第一:在map端产生join
mapJoin的主要意思就是,当链接的两个表是一个比较小的表和一个特别大的表的时候,我们把比较小的table直接放到内存中去,然后再对比较大的表格进行map操作。join就发生在map操作的时候,每当扫描一个大的table中的数据,就要去去查看小表的数据,哪条与之相符,继而进行连接。这里的join并不会涉及reduce操作。map端join的优势就是在于没有shuffle,真好。在实际的应用中,我们这样设置:
- set hive.auto.convert.join=true;

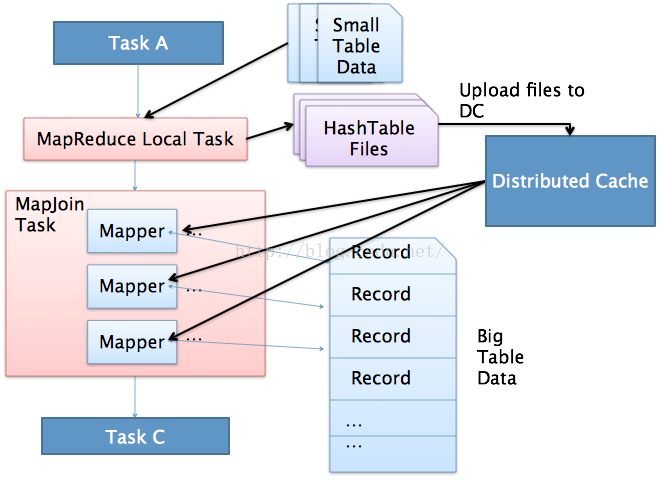
注意看啦,这里的第一句话就是运行本地的map join任务,继而转存文件到XXX.hashtable下面,在给这个文件里面上传一个文件进行map join,之后才运行了MR代码去运行计数任务。说白了,在本质上mapjoin根本就没有运行MR进程,仅仅是在内存就进行了两个表的联合。具体运行如下图:
第二:common join
common join也叫做shuffle join,reduce join操作。这种情况下生再两个table的大小相当,但是又不是很大的情况下使用的。具体流程就是在map端进行数据的切分,一个block对应一个map操作,然后进行shuffle操作,把对应的block shuffle到reduce端去,再逐个进行联合,这里优势会涉及到数据的倾斜,大幅度的影响性能有可能会运行speculation,这块儿在后续的数据倾斜会讲到。因为平常我们用到的数据量小,所以这里就不具体演示了。
第三:SMBJoin
smb是sort merge bucket操作,首先进行排序,继而合并,然后放到所对应的bucket中去,bucket是hive中和分区表类似的技术,就是按照key进行hash,相同的hash值都放到相同的buck中去。在进行两个表联合的时候。我们首先进行分桶,在join会大幅度的对性能进行优化。也就是说,在进行联合的时候,是table1中的一小部分和table1中的一小部分进行联合,table联合都是等值连接,相同的key都放到了同一个bucket中去了,那么在联合的时候就会大幅度的减小无关项的扫描。

具体的看看一个例子:
首先设置如下:
- set hive.auto.convert.sortmerge.join=true;
- set hive.optimize.bucketmapjoin = true;
- set hive.optimize.bucketmapjoin.sortedmerge = true;
- set hive.auto.convert.sortmerge.join.noconditionaltask=true;
- create table emp_info_bucket(ename string,deptno int)
- partitioned by (empno string)
- clustered by(deptno) into 4 buckets;
- insert overwrite table emp_info_bucket
- partition (empno=7369)
- select ename ,deptno from emp
- create table dept_info_bucket(deptno string,dname string,loc string)
- clustered by (deptno) into 4 buckets;
- insert overwrite table dept_info_bucket
- select * from dept;
- select * from emp_info_bucket emp join dept_info_bucket dept
- on(emp.deptno==dept.deptno);//正常的情况下,应该是启动smbjoin的但是这里的数据量太小啦,还是启动了mapjoin