一、视图(Views)与 同义词
1、视图:实际上是对查询结果集的封装,视图本身不存储任何数据,所有的数据都存放在原来的表中;
在逻辑上可以把视图看作是一张表
2、作用:
-
- 封装查询语句,简化复杂的查询需求
- 屏蔽表中的细节
3、语法:
create [or replace] view 视图的名称 as 查询语句 [with read only]
4、视图和同义词:
-
- 屏蔽了查询过程步骤
- 屏蔽了真实的表名 增加了代码被破解的难度
5、示例:
select * from emp;

-- 封装成一个视图: 获取10号部门的员工信息 create or replace view view_test1 as select * from emp where deptno=10; select * from view_test1;

-- 简化查询语句 CREATE VIEW view_test2 AS SELECTSUM(cc) total,SUM(CASE yy WHEN '1980' THEN cc END) "1980",SUM(CASE yy WHEN '1981' THEN cc END) "1981",SUM(CASE yy WHEN '1982' THEN cc END) "1982",SUM(CASE yy WHEN '1987' THEN cc END) "1987" FROM(SELECTTO_CHAR(HIREDATE, 'YYYY') YY,COUNT(*) CCFROMEMPGROUP BYTO_CHAR(HIREDATE, 'YYYY')) TT ; select * from view_test2;

-- 屏蔽表中的细节 create or replace view view_test3 as select ename,job,mgr,hiredate from emp; -- 通过视图修改数据 update view_test3 set ename='SMITH' where ename='SMI%TH';
-- 创建只读视图 create view view_test4 as select ename,job,mgr,hiredate from emp with read only; -- 报错 ORA-01733: virtual column not allowed here update view_test4 set ename='SMITH2' where ename='SMITH';
-- 同义词: 相当于是取了一个别名 create synonym yuangong for view_test3; select * from yuangong;
二、序列
序列: 1,2,3,4,5,6,7....
作用: 模拟类似mysql中auto_increment自动增长的编号
1、语法:
create sequence 序列名称 start with 从几开始 increment by 每次递增多少 minvalue | nominvalue maxvalue | nomaxvalue cycle | nocycle cache 缓存几个数 31,2,34,5,6 -- currval:序列当前取到哪个值,必须是调用了一次nextval之后才能正常使用 -- nextval:序列中的下一个值 -- 注意:序列中的值,一旦被取过,无论回滚/发生异常,序列都是永不回头向下递增的
2、使用示例
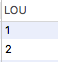
-- 1,2,3,4,5,6,1,2,3,4,5,6 create sequence seq_test01 start with 1 minvalue 1 maxvalue 6 cycle cache 3;-- 需先执行nextval语句后才有效 select seq_test01.currval from dual; select seq_test01.nextval from dual;-- 开发过程,通常写法如下: create sequence seq_test02; -- 建表 create table louceng(lou number primary key ); -- 执行两次 insert into louceng values(seq_test02.nextval); -- 1 2 select seq_test02.currval from dual;select * from louceng;
三、索引
3.1 索引概述
索引:索引是一种已经排好序的帮助数据库快速查找数据的数据结构,主要是用来帮助数据库快速的找到数据 相当于一本书的目录。
语法:
create index 索引名称 on 表名(列名1,列名2....);
主键约束: 自带唯一索引
唯一约束: 自带唯一索引
3.2 索引作用示例
1 -- 创建测试数据500万 2 -- 创建一张表 3 create table wbw( 4 c1 number primary key, 5 c2 varchar2(20), 6 c3 varchar2(20) 7 ); 8 -- 插入500万条记录 9 create sequence seq_wbw; 10 11 -- PLSQL中的循环(283s) 12 declare 13 14 begin 15 for i in 1..5000000 loop 16 insert into wbw values(seq_wbw.nextval,'c2:'||i,'c3:'||i); 17 end loop; 18 commit; 19 end; 20 21 -- 在没有创建索引的情况下(2.37s) 22 select * from wbw where c2='c2:4000000'; 23 24 -- 0.00s 25 select * from wbw where c1=4000000; 26 27 -- 创建索引(35.77s) 28 create index wbw_c2 on wbw(c2); 29 -- 索引列下 0.15s 30 select * from wbw where c2='c2:4000000'; 31 -- 非索引列下 2.38s 32 select * from wbw where c3='c3:4000000';
3.3 索引扩展
3.3.1 索引优化概述
SQL语句的执行计划(SQL语句分析的时候): 将SQL语句发送给数据库, 数据库分析执行这条语句需要经历哪些步骤,消耗多少资源
SQL优化的步骤:
1.找到需要优化的语句
2.通过执行计划去分析SQL语句
3.确定优化方案
索引的原理: 索引是一种已经排好序的帮助数据库快速查找数据的数据结构 BTree : B树, Balance, 平衡多路查找树
索引的利弊:
好处: 提高查询的效率
缺点: 占资源,反向影响增删改的效率
什么时候创建索引?
1.数据量比较大时候
2.哪些列经常作为查询的条件
3.3.2 使用示例:
1 -- 没有创建多列索引的情况下 0.50s 2 select * from wbw where c2='c2:4000001' and c3='c3:4000001'; 3 4 -- 创建索引(41.43s) 5 create index wbw_c23 on wbw(c2,c3); 6 7 8 -- 创建多列索引的情况下 0.25s 9 select * from wbw where c2='c2:4000001' and c3='c3:4000001'; 10 -- 1.80s 11 select * from wbw where c3='c3:4000001';
3.3.3 执行计划图解
