基于相机和低分辨率激光雷达的三维车辆检测
标题:3D Vehicle Detection Using Camera and Low-Resolution LiDAR Zhang, Rui Huang, Le Cui, Siyu Zhu, and Ping Tan
作者:Lin Bai, Yiming Zhao and Xinming Huang
编译:点云PCL
本文仅做学术分享,如有侵权,请联系删除。欢迎各位加入免费知识星球,获取PDF论文,欢迎转发朋友圈。内容如有错误欢迎评论留言,未经允许请勿转载!
公众号致力于分享点云处理,SLAM,三维视觉,高精地图相关的文章与技术,欢迎各位加入我们,一起每交流一起进步,有兴趣的可联系微信:920177957。本文来自点云PCL博主的分享,未经作者允许请勿转载,欢迎各位同学积极分享和交流。
摘要
目前,LiDAR已广泛应用于自动驾驶车辆的感知与定位系统中。然而,高分辨率激光雷达的成本仍然昂贵得让人望而却步,相反低分辨率激光雷达的成本要便宜得多。因此,用低分辨率激光雷达代替高分辨率激光雷达进行自主驾驶感知是一种经济可行的解决方案。本文提出了一种利用低分辨率激光雷达和单目摄像机进行三维目标检测的新框架。以低分辨率激光雷达点云和单目图像为输入,我们的深度修复网络能够生成密集点云,然后由基于体素的网络进行三维目标检测。实验结果表明,该方法比直接应用16线激光雷达点云进行目标检测具有更好的性能。对于简单和中等难度场景,我们的检测结果与64线高分辨率激光雷达相当。
介绍
表一比较了最流行的Velodyne 64线激光雷达HDL-64E和16线激光雷达VLP-16的规格。可见,低分辨率激光雷达的成本仅为高分辨率激光雷达的1/10左右
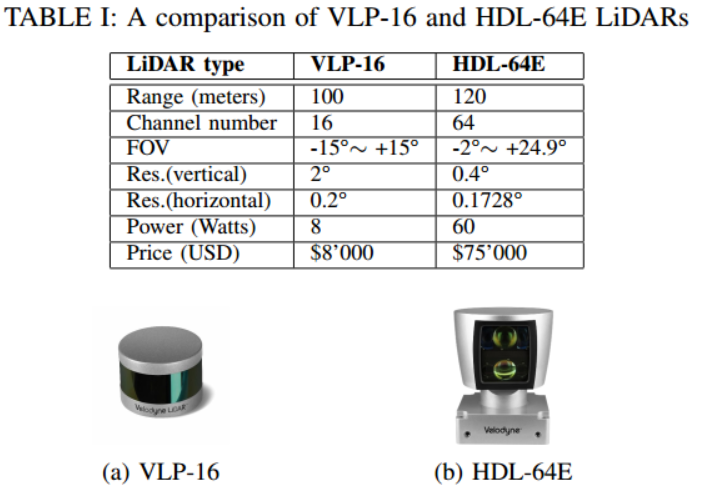
因此,有必要关注低分辨率激光雷达,以建立低成本的自主驾驶系统。然而,从低分辨率激光雷达产生的点云中进行目标检测是一个很大的挑战,因为点云太稀疏,甚至无法显示目标的形状。如图2所示,我们几乎无法从16线激光雷达捕获的深度图中找到物体,而64线激光雷达数据更为清晰可见。

图2:16线激光雷达(底部)和64线激光雷达(中部)的深度图与其RGB图像(顶部)的对比,红色框表示近程车辆,橙色框表示中距离车辆,远程车辆用蓝色框标记。绿色方框表示阻挡的车辆。
低分辨率激光雷达的研究主要集中在低分辨率激光雷达的基础上,在图像分割上引入了激光雷达的球坐标的局部法向量作为输入。基于现有的LoDNN框架,在合理的退化范围内,低分辨率激光雷达的道路分割性能与高分辨率激光雷达相当。但是随着距离的增加,跟踪性能急剧下降。
用于BEV目标检测方法大多是基于高分辨率激光雷达,首先将点云转化为BEV地图,然后分别提取地面和两个分支中的目标。最后通过后处理块对目标进行预测将以前的版本进一步细化为端到端模型,并取得了更好的性能。比如基于体素化BEV图的二维卷积的单级检测器PIXOR。无需任何锚点,实现了实时处理速度。如前所述,由于高度稀疏性,低分辨率激光雷达深度图不能提供足够的物体形状信息,只能提供精确深度信息的部分子样本。同时,RGB图像提供了丰富的上下文信息。因此,我们认为当融合稀疏深度图和RGB图像时,目标检测成为可能。
主要内容
本文研究了低分辨率激光雷达用于BEV目标检测的可能性。在图2中,红色框、橙色框和蓝色框分别表示短程、中程和远程车辆。对于短程车辆,它们的形状在密集的深度图上清晰可见。在稀疏深度图中,形状非常模糊,但仍然可以识别,因为扫描车辆的点的数量仍然足够大。对于中远程车辆(橙色和蓝色方框),即使使用64线激光雷达,也只能获得少量的点。而在16线激光雷达的稀疏深度图中,扫描击中点的数目很少甚至没有。以图2(h)中橙色方框中的中程车辆为例,由于距离差别较大,很容易将其识别为障碍物,但很难将其识别为车辆。这也适用于有遮挡的车辆(图2(c)、(f)和(i)中的绿色框)。蓝框中的远程车辆(图2(e)和(h)中)得到的点太少,无法正确定位和分类。通过以上分析,我们发现与64线激光雷达的深度图不同,16线激光雷达深度图显示的不是可靠的背景信息,而是准确的距离信息。这意味着16线激光雷达深度图对于深度估计比上下文信息提取更有用。因此,为了更好地利用16线的深度图的信息,我们在目标检测器之前放置了一个深度优化网络,以生成一个包含上下文信息的密集深度图(图3)。生成密集深度图后,将其发送到三维目标检测器中,如图4所示。

图3 三维目标检测解决方案:(a)以高分辨率点云为输入(b) 低分辨率点云和图像作为输入。
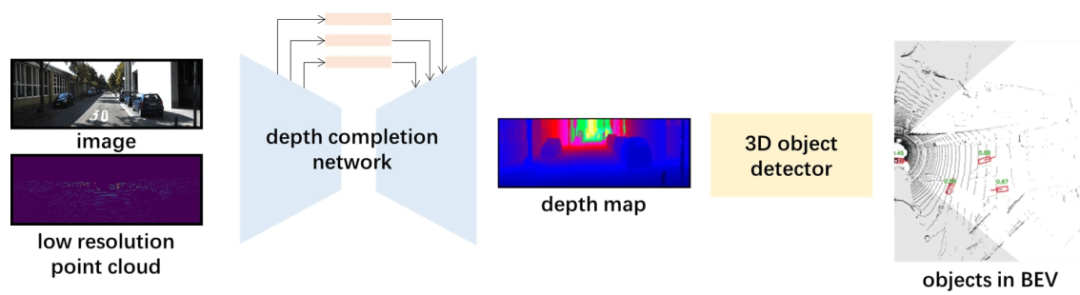
图4:利用低分辨率点云图像进行目标检测的框架
深度优化网络
深度优化网络的目的是利用RGB图像对16线LiDAR点云稀疏深度图进行填充。这里对最先进的深度优化网络进行了一些修改。它需要两个输入,RGB图像和低分辨率稀疏深度图。RGB图像提供了详细的上下文信息,而稀疏深度图为图像上的某些像素提供了精确的深度信息。本文采用的传感器融合策略也称为早期融合。为了使网络更紧凑,首先用ResNet-18替换ResNet-34。为了提高性能,放置了全局注意模块和atrus Spatial pyramidpooling(ASPP)[18]模块来桥接编码器和解码器。如图5所示
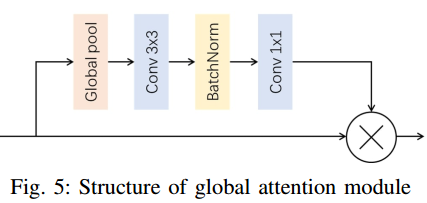
全局注意模块通过全局池层提取特征图的全局上下文信息,然后将全局信息融合回来,指导特征学习。通过增加该模块,将全局信息融合到特征中,无需上采样层。这有助于解码器部分获得更好的性能。此外,ASPP模块(图6)被放置在编码器和解码器之间,每个卷积扩展速率为2、4、8和16。ASPP模块将具有不同感知域的特征映射串联起来,以便解码器更好地理解上下文信息。

目标检测网络
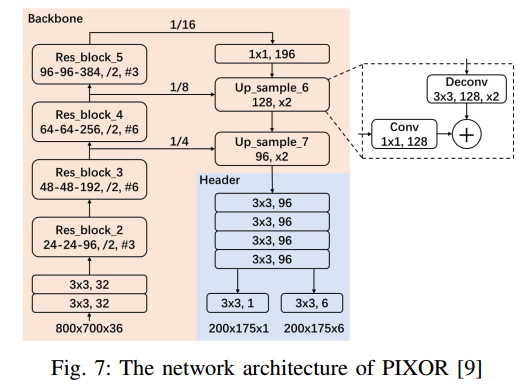
在这个框架中采用的目标检测网络是PIXOR。其主要思想是利用二维卷积和无锚网络的优点,在BEV中实现超快速点云目标检测。PIXOR由两个步骤组成。第一步是改进输入点云的表示方法。它将BEV中的3个自由度降为2个,并提取第3个自由度(z或高度)作为另一个输入特征映射通道。因此,用二维卷积代替三维卷积可以大大降低计算复杂度。第二步是将改造后的输入特征图输入到无锚点的单级目标检测器网络中(图7)
实验
训练集
整个框架的数据集训练和评价均采用KITTI数据集(深度补全和目标检测)。在输入到上述框架之前,对点云进行下采样以模拟VLP-16低分辨率激光雷达。KITTI深度完成数据集包含85898个训练数据和1000个选定的验证数据。它的地面真实感是通过将连续的激光雷达扫描帧聚合成一个半密集的深度图,约30%的标注像素。KITTI目标检测数据集有7481个训练数据和7518个测试数据。评价分为三个阶段:简单、中等和困难,分别代表不同遮挡和截断水平的对象。
深度优化网络的性能评估
如III-A,为了提高深度完成性能,在深度优化网络的编解码器之间加入了多个GAM模块。验证数据集的性能比较如表1所示。加入GAM模块后,性能分别提高了3.6%和7.0%。
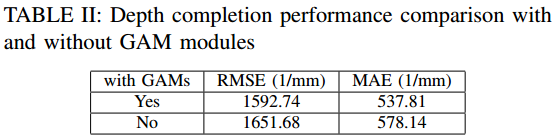
图8(b)和(c)分别展示了有和没有GAM模块的深度优化网络的预测深度图。

图8:有和没有GAM模块的16线激光雷达的深度图与其RGB图像和真值的比较

图9:本文提出的框架的三维目标检测的可视化的结果,其中绿色框是真值,蓝色框是框表示预测结果
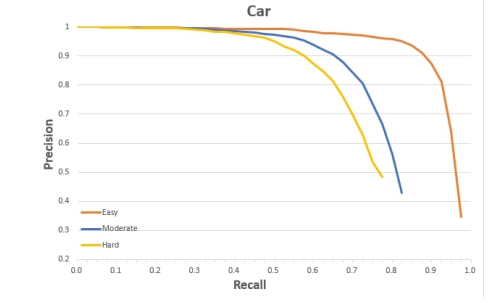
图10:该框架在KITTI-val数据集上的召回率与准确率的曲线
总结
本文提出了一种低分辨率激光雷达点云三维目标检测框架。通过在目标检测器之前级联一个深度优化网络,它首先将稀疏点云转换成一个更密集的深度图,然后对该深度图进行处理以进行三维目标检测。它使目标检测成为可能,从一个稀疏的,低成本的激光雷达通过融合图像捕获的相机。当在KITTI数据集上进行评估时,该网络可以在近距离和中等距离的情况下达到与使用高分辨率点云相当的目标检测精度。
资源
三维点云论文及相关应用分享
【点云论文速读】基于激光雷达的里程计及3D点云地图中的定位方法
3D目标检测:MV3D-Net
三维点云分割综述(上)
3D-MiniNet: 从点云中学习2D表示以实现快速有效的3D LIDAR语义分割(2020)
win下使用QT添加VTK插件实现点云可视化GUI
JSNet:3D点云的联合实例和语义分割
大场景三维点云的语义分割综述
PCL中outofcore模块---基于核外八叉树的大规模点云的显示
基于局部凹凸性进行目标分割
基于三维卷积神经网络的点云标记
点云的超体素(SuperVoxel)
基于超点图的大规模点云分割
更多文章可查看:点云学习历史文章大汇总
SLAM及AR相关分享
【开源方案共享】ORB-SLAM3开源啦!
【论文速读】AVP-SLAM:自动泊车系统中的语义SLAM
【点云论文速读】StructSLAM:结构化线特征SLAM
SLAM和AR综述
常用的3D深度相机
AR设备单目视觉惯导SLAM算法综述与评价
SLAM综述(4)激光与视觉融合SLAM
Kimera实时重建的语义SLAM系统
SLAM综述(3)-视觉与惯导,视觉与深度学习SLAM
易扩展的SLAM框架-OpenVSLAM
高翔:非结构化道路激光SLAM中的挑战
SLAM综述之Lidar SLAM
基于鱼眼相机的SLAM方法介绍
如果你对本文感兴趣,请后台发送“知识星球”获取二维码,务必按照“姓名+学校/公司+研究方向”备注加入免费知识星球,免费下载pdf文档,和更多热爱分享的小伙伴一起交流吧!
以上内容如有错误请留言评论,欢迎指正交流。如有侵权,请联系删除
扫描二维码
关注我们
让我们一起分享一起学习吧!期待有想法,乐于分享的小伙伴加入免费星球注入爱分享的新鲜活力。分享的主题包含但不限于三维视觉,点云,高精地图,自动驾驶,以及机器人等相关的领域。
分享及合作方式:微信“920177957”(需要按要求备注) 联系邮箱:[email protected],欢迎企业来联系公众号展开合作。
点一下“在看”你会更好看耶

更多相关:
-
点云PCL免费知识星球,点云论文速读。文章:FAST-LIO2: Fast Direct LiDAR-inertial Odometry作者: Wei Xu∗1 , Yixi Cai∗1 , Dongjiao He1 , Jiarong Lin1 , Fu Zhang编译:点云PCL代码:https://github.com/hku...
-
点云PCL免费知识星球,点云论文速读。文章:Towards High-Performance Solid-State-LiDAR-Inertial Odometry and Mapping作者:Kailai Li, Meng Li, and Uwe D. Hanebeck编译:点云PCL代码:https://github.com/K...
-
论文阅读模块将分享点云处理,SLAM,三维视觉,高精地图相关的文章。公众号致力于理解三维视觉领域相关内容的干货分享,欢迎各位加入我,我们一起每天一篇文章阅读,开启分享之旅,有兴趣的可联系微信[email protected]。mlcc介绍本文主要实战应用这篇文章的代码,https://github.com/hku-mars/mlc...
-
标题:VCamVox: A Low-cost and Accurate Lidar-assisted Visual SLAM System作者:Yuewen Zhu, Chunran Zheng, Chongjian Yuan, Xu Huang and Xiaoping Hong来源:分享者代码:https://github.co...
-
点云PCL免费知识星球,点云论文速读。文章:TANDEM: Tracking and Dense Mapping in Real-time using Deep Multi-view Stereo作者:Lukas Koestler Nan Yang y Niclas Zeller Daniel Cremers编译:点云PCL代码:h...
-
摘要 在本文中,我们提出了MonoRec,一种半监督的单目密集重建架构,该方案可在动态环境中根据单个移动摄像机预测深度图。MonoRec提出了一种新型的多阶段训练方案,该方案可以不需要LiDAR深度值的半监督损失公式。在KITTI数据集上仔细评估了MonoRec,并表明与多视图和单视图方法相比,它具有最先进的性能。通过在KITTI上训...
-
(1)点云到深度图与可视化的实现 区分点云与深度图本质的区别 1.深度图像也叫距离影像,是指将从图像采集器到场景中各点的距离(深度)值作为像素值的图像。获取方法有:激光雷达深度成像法、计算机立体视觉成像、坐标测量机法、莫尔条纹法、结构光法。 2.点云:当一束激光照射到物体表面时,所反射的激光会携带方位、距离等信息。若将激光束...
-
深度Q学习原理及相关实例8. 深度Q学习8.1 经验回放8.2 目标网络8.3 相关算法8.4 训练算法8.5 深度Q学习实例8.5.1 主程序程序注释8.5.2 DQN模型构建程序程序注释8.5.3 程序测试8.6 双重深度Q网络8.7 对偶深度Q网络...
-
缘起 现在很多小伙伴儿都从Ubuntu转到Deepin下面去了, Deepin这几年出了一些很不错的软件,比如深度截图, 深度影音, 深度音乐等等, Deepin基于Ubuntu开发, 它的软件大量使用QT4/5开发, 这也是我折腾QT的原因. 说明 在Ubuntu 14.04上python 2.7和python 3.4是可以共存的...