刚好看到国内的旷视今年在CVPR2017的一篇文章:EAST: An Efficient and Accurate Scene Text Detector。而且有开放的代码,学习和测试了下。
题目说的是比较高效,它的高效主要体现在对一些过程的消除,其架构就是下图中对应的E部分,跟上面的比起来的确少了比较多的过程。这与去年经典的CTPN架构类似。不过CTPN只支持水平方向,而EAST在论文中指出是可以支持多方向文本的定位的。
对于长文本效果不好。

优势:
提供了方向信息,可以检测各个方向的文本
缺点:
对较长的文本检测效果不好,感受野不够长
整体网络结构分为3个部分
(1) 特征提取层:
使用的基础网络结构是PVANet,分别从stage1,stage2,stage3,stage4抽出特征,一种FPN(feature pyramid network)的思想。
(2) 特征融合层:
第一步抽出的特征层从后向前做上采样,然后concat
(3) 输出层:
输出一个score map和4个回归的框+1个角度信息,或者输出,一个scoremap和8个坐标信息。
由于程序实现使用的基础网络不是pvanet网络,而是resnet50-v1。
在caffe版本的resnet50实现中,只有第一个卷积后面的pooling和最后一层的gloabl pooling,详细结构见reference,网络通过卷积层的stride=2操作实现类似pooling的效果
而本程序使用的slim中带的resnet50包含了5个pooling。
Resnet50结构,最后一个featuremap本质上将输入图像缩小16倍(4个pooling),最后一个gloabl pooling,类似于vgg中的全连接。gloabl pooling是googlenet和Resnet的专利。
本文网络结构主要取了pool2,pool3,pool4,pool5,的featuremap引出,分别进行uppooling,concat,conv操作,得到最终的featuremap,然后进行卷积,分别输出channel=1的F_score
,channel=4的geo_map,channel=1的angle_map。
标签生成过程:
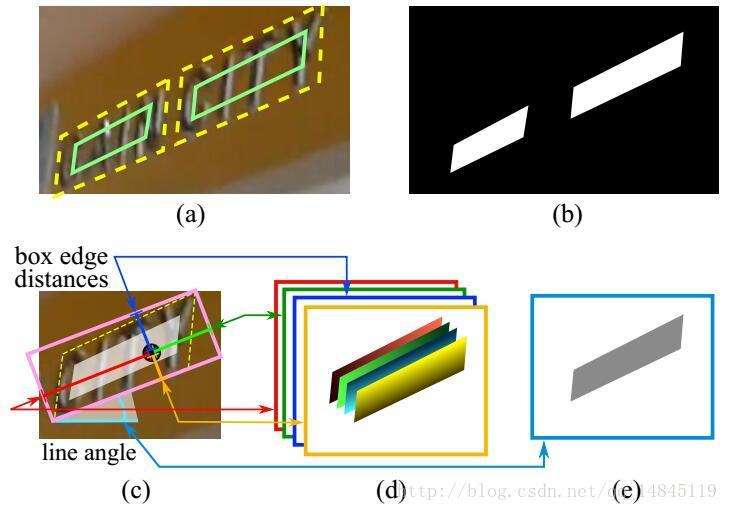
(a) 中黄色的为人工标注的框,绿色为对黄色框进行0.3倍边长的缩放后的框,这样做可以进一步去除人工标注的误差,拿到更准确的label信息。
(b) 为根据(a)中绿色框生成的label信息
(c) 中先生成一个(b)中白色区域的最小外接矩,然后算每一个(b)中白色的点到粉色最小外接矩的上下左右边的距离,即生成(d),然后生成粉色的矩形和水平方向的夹角,即生成角度信息(e),e中所有灰色部分的角度信息一样,都是同样的角度。
论文采用的架构如下:

后来,有大佬改进EAST针对长文本检测效果不好的缺陷,提出advancedEAST,结构如下:
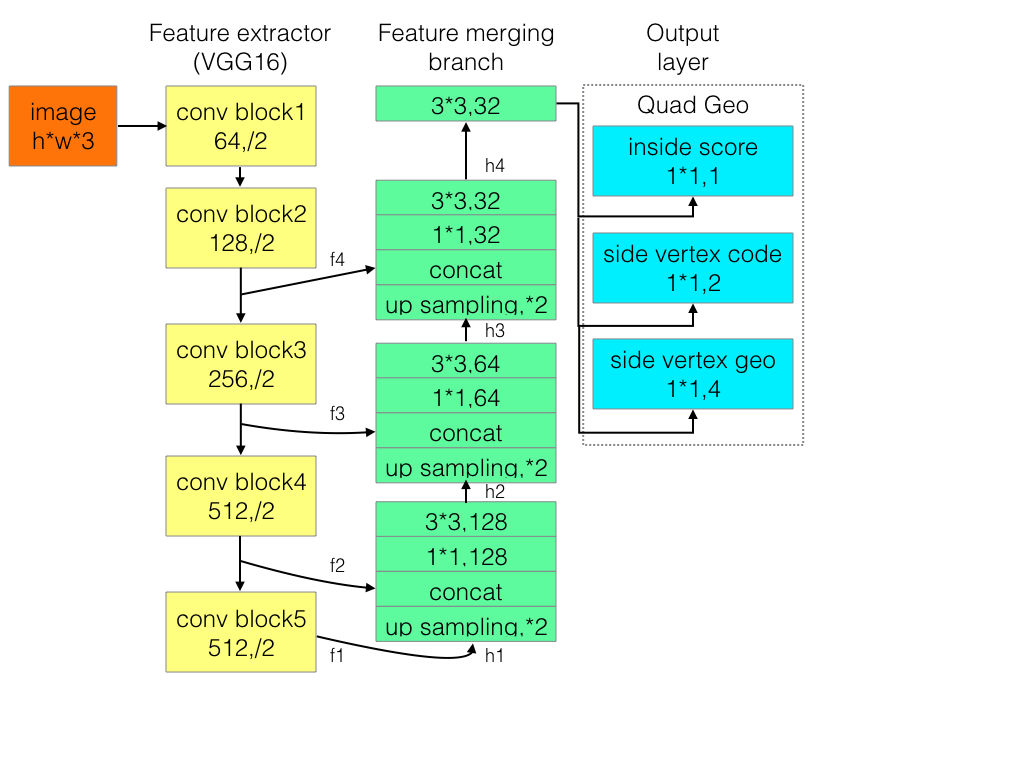
开源源码:https://github.com/huoyijie/AdvancedEAST
仅为学习记录,侵删,感谢作者。