅在标量上运行的python 库,则可以对数组使用。这提供了类似于numpy数组操作(ufuncs)的速度。例如:
@vectorizedef func(a, b): # 对标量进行运算 return result
你还可以将target参数传递给此包装器,该包装器的值可以等于parallel用于并行化代码,cuda用于在cuda / GPU上运行代码的值。
@vectorize(target="parallel")def func(a, b): # 对标量进行运算 return result
假设你的代码具有足够的计算密集性或数组足够大,则使用numpy进行矢量化target = "parallel"或"cuda"通常比numpy实现运行得更快。如果不是这样的话,这将花费大量时间来制作线程和为不同的线程拆分元素,这可能会超过整个过程的实际计算时间。因此,工作应该足够繁重才能加快速度。
6.在GPU上运行函数
你也可以像包装器一样传递@jit来在cuda / GPU上运行函数。为此,你将必须numba库中导入cuda。但是在GPU上运行代码不会像以前那样容易。为了在GPU上的数百个甚至数千个线程上运行函数,它需要完成一些初始计算。你必须声明和管理网格,块和线程的层次结构。但是这并不难。
要在GPU上执行一个函数,你必须定义一个 kernel function(内核函数)或一个device function(设备函数)。首先,让我们看一下kernel function(核函数)。
关于内核函数需要记住的几点:
a)内核在被调用时显式声明其线程层次结构,即块数和每个块的线程数。你可以编译一次内核,然后使用不同的块和网格大小多次调用它。
b)内核无法返回值。因此,你将不得不在原始数组上进行更改,或者传递另一个数组来存储结果。对于计算标量,你将必须传递一个一元数组。
# 定义一个内核函数from numba import [email protected] func(a, result): # 然后是一些CUDA相关的计算 # 你的计算密集的代码 # 你的答案储存在'result'中
因此,要启动内核,你将必须传递两个东西:
1. 每个块的线程数,
1. 块的数量。
例如:
threadsperblock = 32blockspergrid = (array.size + (threadsperblock - 1)) // threadsperblockfunc[blockspergrid, threadsperblock](array)
每个线程中的内核函数必须知道它在哪个线程中,知道它负责数组的哪个元素。通过Numba,只需一次调用即可轻松获得元素的这些位置。
@cuda.jitdef func(a, result): pos = cuda.grid(1) # 对一维数组 # x, y = cuda.grid(2) # 对二维数组 if pos < a.shape[0]: result[pos] = a[pos] * (some computation)
为了节省将numpy数组复制到特定设备并再次将结果存储在numpy数组中的时间,Numba提供了一些函数来声明和发送数组到特定的设备,如:numba.cuda.device_array,numba.cuda.device_array_like,numba.cuda.to_device,等等,以节省不必要的时间复制到cpu(除非必要)。
另一方面,device function只能从设备内部(通过内核或其他设备函数)好处是,你可以从device function返回一个值。因此,你可以使用此函数的返回值来计算kernel function或device function的一些内容。
from numba import [email protected](device=True)def device_function(a, b): return a + b
Numba 在其cuda库中还具有原子操作,随机数生成器,共享内存实现(以加快数据访问速度)等。
ctypes / cffi / cython互操作性:
· cffi- 在nopython模式下支持CFFI函数的调用。
· ctypes — 在nopython模式下支持ctypes包装器函数的调用…
· Cython导出的函数是可调用的。
下一期我们来看加快Python算法的另一种方法——数据并行化!
(1)获取更多优质内容及精彩资讯,可前往:https://www.cda.cn/?seo

(2)了解更多数据分析师领域的优质课程:

更多相关:
-
草色新雨中, 松声晚窗里。之前我们学习 Power Query 都是用鼠标就完成了很多复杂的操作。虽然 PowerQuery 已经将大部分常用功能内置成到功能区。基本能完成我们大部分的报表自动化功能。但是总有些复杂的或者个性化的问题是开发团队没有预先想到的,这时我们就需要学习 M 语言。一、M 语言在哪里?M语言的函数公式有三个地...
-
前言从2020年3月份开始,计划写一系列文档--《小白从零开始学编程》,记录自己从0开始学习的一些东西。第一个系列:python,计划从安装、环境搭建、基本语法、到利用Django和Flask两个当前最热的web框架完成一个小的项目第二个系列:可能会选择Go语言,也可能会选择Vue.js。具体情况待定,拭目以待吧。。。基本概念表达式表...
-
1.1函数1.1.1什么是函数函数就是程序实现模块化的基本单元,一般实现某一功能的集合。函数名:就相当于是程序代码集合的名称参数:就是函数运算时需要参与运算的值被称作为参数函数体:程序的某个功能,进行一系列的逻辑运算return 返回值:函数的返回值能表示函数的运行结果或运行状态。1.1.2函数的作用函数是组织好的,可重复使用的,用来...
-
原标题:基于Python建立深度神经网络!你学会了嘛?图1 神经网络构造的例子(符号说明:上标[l]表示与第l层;上标(i)表示第i个例子;下标i表示矢量第i项)单层神经网络图2 单层神经网络示例神经元模型是先计算一个线性函数(z=Wx+b),接着再计算一个激活函数。一般来说,神经元模型的输出值是a=g(Wx+b),其中g是激活函数(...
-
在学习MySQL的时候你会发现,它有非常多的函数,在学习的时候没有侧重。小编刚开始学习的时候也会有这个感觉。不过,经过一段时间的学习之后,小编发现尽管函数有很多,但是常用的却只有那几个。今天小编就把常用的函数汇总一下,为大家能够能好的学习MySQL中的函数。MySQL常使用的函数大概有四类。时间函数、数学函数、字符函数、控制函数。让我...
-
nan 是not a number ,inf是无穷大 numpy.nan_to_num(x): 使用0代替数组x中的nan元素,使用有限的数字代替inf元素...
-
简介 Simple Reference 基础CUDA示例,适用于初学者, 反映了运用CUDA和CUDA runtime APIs的一些基本概念.Utilities Reference 演示如何查询设备能力和衡量GPU/CPU 带宽的实例程序。Graphics Reference 图形化示例展现的是 CUDA, OpenGL,...
-
在做开发的过程中难免需要给内核及下载的一些源码打补丁,所以我们先学习下Linux下使用如如何使用diff制作补丁以及如何使用patch打补丁。...
-
我在调研ATS 4.2.3挂载SSD的过程中,遇到很多坑,特此详细记录我摸索的主要过程,以便大家以后避免之。 基本思路可以完全照搬参考文献[2][3] 下面的安装假定是以root用户身份进行的,Linux服务器已经安装好系统,磁盘已经做好分区。 首先需要认识我们的Linux服务器的硬件配置和软件情况 硬件配置: DELL...
-
该博文整理一些在使用stl编程过程中遇到的小经验: 1.在多线程环境下面打印调试,如何使用cout及时刷新到屏幕上? 在C中我们经常这样使用: printf("Hello World "); fflush(stdout); 如果使用stl,我们可以这样使用: cout << "Hello World" << endl <...
-
THE START更新堪称轻量级MATLAB的一款软件最新版-Maplesoft Maple 2019.2 中文版。Maple是符号和数字计算环境,也是一种多范式编程语言,由Maplesoft开发,还涵盖了技术计算的其他方面,包括可视化,数据分析,矩阵计算和MATLAB连接。MapleSim工具箱添加了用于多域物理建模和代码生成的...
-
同学们,你们在学习他人的代码,是否见过这样的代码 def main(): def user_info(gender): 当你还是个小萌新时,你一定会认为这是个很牛逼的语法。 当你有了一点基础时,你一定会想要了解这个语法,并且尝试去使用它。 那么今天,我们便来了解这个牛语法。 有了一点点的python基础,我们来看这段代...
-
自从用了这些快捷键,鼓励师也不需要了,代码开发效率蹭蹭提升!!! ctrl+shift+[折叠代码 (这个比ctrl+k ctrl+l、ctrl+k ctr+j不知道好用多少倍!) ctrl+shift+]展开代码 ctrl+shift+T打开手贱不小心关掉的窗口 【推荐】ctrl+shift+O打开当前文件...
-
在提交代码之前,建议最好先Fetch代码下来(如果有冲突,系统会提示),然后再操作Merge到本地分支,这样做是为了避免有其他人同时修改了当前分支,如果直接用Ctrl+T(pull代码)极有可能覆盖本地分支最新代码,安全起见先Fetch代码(Ctrl+Alt+Shift+1)——所谓:小心驶得万年船!...
-
每次复制代码时,如果代码里有 // 这样的注释就容易让格式乱掉,通过下面的设置就可以避免这种情况。 粘贴代码时取消自动缩进 VIM在粘贴代码时会自动缩进,把代码搞得一团糟糕,甚至可能因为某行的一个注释造成后面的代码全部被注释掉,我知道有同学这个时候会用vi去打开文件再粘贴上去(鄙人以前就是这样),其实需要先设置一下 s...