#-*-coding:utf-8-*- ''' 字符串操作 ''' s = " bowen " # 从右边删 s1 = s.rstrip() print(len(s1)) s2 = s1.lstrip() print(len(s2))
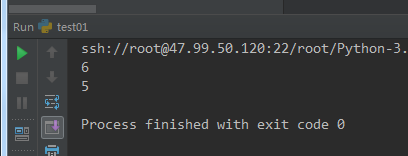
从右边删除元素,从左边删除元素,这个在以后项目中经常用到
·
二、计算个数
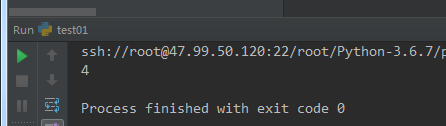
#-*-coding:utf-8-*- ''' 字符串操作 ''' s = " boaaweushvaan " s1 = s.count('a') print(s1)
三、分割
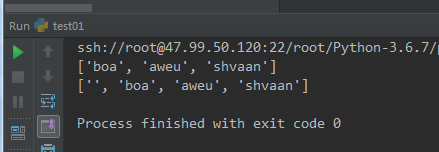
#-*-coding:utf-8-*- ''' 字符串操作 ''' # 以空格分隔。str--》list s = " boa aweu shvaan " s1 = s.split() print(s1)# 以空格区分,空格就没了 ss = ':boa:aweu:shvaan' s2 = ss.split(':') print(s2)
四、format的三种用法
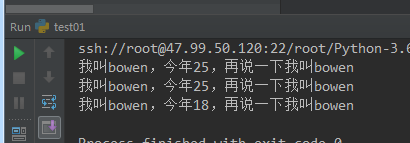
#-*-coding:utf-8-*- ''' 字符串操作 ''' #format的三种玩法,格式化输出 s = '我叫{},今年{},再说一下我叫{}'.format('bowen',25,'bowen') print(s)# 这个是不是比%s好很多,%s有多少就得写多少 s1 = '我叫{0},今年{1},再说一下我叫{0}'.format('bowen',25) print(s1)# 这种形式可以是input name来做 s2 = '我叫{name},今年{age},再说一下我叫{name}'.format(name='bowen',age = 18) print(s2)
五、替换
#-*-coding:utf-8-*- ''' 字符串操作 ''' # 全部替换 s = 'bowen是坏蛋' s1 = s.replace('bowen','苏宁是傻逼') print(s1)# 只替换一个 ss = 'bowen是坏蛋,bowen是好人' ss1 = ss.replace('bowen','苏宁真他妈恶心',1) print(ss1)

六、for 循环
#-*-coding:utf-8-*- ''' 字符串操作 ''' s = '苏宁是真他妈恶心' for i in s:print(i)

七、in 的使用
#-*-coding:utf-8-*- ''' 字符串操作 ''' s = '苏宁是真他妈恶心苍井空' if '苍井空' in s:print('苏宁真恶心')