python写byte数组到文件_这可能是写过最详细的Python文件操作。网友:收藏备用(中篇)...

很多同学对于编码问题都不是很清楚,计算机常见的编码格式为:
ASCII
ISO-8859-1
GB2312
GBK
UTF-8
UTF-16
对于Python开发中,我们一般都是采用统一的编码格式:UTF-8
第一行加入环境申明:
#coding=utf-8
编码操作方式一般都分为:编码(encode)和解码(decode) 但是对于今天我们所要讲解的主角Python来说:
unicode和str两种类型的相互转换则为解码和编码。如下列子:
# coding = utf-8
# Python编码问题
str = "您好"
print("输出字符类型--->>>", type(str))
print(str)
# 采用 encode编码
str1 = str.encode('gbk')
print("gbk--encode--输出字符类型---->>>>", type(str1))
print(str1)
str2 = str1.decode('gbk')
print("-gbk----decode解码--->>>", str2)
str3 = str.encode('utf-8')
print("utf-8---->>encode----->>>", str3)
str4 = str3.decode('utf-8')
print("utf-8---decode---->>>",str4)从列子中可以看出,不同的编码格式的输出的字符是不一样的字符表达,我们在使用编码和解码的时候都需要采用同一种编码格式进行两者操作,否则就报错。
pritn中文编码问题
如下图:
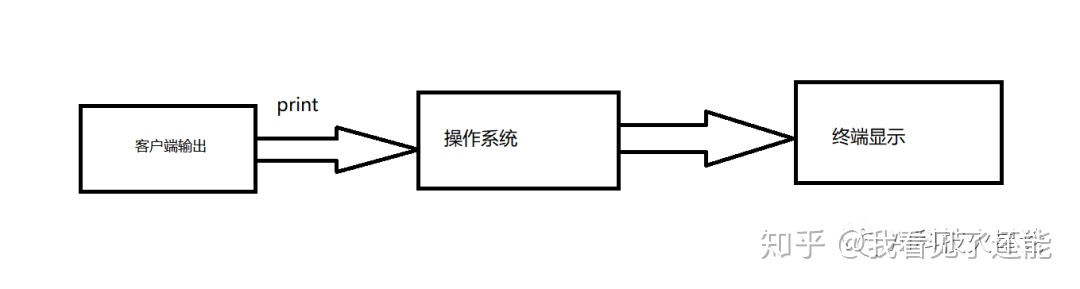
Python打印变量时,操作系统会对变量进行相应的处理,若变量是str类型,则操作系统直接发送到终端显示,若变量是unicode类型,则操作系统会对变量用sys.stdout.encoding编码对变量encode,若变量中含有sys.stdout.encoding未定义字符,则会出现UnicodeEncodeError。编码后字节序列被发送给终端,假若终端设置的编码和str编码不一致,终端就会显示出乱码。
两种错误情况:
1:UnicodeEncodeError
若变量中含有sys.stdout.encoding未定义字符则会出现如上错误。一般避此个错误的方式就是:
print("本地终端环境的默认编码---->>>",sys.getdefaultencoding())首先打印出本地环境的编码格式,然后在字符串编码的时候就现在对应的编码格式进行编码和解码。
a = '你好呀'
b = u'Python'
print("--->>>",a)
print('采用utf-8--->>',b.encode('utf-8'))接下来我们来从实例中看看,编码和解码的用法。
# 读取txt 设置编码格式 一定要加上encoding 也就是文件的打开的编码格式 ,不加encoding则报错。
f = open("D:imgstest.txt",encoding='utf-8')
s = f.read()
f.close()
print("--->>>",type(s))
print("---->>>", s)总结,Python3中编码问题比Python2有了很多改善。
P3中的编码我们只需要记住一点,打开读取文件的时候一定要声明编码格式,开发编程前都提前设置好环境编码,一般都是默认的utf-8格式,解码和编码都使用统一的编码格式进行操作,这样就能保存文件操作的时候不会出现编码。

更多精彩请持续关注作者,点击保存以下图片,获取更多资源和干货。
http://weixin.qq.com/r/Dio1LZrEncfird5O938c (二维码自动识别)
更多相关:
-
函数近似方法7.1 目标预测(VE‾overline{VE}VE)7.2 随机梯度下降和半梯度下降例7.1: 1000态随机行走的状态收敛7.3 线性近似7.4 线性方法的特征构造7.4.1 Coarse Coding(粗编码)例7.2:粗编码的粗度7.4.2 Tile Coding(瓦片编码)7.4.3 实例:Tile Codin...
-
1,Ascii和ebcic. 为了方便交流,美国人发明了ASCII编码,后来被确认为国际标准。后来以发明了EBCDIC编码。 一般地说,开放的操作系统(LINUX 、WINDOWS等)采用ASCII 编码,而大型主机系统(MVS 、OS/390等)采用EBCDIC 编码。在发送数据给对方前,需要事先告知对方自己所使用的编码,或者通过...
-
Unicode字符集中收录110多万个字符集合。UTF-8(8-bit Unicode Transformation Format),是一种针对 Unicode 的可变长度字符编码方式。使用一到四个字节来编码 Unicode 字符 在计算机内存中统一使用Unicode编码,当需要保存到硬盘或者需要传输时,转换为UTF—8编码。 字符...
-
----------------基本概念-------------------------------一.位: 计算机存储信息的最小单位,称之为位(bit),音译比特,二进制的一个“0”或一个“1”叫一位。 二.字节 字节(Byte)是一种计量单位,表示数据量多少,它是计算机信息技术用于计量存储容量的一种计量单位,8个二进制位组成1个...
-
#coding:utf-8'''Created on 2017年10月25日@author: li.liu'''import pymysqldb=pymysql.connect('localhost','root','root','test',charset='utf8')m=db.cursor()'''try:#a=raw_inpu...
-
python数据类型:int、string、float、boolean 可变变量:list 不可变变量:string、元组tuple 1.list list就是列表、array、数组 列表根据下标(0123)取值,下标也叫索引、角标、编号 new_stus =['刘德华','刘嘉玲','孙俪','范冰冰'] 最前面一个元素下标是0,最...
-
from pathlib import Path srcPath = Path(‘../src/‘) [x for x in srcPath.iterdir() if srcPath.is_dir()] 列出指定目录及子目录下的所有文件 from pathlib import Path srcPath = Path(‘../tenso...
-
我在使用OpenResty编写lua代码时,需要使用到lua的正则表达式,其中pattern是这样的, --热水器设置时间 local s = '12:33' local pattern = "(20|21|22|23|[01][0-9]):([0-5][0-9])" local matched = string.match(s, "...
-
在分析ats的访问日志时,我经常会遇到将一些特殊字段对齐显示的需求,网上调研了一下,发现使用column -t就可以轻松搞定,比如 找到ATS的access.log中的200响应时间过长的日志 cat access.log | grep ' 200 ' | awk -F '"' '{print $3}' > taoyx.log co...
-
PPM(Portable Pixmap Format)还有两位兄长,大哥名叫「PBM」,二哥人称「PGM」,他们三兄弟各有所长,下面为你们一一介绍: PBM 是位图(bitmap),仅有黑与白,没有灰PGM 是灰度图(grayscale)PPM 是通过RGB三种颜色显现的图像(pixmaps) 每个图像文件的开头都通过2个字节「ma...
-
采用下面的命令可以查看PEM格式的证书信息...
-
pcap文件格式是常用的数据报存储格式,包括wireshark在内的主流抓包软件都可以生成这种格式的数据包...
-
1. dir 添加源代码查找路径 一般工程的代码会有多路径,gdb会在当前目录下搜索符号对应的代码。利用dir
可以添加代码搜索路径; 例如工程目录: ./ ./dir_1/ ./dir_2/ 可以用如下命令添加代码搜索路径: dir dir_1 dir dir_2 2. 调试多参数的程序... -
资源创建:
截止到:%1$tc 销售量比去年增长了%2$d%% 在这里我对所有奋斗的兄弟姐妹表示感谢 对表现最优秀 的%3$s等伙伴我们予以奖励 奖励为价值%4$-9.4e的新马泰游 希望大家再接再厉额! java类中调用:...