前言

从明天起 关心粮食和蔬菜
我有一所房子 面朝大海 春暖花开
本文前提条件
1.了解 posix 线程
2.了解 原子操作
3.具备简单C基础,或者 你也敲一遍.
如果上面不太清楚,你可以翻看我以前的博客,或者'百度'搜索.
结论
1.云风前辈的 玩具 cstring 有点坑, 内存管理很随意(也可能时我菜,理解不了他飘逸的写法)
2.对于江湖中成名已久的 高手, 其实 胜在 思路上.
3.前辈3-4h搞完的,重构了1周, 发现 const char* 和 char* 够用了,真的,越简单越针对 , 越好,学习成本越低
对简单开源代码有兴趣可以看看,毕竟开源的不都是好的.这里做的工作就是简单和扩平台,简单可用升级,如果你也对C字符串感兴趣
可以看看,否则没有必要.
正文
到这里扯皮结束了, 最近任务有点多,游戏公司加班太疯狂了,做的越快任务越多.哎. 以前博客可能讲了不少关于cstring 结构设计.
这里就简单扯一点,重构部分. 从整体上讲,细节自己多练习了.
1.跨平台所做的工作
跨平台主要围绕等待函数和原子操作封装,看下面 的
sc_atom.h 文件内容
#ifndef _SC_ATOM #define _SC_ATOM/** 作者 : wz* * 描述 : 简单的原子操作,目前只考虑 VS(CL) 小端机 和 gcc* 推荐用 posix 线程库*/// 如果 是 VS 编译器 #if defined(_MSC_VER)#include//忽略 warning C4047: “==”:“void *”与“LONG”的间接级别不同 #pragma warning(disable:4047) // v 和 a 多 long 这样数据 #define ATOM_FETCH_ADD(v, a) InterlockedExchangeAdd((LONG*)&(v), (LONG)(a))#define ATOM_ADD_FETCH(v, a) InterlockedAdd((LONG*)&(v), (LONG)(a))#define ATOM_SET(v, a) InterlockedExchange((LONG*)&(v), (LONG)(a))#define ATOM_CMP(v, c, a) (c == InterlockedCompareExchange((LONG*)&(v), (LONG)(a), (LONG)c))/*对于 InterlockedCompareExchange(v, c, a) 等价于下面long tmp = v ; v == a ? v = c : ; return tmp;咱么的 ATOM_FETCH_CMP(v, c, a) 等价于下面long tmp = v ; v == c ? v = a : ; return tmp;*/ #define ATOM_FETCH_CMP(v, c, a) InterlockedCompareExchange((LONG*)&(v), (LONG)(a), (LONG)c)#define ATOM_LOCK(v) while(ATOM_SET(v, 1)) Sleep(0)#define ATOM_UNLOCK(v) ATOM_SET(v, 0)//否则 如果是 gcc 编译器 #elif defined(__GNUC__)#include /*type tmp = v ; v += a ; return tmp ;type 可以是 8,16,32,84 的 int/uint*/ #define ATOM_FETCH_ADD(v, a) __sync_fetch_add_add(&(v), (a))/*v += a ; return v;*/ #define ATOM_ADD_FETCH(v, a) __sync_add_and_fetch(&(v), (a))/*type tmp = v ; v = a; return tmp;*/ #define ATOM_SET(v, a) __sync_lock_test_and_set(&(v), (a))/*bool b = v == c; b ? v=a : ; return b;*/ #define ATOM_CMP(v, c, a) __sync_bool_compare_and_swap(&(v), (c), (a))/*type tmp = v ; v == c ? v = a : ; return v;*/ #define ATOM_FETCH_CMP(v, c, a) __sync_val_compare_and_swap(&(v), (c), (a))/*加锁等待,知道 ATOM_SET 返回合适的值_INT_USLEEP 是操作系统等待纳秒数,可以优化,看具体操作系统使用方式int lock;ATOM_LOCK(lock);//to do think ...ATOM_UNLOCK(lock);*/ #define _INT_USLEEP (2) #define ATOM_LOCK(v) while(ATOM_SET(v, 1)) usleep(_INT_USLEEP)/*对ATOM_LOCK 解锁, 当然 直接调用相当于 v = 0;*/ #define ATOM_UNLOCK(v) __sync_lock_release(&(v))#endif /*!_MSC_VER && !__GNUC__ */#endif /*!_SC_ATOM*/
这里就是统一简单包装gcc 和 VS中提供的 gcc操作.
这里需要说明一下, gcc 中 __sync__... 是基于编译器层的 操作. 而 VS中Interlock... 是基于 Windows api的
有很大不同,这里也只是简单揉了一下,能用的相似的部分.例如
//忽略 warning C4047: “==”:“void *”与“LONG”的间接级别不同 #pragma warning(disable:4047) // v 和 a 多 long 这样数据 #define ATOM_FETCH_ADD(v, a) InterlockedExchangeAdd((LONG*)&(v), (LONG)(a))
主要是防止VS 警告和编译器不通过而改的. v类型不知道而 InterlockedExchangeAdd 只接受 LONG参数.
2.本土个人化接口文件定义
主要见sc_string.h 文件
#ifndef _H_SC_STRING #define _H_SC_STRING#include#include #include "sc_atom.h"#define _INT_STRING_PERMANENT (1) //标识 字符串是持久的相当于static #define _INT_STRING_INTERNING (2) //标识 字符串在运行时中,和内存同生死 #define _INT_STRING_ONSTACK (4) //标识 字符串分配在栈上//0 潜在 标识,这个字符串可以被回收,游离态#define _INT_INTERNING (32) //符号表 字符串大小 #define _INT_ONSTACK (128) //栈上内存大小struct cstring_data {char* cstr; //保存字符串的内容uint32_t hash; //字符串hash,如果是栈上的保存大小uint16_t type; //主要看 _INT_STRING_* 宏,默认0表示临时串uint16_t ref; //引用的个数, 在 type == 0时候才有用 };typedef struct _cstring_buffer {struct cstring_data* str; } cstring_buffer[1]; //这个cstring_buffer是一个在栈上分配的的指针类型 typedef struct cstring_data* cstring; //给外部用的字符串类型/** v : 是一个变量名** 构建一个 分配在栈上的字符串.* 对于 cstring_buffer 临时串,都需要用这个 宏声明创建声明,* 之后可以用 CSTRING_CLOSE 关闭和销毁这个变量,防止这个变量变成临时串*/ #define CSTRING_BUFFER(v) char v##_cstring[_INT_ONSTACK] = { '�' }; struct cstring_data v##_cstring_data = { v##_cstring, 0, _INT_STRING_ONSTACK, 0 }; cstring_buffer v; v->str = &v##_cstring_data;/** v : CSTRING_BUFFER 声明的字符串变量* 释放字符串v,最好成对出现,创建和销毁*/ #define CSTRING_CLOSE(v) if(0 == (v)->str->type) cstring_release((v)->str)/** s : cstring_buffer 类型* 方便直接访问 struct cstring_data 变量*/ #define CSTRING(s) ((s)->str)/** v : 声明的常量名,不需要双引号* cstr : 常量字符串,必须是用 ""括起来的*/ #define CSTRING_LITERAL(v, cstr) static cstring v; if (NULL == v) { cstring tmp = cstring_persist(""cstr, ( sizeof(cstr)/sizeof(char) - 1 )); if(!ATOM_CMP(v, NULL, tmp)) { cstring_free_persist(tmp); } }/* low level api, don't use directly */ cstring cstring_persist(const char* cstr, size_t sz); void cstring_free_persist(cstring s);/*public api*/ /** s : 待处理的串* return : 处理后永久串,可以返回或使用 * 主要将栈上的串拷贝到临时堆上或者将临时堆待释放的串变到符号表中*/ extern cstring cstring_grab(cstring s);/** s : 待释放的串* 主要是对临时堆上的串进行引用计数删除*/ extern void cstring_release(cstring s);/** sb : 字符串保存对象* str : 拼接的右边字符串 * return : 返回拼接好的串 cstring*/ extern cstring cstring_cat(cstring_buffer sb, const char* str);/** sb : 字符串'池' , 这个字符串库维护,你只管用* format : 格式化串,按照这个格式化输出内容到 sb 中* ... : 可变参数内容* return : 格式化好的字符串,需要自己释放** 后面 __attribute format 是在gcc上优化编译行为,按照printf编译约束来*/ extern cstring cstring_printf(cstring_buffer sb, const char* format, ...) #ifdef __GNUC____attribute__((format(printf, 2, 3))) #endif ;/** a : 字符串a* b : 字符串b* return : 当a和b不同是直接返回false,相同需要多次比较,相比strcmp 好一些*/ extern int cstring_equal(cstring a, cstring b);/** s : 字符串s* 为字符串s 生成hash值并返回,除了栈上的会设置上这个hash值*/ extern uint32_t cstring_hash(cstring s);// 临时补得一个 日志宏,方便查错,推荐这些接口 用日志系统代替,是一个整体 #ifndef cerr #include /** 错误处理宏,msg必须是""括起来的字符串常量* __FILE__ : 文件全路径* __func__ : 函数名* __LINE__ : 行数行* __VA_ARGS__ : 可变参数宏,* ##表示直接连接, 例如 a##b <=> ab*/ #define cerr(msg,...) fprintf(stderr, "[%s:%s:%d]" msg " ",__FILE__,__func__,__LINE__,##__VA_ARGS__) #endif#endif /*!_H_SC_STRING*/
以上是重构的所有接口,其实就是换皮了.外加了一些解释. 后面添加了简单测试宏. 以后在项目中换成内部日志系统.
3.接口文件实现
接口实现文件内容多一点
sc_string.c
#include "sc_string.h"#include#include #include <string.h>#define _INT_FORMAT_TEMP (1024) // 这样做也是治标不治本,保存2k个字符串常量 #define _INT_INTERNING_POOL (2048) // hash size must be 2 pow #define _INT_HASH_START 8/** 字符串结点,可以认为是一个桶,链表* str : 字符串具体变量* buf : 临时栈上变量,主要为 str.str 用的* next : 下一个字符串结点*/ struct string_node {struct cstring_data str;char buf[_INT_INTERNING];struct string_node* next; };/** 认为是字符串池,主要保存运行时段字符串变量,存在上限,因系统而定*/ struct string_pool {struct string_node node[_INT_INTERNING_POOL]; };/** 字符串对象的管理器* * lock : 加锁用的* size : hash串的大小* hash : 串变量* total : 当前string_interning 中保存的字符串运行时常量* pool : 符号表存储的地方* index : 标识pool 堆上保存到哪了*/ struct string_interning {int lock;int size;struct string_node** hash;int total;struct string_pool* pool;int index; };// 总的字符串管理对象实例化 static struct string_interning __sman = {0, _INT_HASH_START, NULL, 0, NULL, 0 };// 这个 sc_string.c 用到的加锁解锁简化的 宏 #define LOCK() ATOM_LOCK(__sman.lock)#define UNLOCK() ATOM_UNLOCK(__sman.lock)/** 将字符串结点插入到hash表中** struct string_node** hash : 指向字符串链表结点指针的指针,认为是hash表* int sz : 新的hash表大小,上面指针的大小,这个值必须是 2的幂* struct string_node* n : 待插入hash表的结点*/ static void __insert_node(struct string_node** hash, int sz, struct string_node* n) {uint32_t h = n->str.hash;int idx = h & (sz - 1);n->next = hash[idx];hash[idx] = n; }/** 为 运行时的 字符串 struct string_interning 变量扩容,重新hash分配* * struct string_interning* si : 字符串池总对象*/ static void __expand(struct string_interning* si) {int nsize = si->size << 1; //简单扩容struct string_node** nhash = calloc(nsize, sizeof(struct string_node*));if (NULL == nhash) {cerr("nhash calloc run error, memory insufficient.");exit(EXIT_FAILURE);}if (si->size > _INT_HASH_START) {for (int i = 0; i < si->size; ++i) {struct string_node* node = si->hash[i];while (node) { // 头结点会变成尾结点struct string_node* tmp = node->next;__insert_node(nhash, nsize, node);node = tmp;}}}//释放原先内存,重新回来free(si->hash);si->hash = nhash;si->size = nsize; }/** 创建一个运行时字符串对象并返回,理解为字符串常量.不需要释放* * si : 总的字符串对象* cstr : 普通字符串量* sz : cstr需要的处理的长度,这个参数 必须 < _INT_INTERNING* hs : 这个字符串cstr的 hs值** : 返回值 是一个常量字符串的地址,有直接返回,没有构建*/ static cstring __interning(struct string_interning* si, const char* cstr, size_t sz, uint32_t hs) {//si中hash表为NULL,保存无意义if (NULL == si->hash)return NULL;int sse = si->size;int idx = hs & (sse - 1);struct string_node* n = si->hash[idx];while (n) {if (n->str.hash == hs) if (strcmp(n->str.cstr, cstr) == 0) return &n->str;n = n->next;}// 这里采用的 jshash 函数不碰撞率 80% (4/5) , 这是经验代码if (si->total * 5 >= sse * 4)return NULL;if (NULL == si->pool) { //这个不是一个好设计.为了适应struct string_pool*,这种写死的内存块放在可以放在全局区,但是无法扩展// need not free poolsi->pool = malloc(sizeof(struct string_pool));if (NULL == si->pool) {cerr("si->pool malloc run error, memory insufficient.");exit(EXIT_FAILURE);}si->index = 0;}n = &si->pool->node[si->index++];memcpy(n->buf, cstr, sz);n->buf[sz] = '�'; //cstr 最后是'�' cstring cs = &n->str;cs->cstr = n->buf;cs->hash = hs;cs->type = _INT_STRING_INTERNING;cs->ref = 0;n->next = si->hash[idx];si->hash[idx] = n;return cs; }/** 生成一个字符串常量,主要放在 __sman.pool 中 ** cstr : 待处理的C字符串* sz : 字符串长度* hs : 字符串jshash的值* : 返回 生成的符号字符串的地址*/ static cstring __cstring_interning(const char* cstr, size_t sz, uint32_t hs) {cstring srt;LOCK();srt = __interning(&__sman, cstr, sz, hs);if (NULL == srt) {__expand(&__sman); //内存扩容srt = __interning(&__sman, cstr, sz, hs);}++__sman.total; //记录当前字符串常量个数 UNLOCK();return srt; }/** jshash实现,当返回0设置为1,这里0用作特殊作用,表名初始化状态* * buf : c字符串* len : 字符集长度* : 返回生成的字符串hash值*/ static uint32_t __get_hash(const char* buf, size_t len) {const uint8_t* ptr = (const uint8_t*)buf;size_t h = len; // hash初始化值size_t step = (len >> 5) + 1;for (size_t i = len; i >= step; i -= step)h ^= ((h<<5) + (h>>2) + ptr[i-1]); //将算法导论中东西直接用return h == 0 ? 1 : h; }/** 拷贝C字符串,并返回地址** cstr : c字符串* sz : cstr中处理的长度* : 返回当前字符串地址*/ static cstring __cstring_clone(const char* cstr, size_t sz) {if (sz < _INT_INTERNING)return __cstring_interning(cstr, sz, __get_hash(cstr, sz));//长的串,这里放在堆上struct cstring_data* p = malloc(sizeof(struct cstring_data) + sizeof(char) * (sz + 1));if(NULL == p){cerr("p malloc run error, memory insufficient.");exit(EXIT_FAILURE);}//ptr 指向后面为容纳 cstr申请的内存,并初始化一些量void* ptr = p + 1;p->cstr = ptr;p->type = 0;p->ref = 1;memcpy(ptr, cstr, sz);((char*)ptr)[sz] = '�';p->hash = 0;return p; }/* low level api, don't use directly */ cstring cstring_persist(const char* cstr, size_t sz) {cstring s = __cstring_clone(cstr, sz);if (0 == s->type) { //没有放在运行时的常量中s->type = _INT_STRING_PERMANENT; // 标识持久的字符串中s->ref = 0;}return s; }void cstring_free_persist(cstring s) //用完释放,这些api CSTRING_LITERAL宏中自动调用 {if (s->type == _INT_STRING_PERMANENT)free(s); }cstring cstring_grab(cstring s) {if (s->type & (_INT_STRING_PERMANENT | _INT_STRING_INTERNING))return s;if (s->type == _INT_STRING_ONSTACK)return __cstring_clone(s->cstr, s->hash);// 后面就是临时串 type == 0if (0 == s->ref) //没有引用让其变为持久串,不说内存泄露了,就说已经释放内存能不能用了都是问题s->type = _INT_STRING_PERMANENT;elseATOM_ADD_FETCH(s->ref, 1);return s; }void cstring_release(cstring s) {if (0 != s->type)return;if (0 == s->ref)return;ATOM_ADD_FETCH(s->ref, -1); //为了兼容 window特别处理if (s->ref == 0)free(s); }uint32_t cstring_hash(cstring s) {if (_INT_STRING_ONSTACK == s->type)return __get_hash(s->cstr, s->hash);if (0 == s->hash)s->hash = __get_hash(s->cstr, strlen(s->cstr));return s->hash; }int cstring_equal(cstring a, cstring b) {if (a == b)return 1;//都是运行时的字符串常量,肯定不同if (a->type == _INT_STRING_INTERNING && b->type == _INT_STRING_INTERNING)return 0;if (a->type == _INT_STRING_ONSTACK && b->type == _INT_STRING_ONSTACK) {if (a->hash != b->hash)return 0;return memcmp(a->cstr, b->cstr, a->hash) == 0;}uint32_t ha = cstring_hash(a);uint32_t hb = cstring_hash(b);if (ha != hb) //hash 能够确认不同,但相同不一定同return 0;return strcmp(a->cstr, b->cstr) == 0; }/** 拼接c串a和b,可以话放在符号表中,大的话放在临时区中** a : c串a* b : c串b* : 返回拼接后的cstring 变量*/ static cstring __cstring_cat(const char* a, const char* b) {size_t sa = strlen(a);size_t sb = strlen(b);size_t sm = sa + sb;if (sm < _INT_INTERNING) {char tmp[_INT_INTERNING];memcpy(tmp, a, sa);memcpy(tmp + sa, b, sb);tmp[sm] = '�';return __cstring_interning(tmp, sm, __get_hash(tmp, sm));}//这里同样走 堆上内存分配struct cstring_data* p = malloc(sizeof(struct cstring_data) + sizeof(char) * (sm + 1));if (NULL == p) {cerr("p malloc run error, memory insufficient.");exit(EXIT_FAILURE);}//ptr 指向后面为容纳 cstr申请的内存,并初始化一些量char* ptr = (char*)(p + 1);p->cstr = ptr;p->type = 0;p->ref = 1;memcpy(ptr, a, sa);memcpy(ptr+sa, b, sb);ptr[sm] = '�';p->hash = 0;return p; }cstring cstring_cat(cstring_buffer sb, const char* str) {cstring s = sb->str;if (s->type == _INT_STRING_ONSTACK) {int i = (int)s->hash;while (i < _INT_ONSTACK - 1) {s->cstr[i] = *str;if (*str == '�') //可以就直接返回,全放在栈上return s;++s->hash;++str;++i;}s->cstr[i] = '�';}// 栈上放不下,那就 试试 放在运行时中cstring tmp = s; sb->str = __cstring_cat(tmp->cstr, str); // 存在代码冗余, _INT_ONSTACK > _INT_INTERNING cstring_release(tmp);return sb->str; }/** 根据模式化字符串,和可变参数拼接字符串,返回最终拼接的cstring 地址** format : 模板字符串* ap : 可变参数集* : 返回拼接后的字符串cstring变量*/ static cstring __cstring_format(const char* format, va_list ap) {static char* __cache = NULL; //持久化数据,编译器维护char* rt;char* tmp = __cache;// read __cache buffer atomicif (tmp) {//tmp 获取 __cache值, 如果 __cache == tmp ,会让 __cache = NULLtmp = ATOM_FETCH_CMP(__cache, tmp, NULL);}if (NULL == tmp) {tmp = malloc(sizeof(char) * _INT_FORMAT_TEMP);if (NULL == tmp) {cerr("tmp malloc run error, memory insufficient.");exit(EXIT_FAILURE);}}int n = vsnprintf(tmp, _INT_FORMAT_TEMP, format, ap);if (n >= _INT_FORMAT_TEMP) {int sz = _INT_FORMAT_TEMP << 1;for (;;) {rt = malloc(sizeof(char)*sz);if (NULL == rt) {cerr("rt malloc run error, memory insufficient.");exit(EXIT_FAILURE);}n = vsnprintf(rt, sz, format, ap);if (n < sz)break;//重新开始,期待未来free(rt);sz <<= 1;}}else {rt = tmp;}cstring r = malloc(sizeof(struct cstring_data) + (n+1)*sizeof(char));if (NULL == r) {cerr("r malloc run error, memory insufficient.");exit(EXIT_FAILURE);}r->cstr = (char*)(r + 1);r->type = 0;r->ref = 1;r->hash = 0;memcpy(r->cstr, rt, n+1);// tmp != rt 时候, rt 构建临时区为 临时的if (tmp != rt) free(rt);//save tmp atomicif (!ATOM_CMP(__cache, NULL, tmp))free(tmp);return r; }cstring cstring_printf(cstring_buffer sb, const char* format, ...) {cstring s = sb->str;va_list ap;va_start(ap, format);if (s->type == _INT_STRING_ONSTACK) {int n = vsnprintf(s->cstr, _INT_ONSTACK, format, ap);if (n >= _INT_ONSTACK) {s = __cstring_format(format, ap);sb->str = s;}elses->hash = n;}else {cstring_release(sb->str);s = __cstring_format(format, ap);sb->str = s;}va_end(ap);return s; }
到这里基本结构就完成了. 简单说一下,当我写到下面这块
void cstring_free_persist(cstring s) //用完释放,这些api CSTRING_LITERAL宏中自动调用 {if (s->type == _INT_STRING_PERMANENT)free(s); }cstring cstring_grab(cstring s) {if (s->type & (_INT_STRING_PERMANENT | _INT_STRING_INTERNING))return s;if (s->type == _INT_STRING_ONSTACK)return __cstring_clone(s->cstr, s->hash);// 后面就是临时串 type == 0if (0 == s->ref) //没有引用让其变为持久串,不说内存泄露了,就说已经释放内存能不能用了都是问题s->type = _INT_STRING_PERMANENT;elseATOM_ADD_FETCH(s->ref, 1);return s; }void cstring_release(cstring s) {if (0 != s->type)return;if (0 == s->ref)return;ATOM_ADD_FETCH(s->ref, -1); //为了兼容 window特别处理if (s->ref == 0)free(s); }
补充说明一下,这里 ATOM_ADD_FETCH 返回的是 %hu 的零, 但是 if ((hu)0 == -1)却不等,这是 数据格式默认变成LONG比较的结果.
所以先进行原子操作,再去处理数据. 属于一个隐含的知识点.
扩展一下, 当我们用VS2015 或者说Microsoft 系列IDE写C程序,都是伪C代码,走的是C++编译器的extern "C" 部分. 比较恶心.
对于VS DEBUG 模式下检测内存 的方式是, 在你申请内存时候额外添加空间,free时候回检测,这也就是他检测内存异常而定手段.
具体见
// Tests the array of size bytes starting at first. Returns true if all of the // bytes in the array have the given value; returns false otherwise. static bool __cdecl check_bytes(unsigned char const* const first,unsigned char const value,size_t const size) throw() {unsigned char const* const last{first + size};for (unsigned char const* it{first}; it != last; ++it){if (*it != value)return false;}return true; }
这里再扩展一下,自己的多个IDE编程感受, 用gcc的时候你需要小心翼翼,明白很多细节,否则 直接跪了. 而用VS开发,很大方去你妈,不懂没关系
就是乱写,编译调试都不用太关心,省了1半开发调试时间.只高不低,生产力提升了.技术下降了.真希望Linux 上有个可视化的VS.
到这里扩展结束,继续说一下,它坑的地方
特别是对于 cstring_grab 中 0 == s->ref 的时候, 这时候 s 是一个被释放的临时串. 这样改个类型就直接返回了,相当于
使用已经释放的内存,多恐怖.
就是到这里, 感觉这个玩具已经扶不起来,例如
cstring_cat => cstring_release =>cstring_grab 这种程序崩了.如下
// 测试内存混乱puts(" --新的测试开始-- ");CSTRING_BUFFER(cu);cstring ks = cstring_cat(cu, "你好111111111111111111111111111111111111111111111111111111111111111111111111111111""好的11111111111111111111111111111111111111111111111111111111111111111111111111111111111""坑啊22222222222222222222222222222222222222222222222222222222222222222222222222222222222""你能力比我强,强改只会走火入魔,坑""1111111111111111111111111111111111112222222222222222222222222222222222222222222222222222222222");printf("type:%u, ref:%u, cstr:%s ",ks->type, ks->ref, ks->cstr);CSTRING_CLOSE(cu);//这里继续使用这个串cstring bks = cstring_grab(ks); // 它也没有起死回生的能力,代码崩掉printf("type:%u, ref:%u, cstr:%s ", bks->type, bks->ref, bks->cstr);
代码一执行,程序就崩了.
不想改了, 强改比自己能力强的 设计问题 容易引火焚身.
大家注意一下,有好想法, 可以试试,改好了分享. 我的感觉内存 管理方式隐含的太多了. 有点乱.绝逼内存泄露,毕竟让别人用.
4.运行实例
首先看原始的测试demo
test.c
#include "sc_string.h"#includestatic cstring __foo(cstring t) {CSTRING_LITERAL(hello, "hello");CSTRING_BUFFER(ret);if (cstring_equal(hello, t))cstring_cat(ret, "equal");else cstring_cat(ret, "not equal");return cstring_grab(CSTRING(ret)); }static void __test() {CSTRING_BUFFER(a);cstring_printf(a, "%s", "hello");cstring b = __foo(CSTRING(a));printf("%s ", b->cstr);cstring_printf(a, "very long string %01024d", 0);printf("%s ", CSTRING(a)->cstr);CSTRING_CLOSE(a);cstring_release(b); }int main(void) {__test();#ifdef _MSC_VER system("pause"); #endif // !_MSC_VERreturn 0; }
window 运行结果

到这里window 上基本都跑起来, 现在我们在gcc上测试一下. 首先需要将这些文件上传到Linux服务器上,上传之前统一用utf-8编码保存.
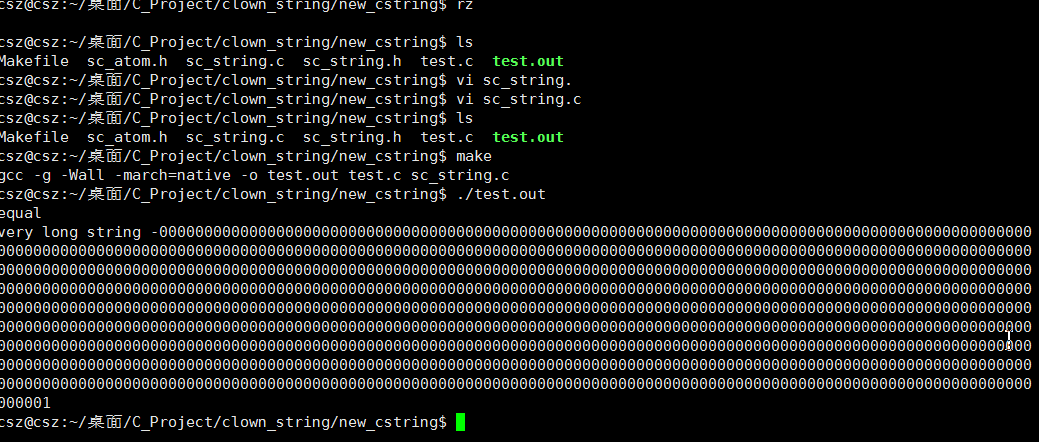
上面是Linux 跑的结果, 其中Makefile 文件内容如下
test.out : test.c sc_string.cgcc -g -Wall -march=native -o $@ $^
到这里 这个高级玩具要告一段落. 还有好多坑,这里就没说了. 例如 cstring_cat cstring_printf 这样分配太慢了, 搞一次不行又重头搞一次, 前面都是无用功.
但作为玩具已经够炫了.期待云风前辈重构成 实战级别的 c字符串, 反正我进过这次教训,觉得C中 char*,const char*, const char * const 够用了.
后记
大家有机会可以去cloudwn githup 上 下载 cstring-master 玩玩, 感受一下别人的代码习惯和风格和设计思路.
有机会下次分享 实战中的简单日志库. 欢迎吐槽,因为技术很菜总有不懂地方和错误的地方.