Java IO流学习总结三:缓冲流-BufferedInputStream、BufferedOutputStream
转载请标明出处:http://blog.csdn.net/zhaoyanjun6/article/details/54894451
本文出自【赵彦军的博客】
InputStream
|__FilterInputStream|__BufferedInputStream首先抛出一个问题,有了InputStream为什么还要有BufferedInputStream?
BufferedInputStream和BufferedOutputStream这两个类分别是FilterInputStream和FilterOutputStream的子类,作为装饰器子类,使用它们可以防止每次读取/发送数据时进行实际的写操作,代表着使用缓冲区。
我们有必要知道不带缓冲的操作,每读一个字节就要写入一个字节,由于涉及磁盘的IO操作相比内存的操作要慢很多,所以不带缓冲的流效率很低。带缓冲的流,可以一次读很多字节,但不向磁盘中写入,只是先放到内存里。等凑够了缓冲区大小的时候一次性写入磁盘,这种方式可以减少磁盘操作次数,速度就会提高很多!
同时正因为它们实现了缓冲功能,所以要注意在使用BufferedOutputStream写完数据后,要调用flush()方法或close()方法,强行将缓冲区中的数据写出。否则可能无法写出数据。与之相似还BufferedReader和BufferedWriter两个类。
现在就可以回答在本文的开头提出的问题:
BufferedInputStream和BufferedOutputStream类就是实现了缓冲功能的输入流/输出流。使用带缓冲的输入输出流,效率更高,速度更快。
总结:
BufferedInputStream是缓冲输入流。它继承于FilterInputStream。BufferedInputStream的作用是为另一个输入流添加一些功能,例如,提供“缓冲功能”以及支持mark()标记和reset()重置方法。BufferedInputStream本质上是通过一个内部缓冲区数组实现的。例如,在新建某输入流对应的BufferedInputStream后,当我们通过read()读取输入流的数据时,BufferedInputStream会将该输入流的数据分批的填入到缓冲区中。每当缓冲区中的数据被读完之后,输入流会再次填充数据缓冲区;如此反复,直到我们读完输入流数据位置。
BufferedInputStream API简介
源码关键字段分析
private static int defaultBufferSize = 8192;//内置缓存字节数组的大小 8KBprotected volatile byte buf[]; //内置缓存字节数组protected int count; //当前buf中的字节总数、注意不是底层字节输入流的源中字节总数protected int pos; //当前buf中下一个被读取的字节下标protected int markpos = -1; //最后一次调用mark(int readLimit)方法记录的buf中下一个被读取的字节的位置protected int marklimit; //调用mark后、在后续调用reset()方法失败之前云寻的从in中读取的最大数据量、用于限制被标记后buffer的最大值
构造函数
BufferedInputStream(InputStream in) //使用默认buf大小、底层字节输入流构建bis BufferedInputStream(InputStream in, int size) //使用指定buf大小、底层字节输入流构建bis 一般方法介绍
int available(); //返回底层流对应的源中有效可供读取的字节数 void close(); //关闭此流、释放与此流有关的所有资源 boolean markSupport(); //查看此流是否支持markvoid mark(int readLimit); //标记当前buf中读取下一个字节的下标 int read(); //读取buf中下一个字节 int read(byte[] b, int off, int len); //读取buf中下一个字节 void reset(); //重置最后一次调用mark标记的buf中的位子 long skip(long n); //跳过n个字节、 不仅仅是buf中的有效字节、也包括in的源中的字节 BufferedOutputStream API简介
关键字段
protected byte[] buf; //内置缓存字节数组、用于存放程序要写入out的字节 protected int count; //内置缓存字节数组中现有字节总数 构造函数
BufferedOutputStream(OutputStream out); //使用默认大小、底层字节输出流构造bos。默认缓冲大小是 8192 字节( 8KB )BufferedOutputStream(OutputStream out, int size); //使用指定大小、底层字节输出流构造bos 构造函数源码:
/*** Creates a new buffered output stream to write data to the* specified underlying output stream.* @param out the underlying output stream.*/public BufferedOutputStream(OutputStream out) {this(out, 8192);}/*** Creates a new buffered output stream to write data to the* specified underlying output stream with the specified buffer* size.** @param out the underlying output stream.* @param size the buffer size.* @exception IllegalArgumentException if size <= 0.*/public BufferedOutputStream(OutputStream out, int size) {super(out);if (size <= 0) {throw new IllegalArgumentException("Buffer size <= 0");}buf = new byte[size];}一般方法
//在这里提一句,`BufferedOutputStream`没有自己的`close`方法,当他调用父类`FilterOutputStrem`的方法关闭时,会间接调用自己实现的`flush`方法将buf中残存的字节flush到out中,再`out.flush()`到目的地中,DataOutputStream也是如此。 void flush(); 将写入bos中的数据flush到out指定的目的地中、注意这里不是flush到out中、因为其内部又调用了out.flush() write(byte b); 将一个字节写入到buf中 write(byte[] b, int off, int len); 将b的一部分写入buf中 那么什么时候flush()才有效呢?
答案是:当OutputStream是BufferedOutputStream时。
当写文件需要flush()的效果时,需要
FileOutputStream fos = new FileOutputStream("c:a.txt");
BufferedOutputStream bos = new BufferedOutputStream(fos);
也就是说,需要将FileOutputStream作为BufferedOutputStream构造函数的参数传入,然后对BufferedOutputStream进行写入操作,才能利用缓冲及flush()。
查看BufferedOutputStream的源代码,发现所谓的buffer其实就是一个byte[]。
BufferedOutputStream的每一次write其实是将内容写入byte[],当buffer容量到达上限时,会触发真正的磁盘写入。
而另一种触发磁盘写入的办法就是调用flush()了。
1.BufferedOutputStream在close()时会自动flush
2.BufferedOutputStream在不调用close()的情况下,缓冲区不满,又需要把缓冲区的内容写入到文件或通过网络发送到别的机器时,才需要调用flush.
实战演练1:复制文件.
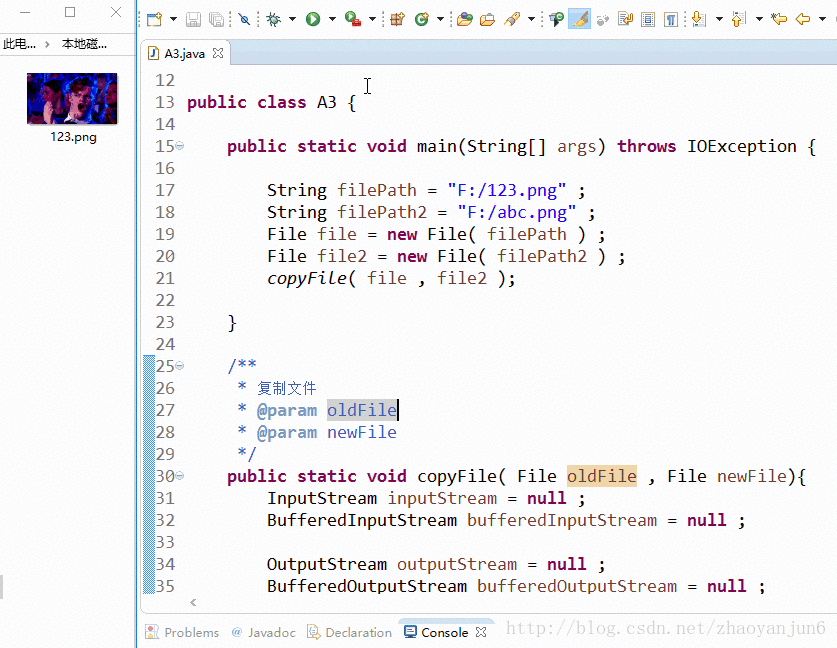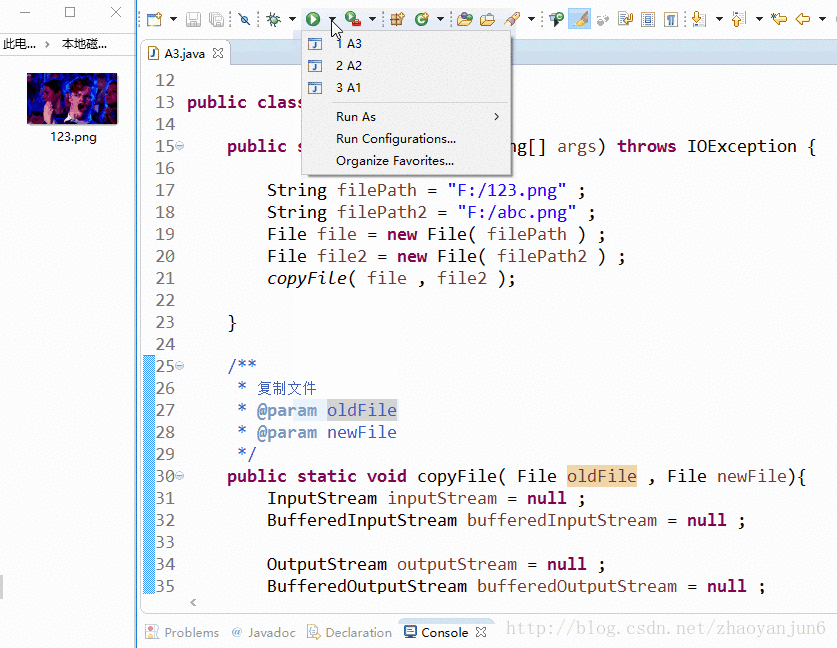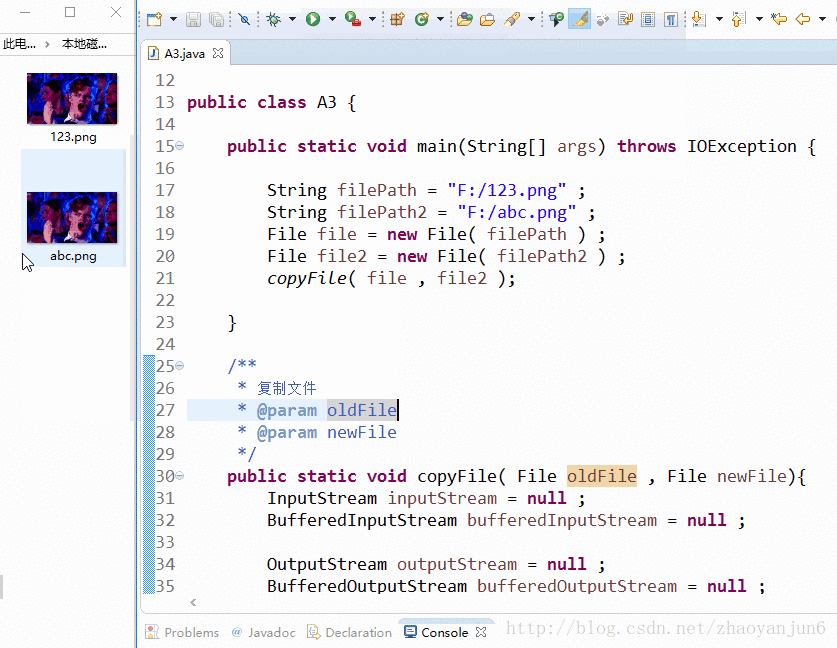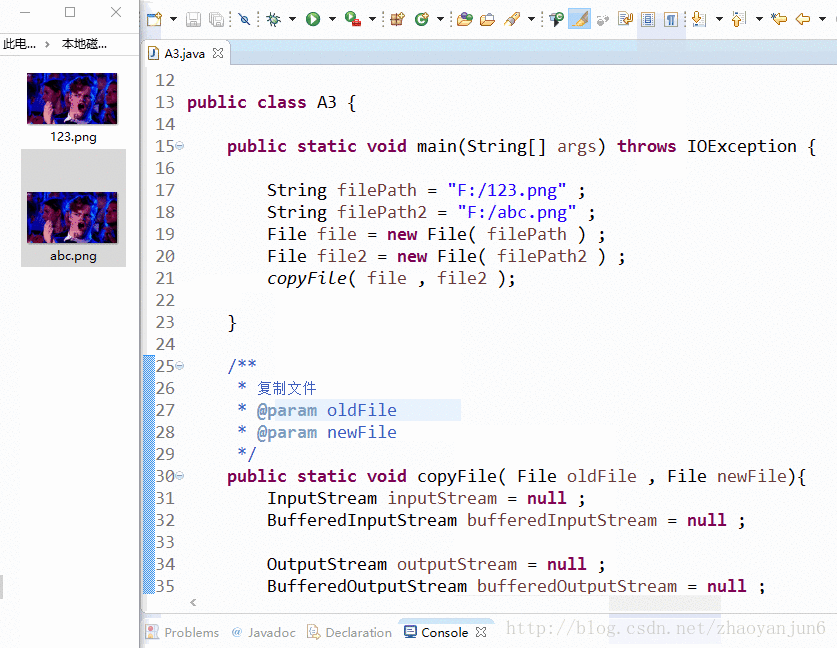
操作:使用缓存流将F盘根目录里面名字为:123.png 图片复制成 abc.png
package com.app;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;public class A3 {public static void main(String[] args) throws IOException {String filePath = "F:/123.png" ;String filePath2 = "F:/abc.png" ;File file = new File( filePath ) ;File file2 = new File( filePath2 ) ;copyFile( file , file2 );}/*** 复制文件* @param oldFile* @param newFile*/public static void copyFile( File oldFile , File newFile){InputStream inputStream = null ;BufferedInputStream bufferedInputStream = null ;OutputStream outputStream = null ;BufferedOutputStream bufferedOutputStream = null ;try {inputStream = new FileInputStream( oldFile ) ;bufferedInputStream = new BufferedInputStream( inputStream ) ;outputStream = new FileOutputStream( newFile ) ;bufferedOutputStream = new BufferedOutputStream( outputStream ) ;byte[] b=new byte[1024]; //代表一次最多读取1KB的内容int length = 0 ; //代表实际读取的字节数while( (length = bufferedInputStream.read( b ) )!= -1 ){//length 代表实际读取的字节数bufferedOutputStream.write(b, 0, length );}//缓冲区的内容写入到文件bufferedOutputStream.flush();} catch (FileNotFoundException e) {e.printStackTrace();}catch (IOException e) {e.printStackTrace();}finally {if( bufferedOutputStream != null ){try {bufferedOutputStream.close();} catch (IOException e) {e.printStackTrace();}}if( bufferedInputStream != null){try {bufferedInputStream.close();} catch (IOException e) {e.printStackTrace();}}if( inputStream != null ){try {inputStream.close();} catch (IOException e) {e.printStackTrace();}}if ( outputStream != null ) {try {outputStream.close();} catch (IOException e) {e.printStackTrace();}}}}
}
效果图:
如何正确的关闭流
在上面的代码中,我们关闭流的代码是这样写的。
finally {if( bufferedOutputStream != null ){try {bufferedOutputStream.close();} catch (IOException e) {e.printStackTrace();}}if( bufferedInputStream != null){try {bufferedInputStream.close();} catch (IOException e) {e.printStackTrace();}}if( inputStream != null ){try {inputStream.close();} catch (IOException e) {e.printStackTrace();}}if ( outputStream != null ) {try {outputStream.close();} catch (IOException e) {e.printStackTrace();}}}思考:在处理流关闭完成后,我们还需要关闭节点流吗?
让我们带着问题去看源码:
bufferedOutputStream.close();
/*** Closes this input stream and releases any system resources* associated with the stream.* Once the stream has been closed, further read(), available(), reset(),* or skip() invocations will throw an IOException.* Closing a previously closed stream has no effect.** @exception IOException if an I/O error occurs.*/public void close() throws IOException {byte[] buffer;while ( (buffer = buf) != null) {if (bufUpdater.compareAndSet(this, buffer, null)) {InputStream input = in;in = null;if (input != null)input.close();return;}// Else retry in case a new buf was CASed in fill()}}close()方法的作用
1、关闭输入流,并且释放系统资源
2、BufferedInputStream装饰一个 InputStream 使之具有缓冲功能,is要关闭只需要调用最终被装饰出的对象的 close()方法即可,因为它最终会调用真正数据源对象的 close()方法。因此,可以只调用外层流的close方法关闭其装饰的内层流。
那么如果我们想逐个关闭流,我们该怎么做?
答案是:先关闭外层流,再关闭内层流。一般情况下是:先打开的后关闭,后打开的先关闭;另一种情况:看依赖关系,如果流a依赖流b,应该先关闭流a,再关闭流b。例如处理流a依赖节点流b,应该先关闭处理流a,再关闭节点流b
看懂了怎么正确的关闭流之后,那么我们就可以优化上面的代码了,只关闭外层的处理流。
finally {if( bufferedOutputStream != null ){try {bufferedOutputStream.close();} catch (IOException e) {e.printStackTrace();}}if( bufferedInputStream != null){try {bufferedInputStream.close();} catch (IOException e) {e.printStackTrace();}}}个人微信号:zhaoyanjun125 , 欢迎关注
