v-model无法对返回的数据进行填写_学会数据分析思维,学会透过事物看本质
这段时间通过学习相关的知识,最大的变化就是看待事物更加喜欢去了解事物后面的本质,碰到问题后解决问题思路也发生了改变。
举个具体的例子,我在学习数据分析,将来会考虑从事这方面的工作,需要掌握的相关专业知识这个问题暂且按下不表,那哪些具体的问题是我需要了解的呢,以下简单罗列:
1、了解数据分析师这个岗位在各个地区的需求情况?
2、数据分析师的薪资待遇如何?
3、根据日后工作年限的增加,薪资待遇的增长情况会如何呢?
通过以上问题的简单罗列,我已经完成了“我该怎样进行数据分析?”的第一步:提出问题。那要进行数据分析,应该怎么做?
数据分析的流程:
第一步:提出问题;
我们应该明白,一切进行数据分析的行为(目的)都是为了解决我们生活和工作中遇到的问题,明确的问题为我们将要进行的数据分析提供了目标和方向。
第二步:理解数据,可分为以下两步骤:
1、采集数据:根据研究的问题,采集相关的数据;
2、查看采集到的数据集信息,其中包括描述统计信息,从整体上理解数据。
第三步:数据清理(数据预处理);
很多数据在被采集到的时候不符合我们数据分析的标准,里面有很多“脏”数据或重复数据,这样的数据我们就需要对它进行“整容”,把它处理成我们需要的样子。
第四步:构建模型;
对清洗后的数据进行分析,一般简单的要求是得出一些业务指标,复杂的可能需要运用机器学习算法来训练这个模型对数据进行分析。
第五步:数据可视化;
在与他人交流我们得出的研究成果的时候,最好的方式就是运用图表展现。把得出的分析结果运用图表展示给你的上级(老板)或客户。
当我们了解了数据分析的流程以后,我们就可以进行数据分析的操作了。回到上面提出的三个问题,有了明确的任务目标以后,那就是要进行第二步中的采集数据了,在这里我使用 Gooseeker 这一款免费的数据采集工具(爬虫工具)去前程无忧(51job)收集关键词“数据分析”的相关职位信息,在尝试的过程中碰到了很多问题,最大的感触就是任何一个小问题都可能导致你偏离所达成的目标很大一截,要充分学会使用搜索工具找寻相应解决方案,很多情况下都需要举一反三的去理解。
接下来我们要进行第三步,数据清理。打开我们收集的相关数据(考虑到爬虫工作的工作效能问题,我只爬取了杭州市的数据作为分析对象),首先我们根据最初提出的三个问题来简单判断哪些内容是我们需要的必要字段,哪些是不需要的,将不需要的字段所属列进行隐藏处理,养成好的习惯,不要轻易删除数据,这样在我们有可能出错的时候可以通过保留的数据找回。
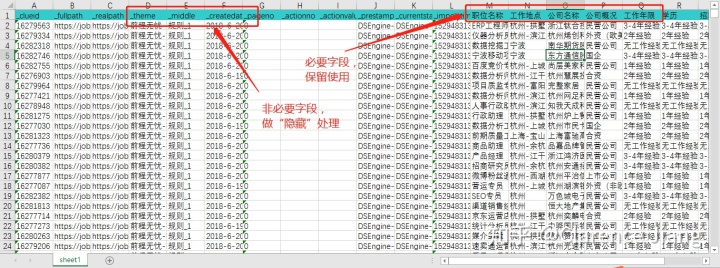
在查看数据的时候发现从“职位名称”往后一直到“薪资待遇”其中“学历”、“招聘人数”、“发布时间”这三项显示的都是“工作年限”的内容,说明我们在数据抓取的时候设置某个参数时出现了错误,依据第一步提出的三个问题做判断,得出结论出错的三项内容为非必要字段,将其做“隐藏”处理。注:如出错的是必要字段,例如:“薪资待遇”,那就要重新收集数据处理。
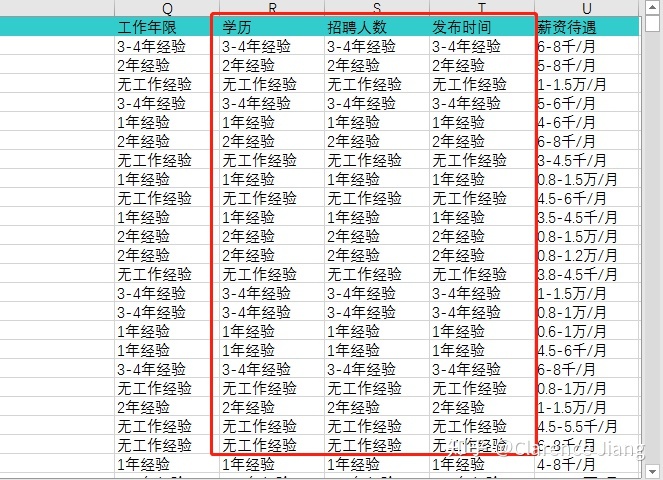
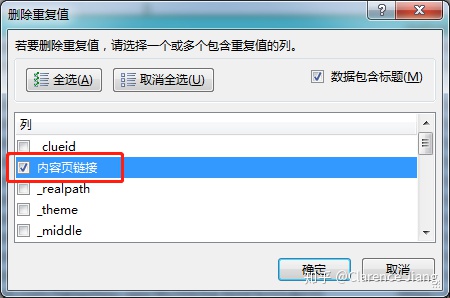
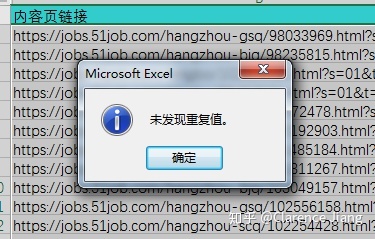
依据 Gooseeker 爬取规则的原理(二级页面依据上一级列表页的链接爬取),在这里我们选择用二级招聘信息内容展示页链接为依据做去重操作,提示“未发现重复值”,说明我们采集的数据每一条都是唯一(具体步骤:选择菜单栏中“数据”-“删除重复值”-取消全选-选择“内容页链接”项)。
由于我选择的数据是整个杭州市的“数据分析师”的招聘信息,用于判断所属“工作地点”将以“区”为依据展开,在查看数据的时候发现部分数据是以为城市为单位,这里需要对缺失值根据具体情况做出相应处理。
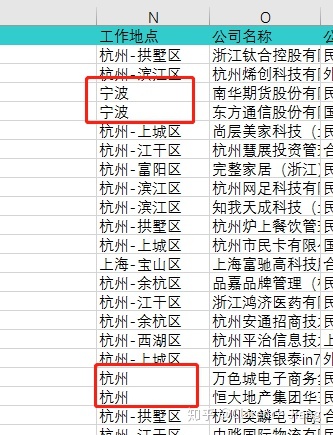
首先将“工作地点”整列复制到最后一列中进行“分列”操作(“分列”操作会把分出的数据列直接覆盖到后一列,建议复制到最后列操作最为可靠)
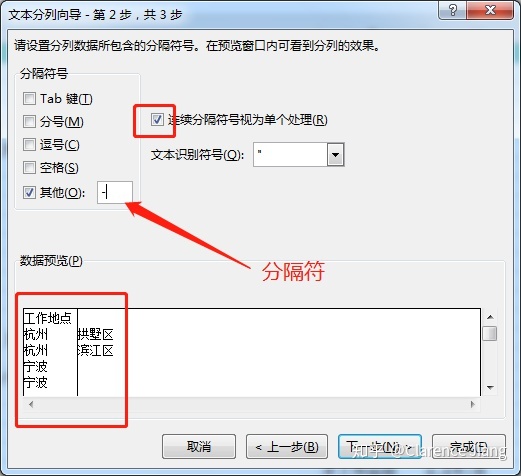
通过“刷选”功能去除非杭州城市。注:由于后续其他地方依然会使用到“刷选”功能,所有需要将怎个工作表复制到新工作表中用于保存刷选后的结果。
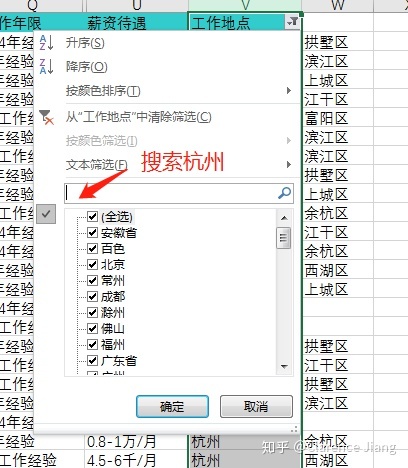
当我执行复制整个表格到新的工作表中的时候,发现 Excel 直接卡死,并提示内存不足,多次尝试后我发现原因是 Excel 工作表中有大量的隐藏列和行,或是使用“筛选”使大量的字段被隐藏后,在使用“全选”字段的时候再把大量的空白单元格也复制了(全选的时候连续按两次 ctrl+a),这样的情况就会出现上述问题,解决方案是只选择有字段的单元格即可,如下图:
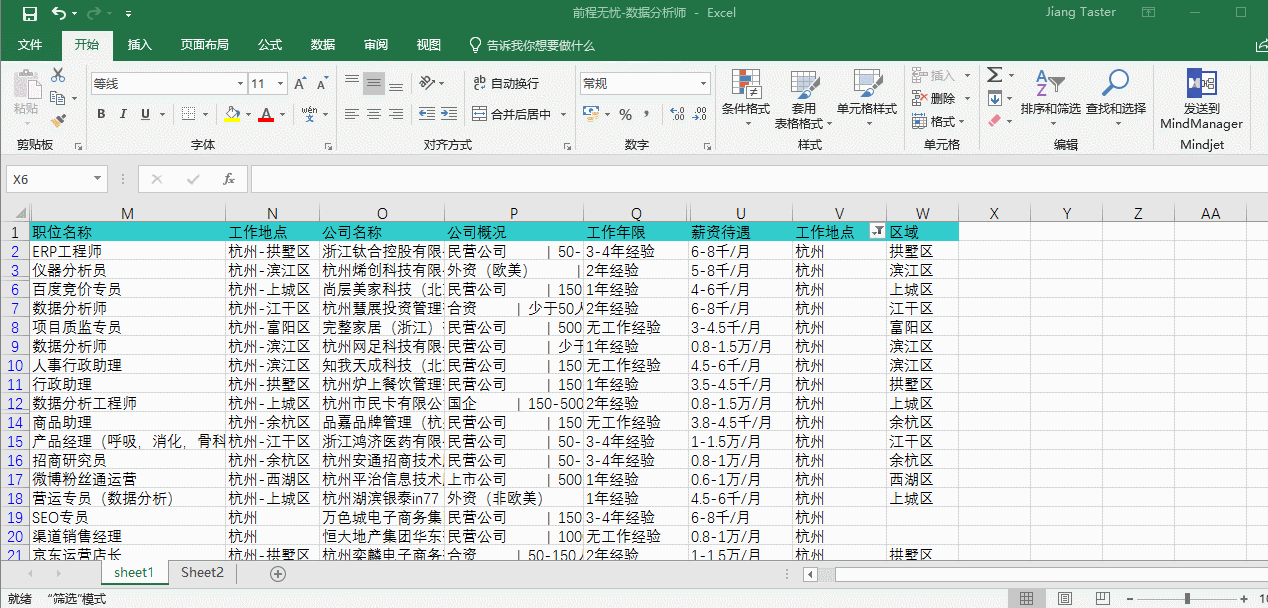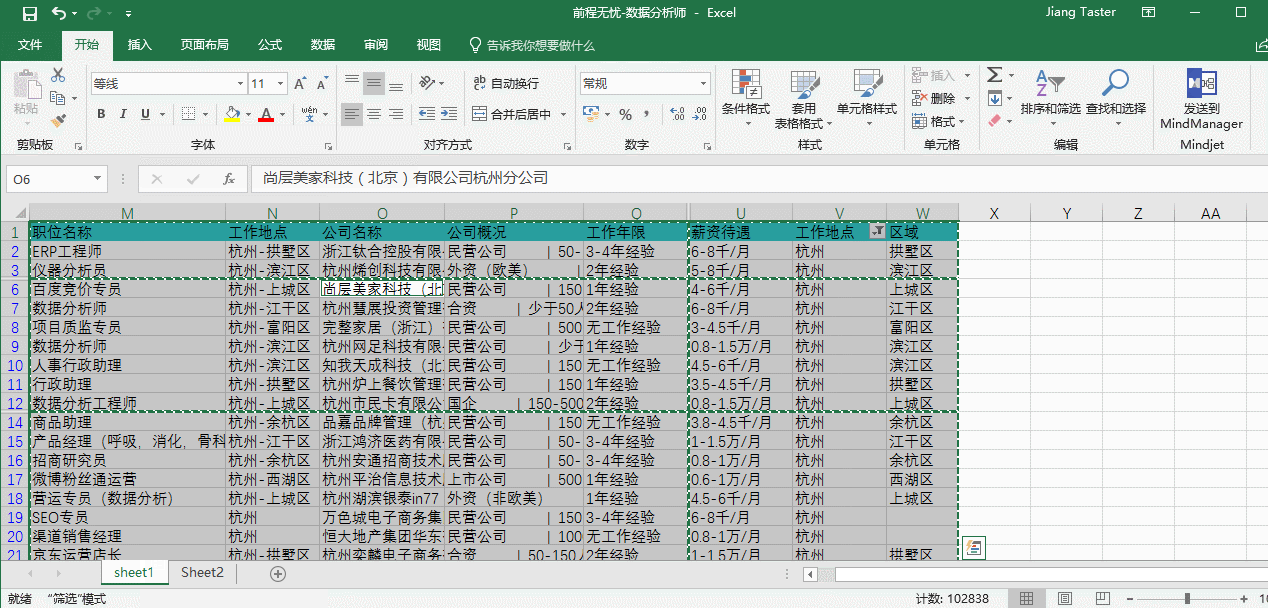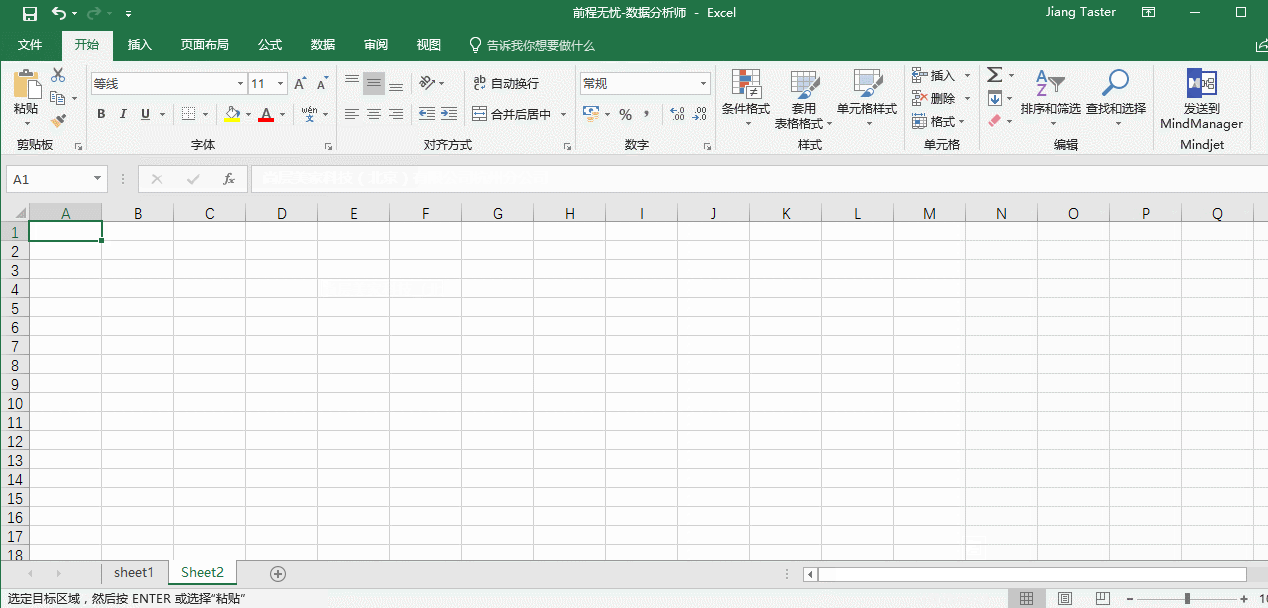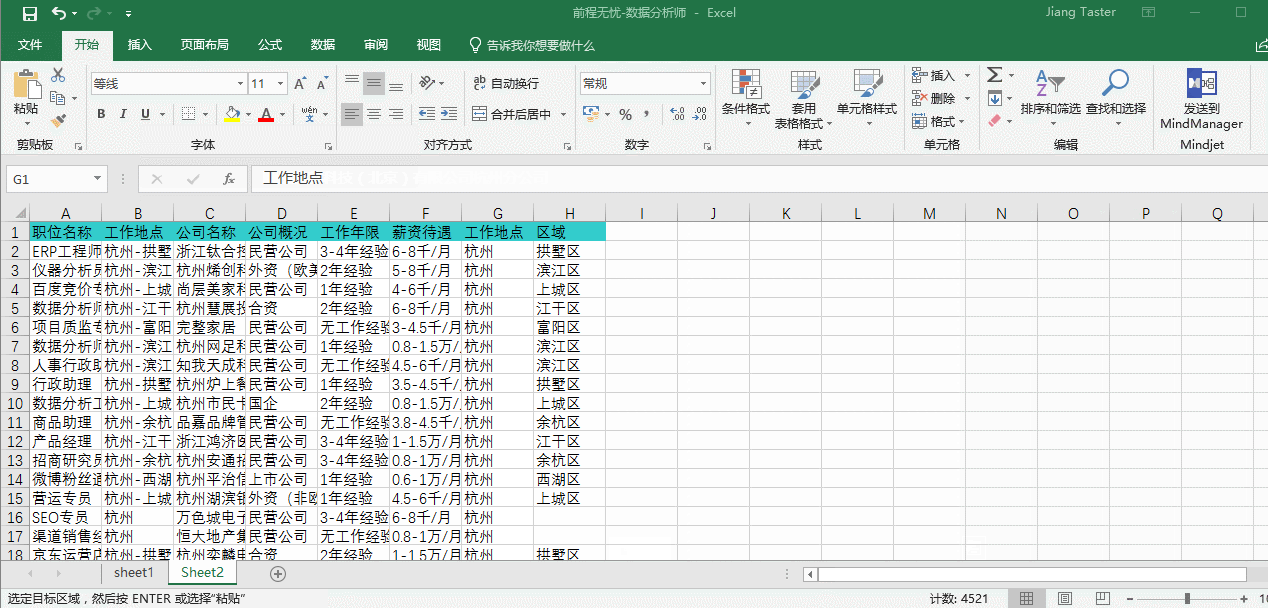
当我执行完上述操作后,查看到“详细地区”中有多处缺失值,可做如下处理:
1、首先通过通过“筛选”功能判定有多少缺失值,如果数量少,且容易通过人工甄别判断,可根据具体情况补全对应缺失值;
2、如果通过“筛选”后发现缺失值是错误收录,例如:所属地区不属于杭州,被HR错误的标记为杭州,那就做删除处理;
3、如果存在大量的缺失值,且字段属于未出错字段,是由于书写习惯或是对区域的理解不一样,比如这份数据集中可能HR对于该职位在所属公司工作性质定义为全市范围内的,这样的情况就会出现只有工作地点杭州,没有具体所属区域了,这样的情况我们可以整体套用上级标注,全体标注为“杭州”。
通过筛选空白值可以得出判断结果,详细地区缺失值多达1145处,通过“定位”功能对所有缺失值进行标记,补全字段为杭州,并通过组合快捷键 ctrl+enter 将所有缺失值全部补全,如下图:
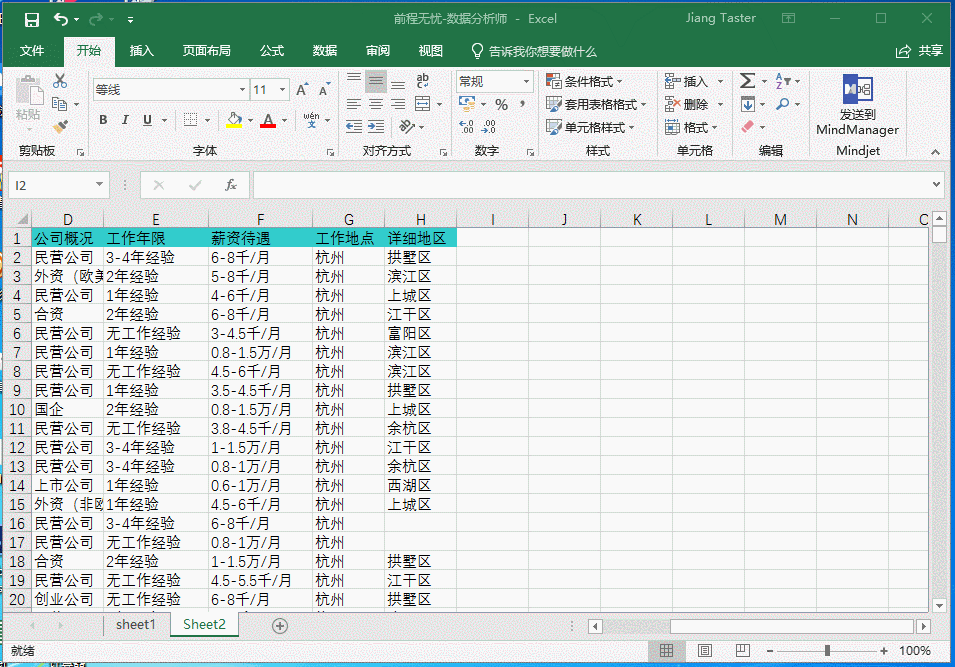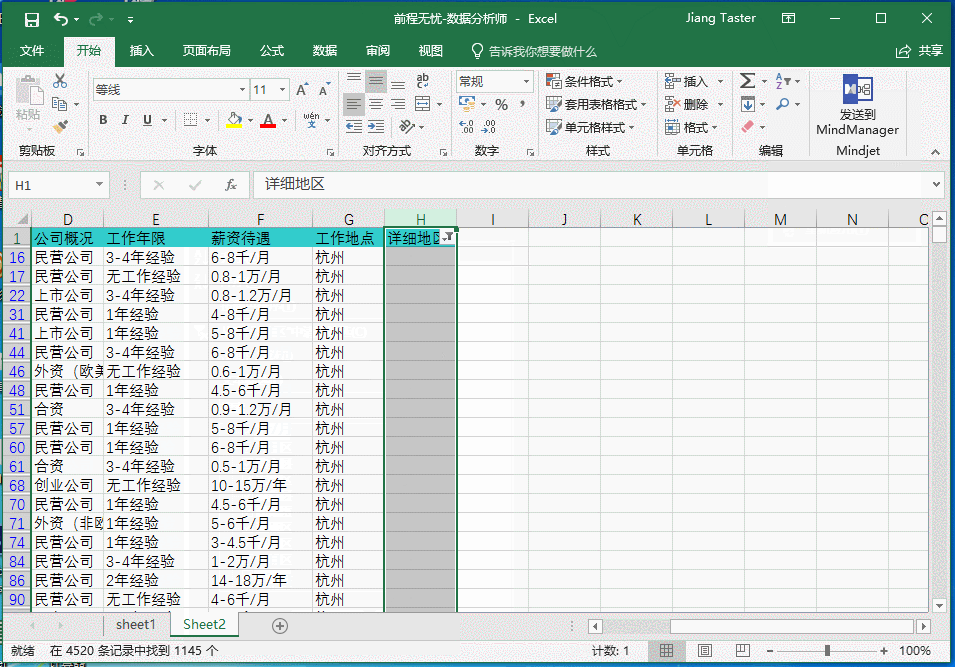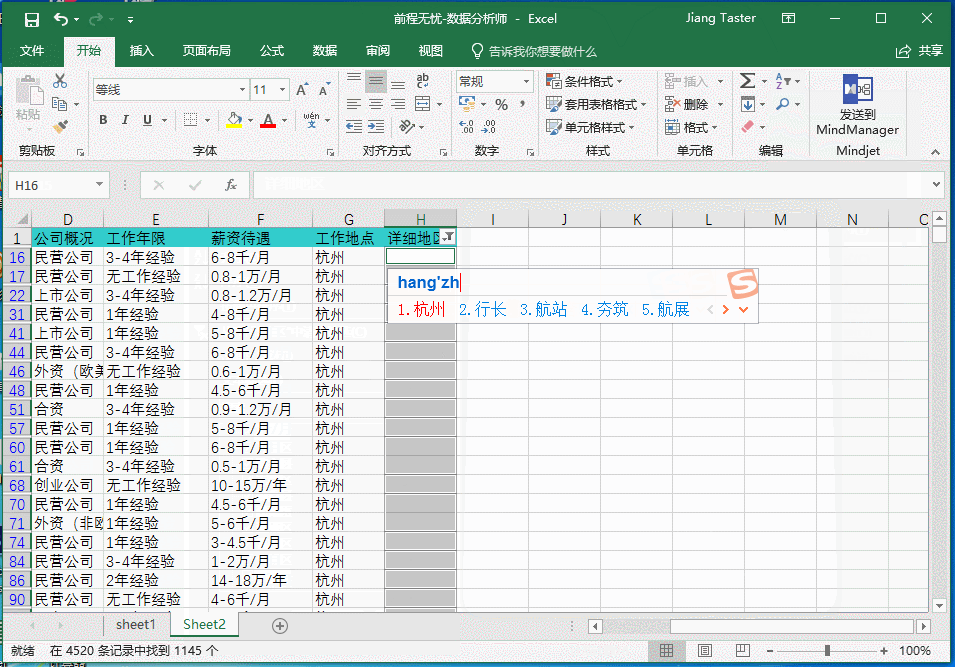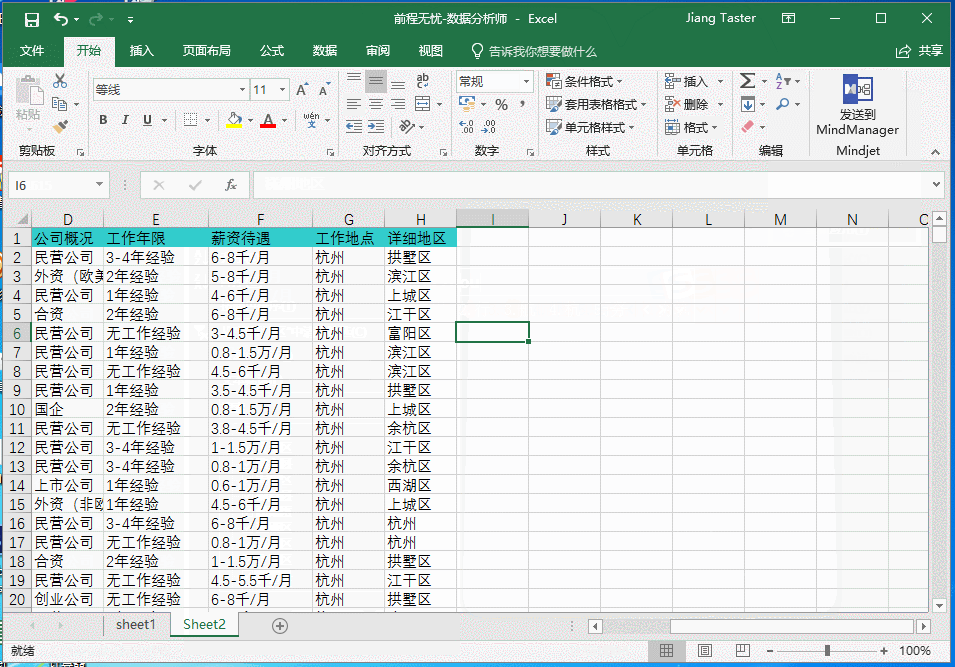
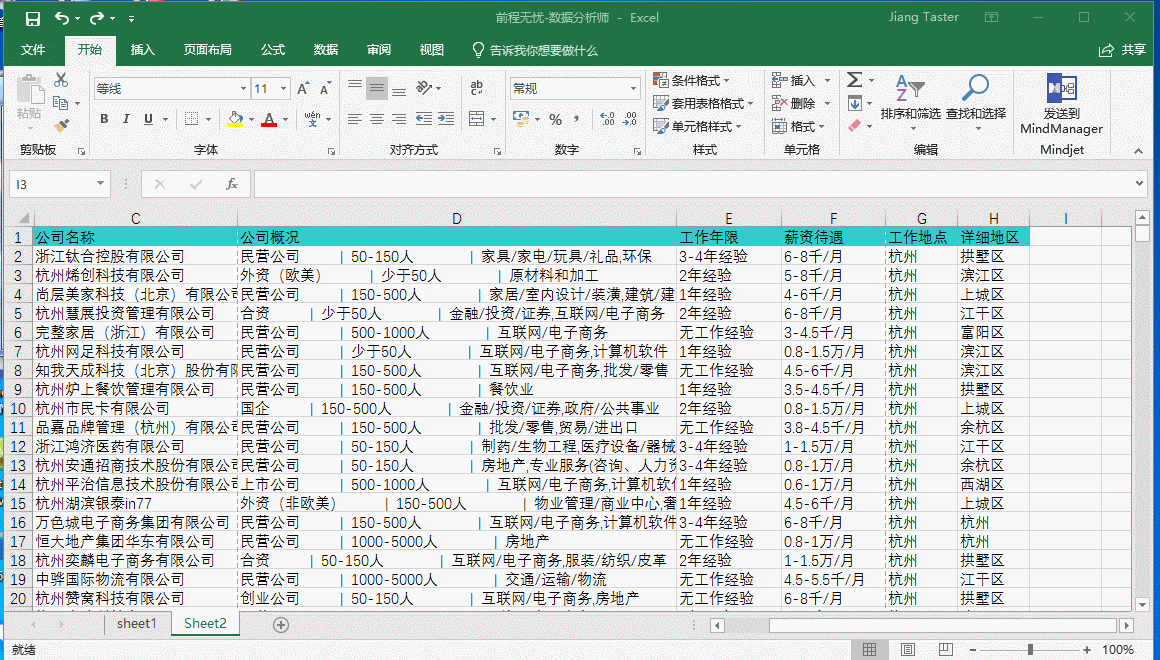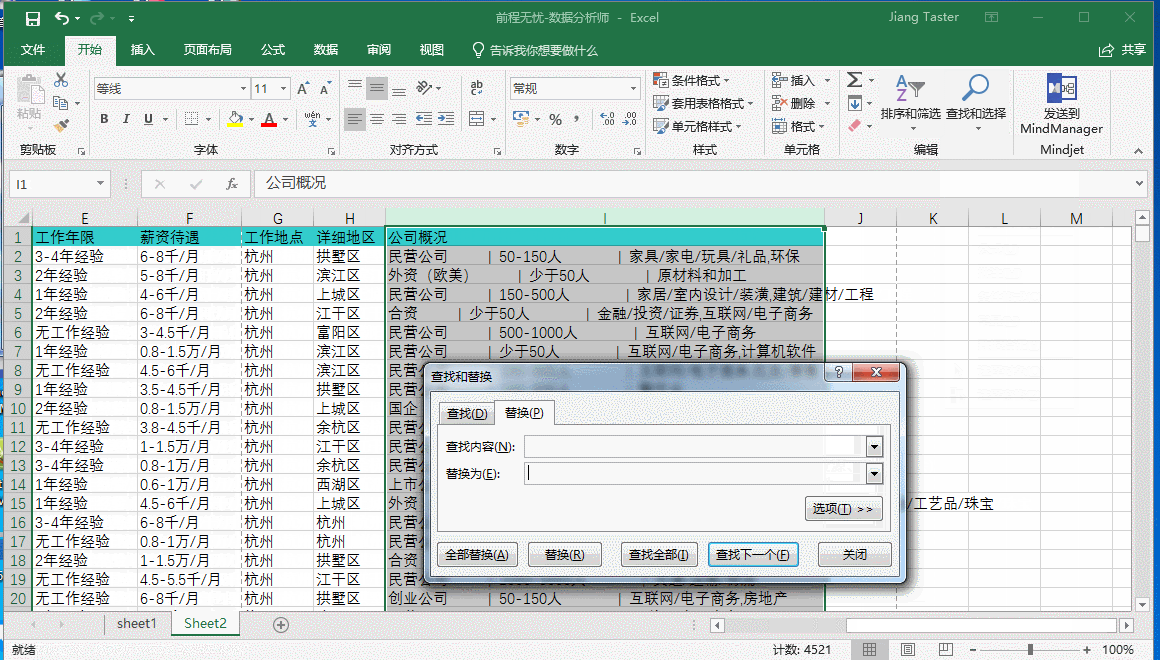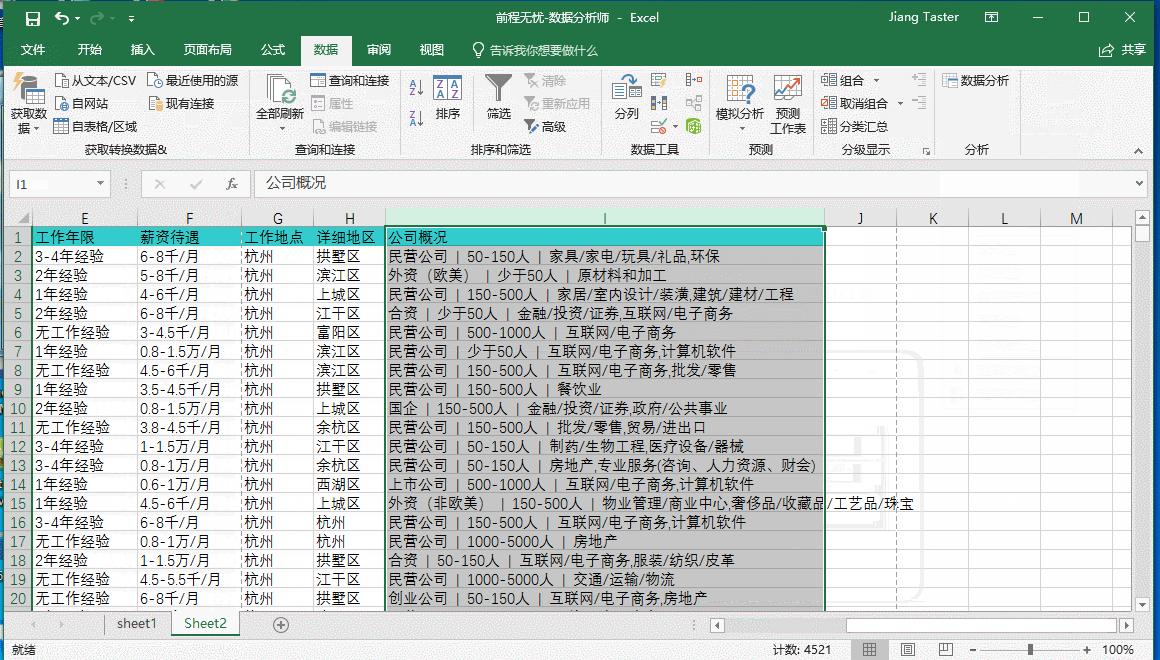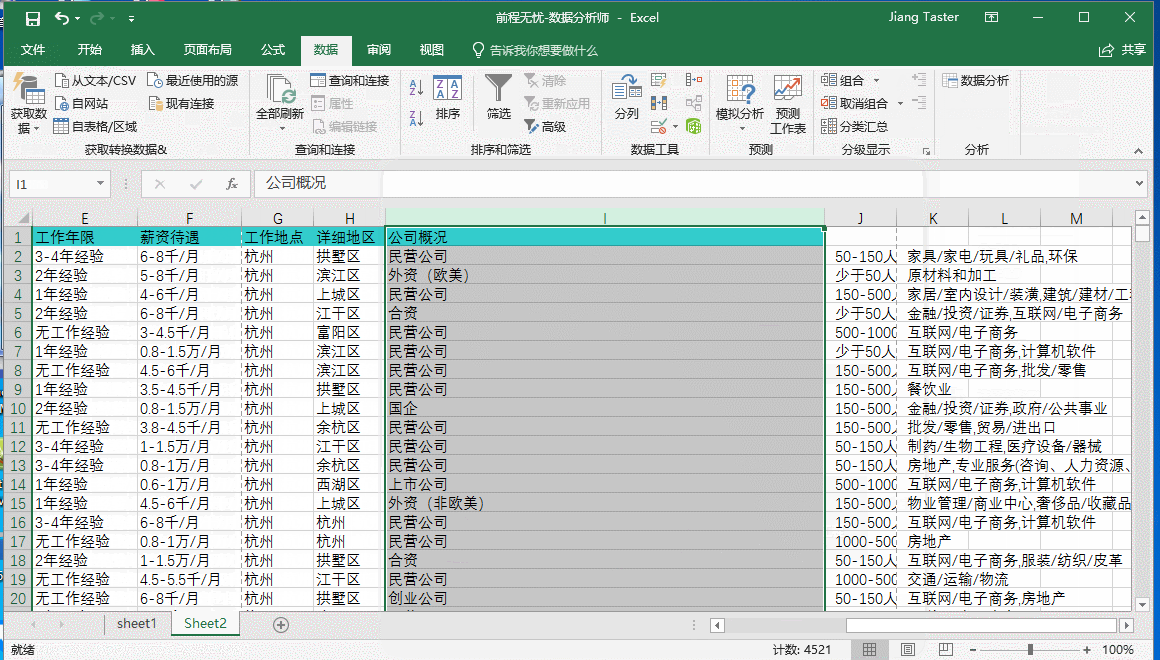
在数据采集中经常会出现多个字段被自动放在了一个单元格中的情况,比如此数据集中的“公司概况”,其中包含了三部分内容:“公司性质”、“公司大小”“所属行业”,在这里我们就要将其进行“分列”、一致化处理。
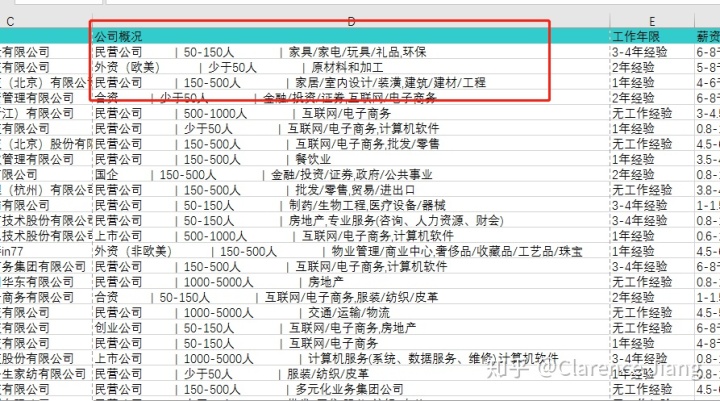
如上图所示,在公司概况中公司性质、公司大小以及所属行业之间是用“|”分割开的,我们可以用以作为“分列”的分割符号,但是首先需要通过整体替换功能去除空白值,如果是在“分列”之后再去除空白值会更加繁琐,具体操作如下:
我们要了解杭州市数据分析师的薪资待遇情况就需要对薪资待遇进行拆分为“最低薪资”、“最高薪资”、“平均薪资”,需要运用到函数Left、Mid、Find、Len、Average;但是在此之前,我们通过“筛选”观察可以看到个别“薪资待遇”HR填写的方式不太一样,例如:“XXX-XXX千/月”、“XXX-XXX万/年”“XXX元/天”“XXX元/小时”以及空置未填写,为了方便后续的一致化处理,首先做“分列”处理,把时间剥离。
通过“筛选”并删除掉未填写“薪资待遇”的无效数据,这里参考了 ExcelHome 论坛版主的方法:
Excel 筛选后的表,批量删除时时提示“无法在筛选过的区域或表中移动单元格。”-Excel基础应用-ExcelHome技术论坛 -club.excelhome.net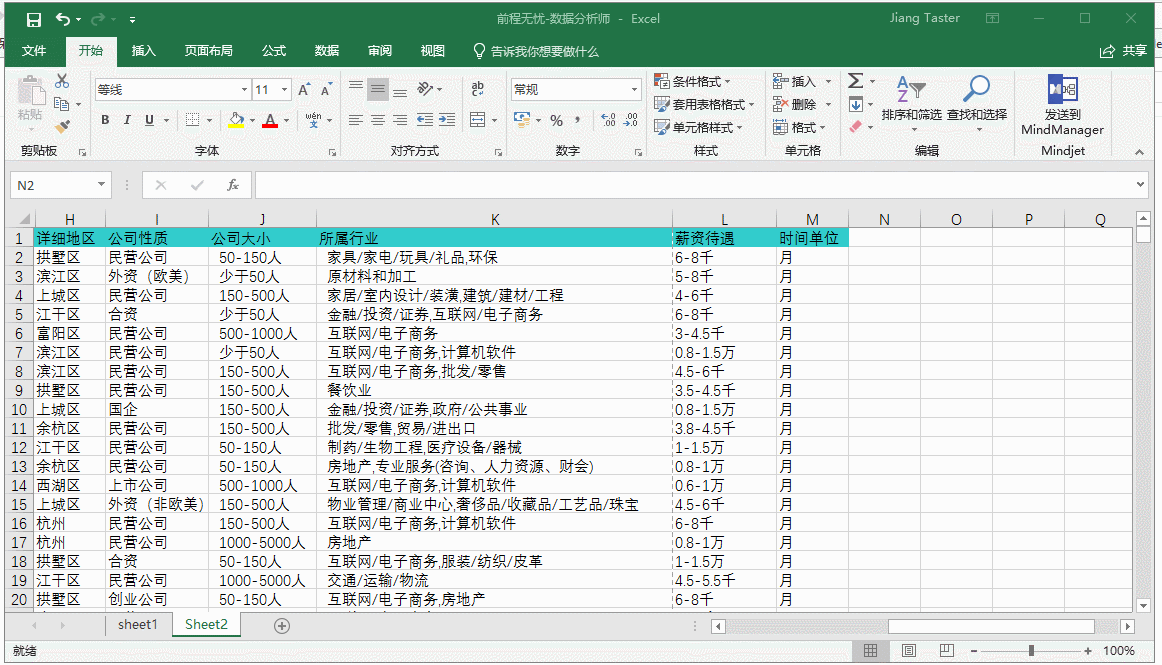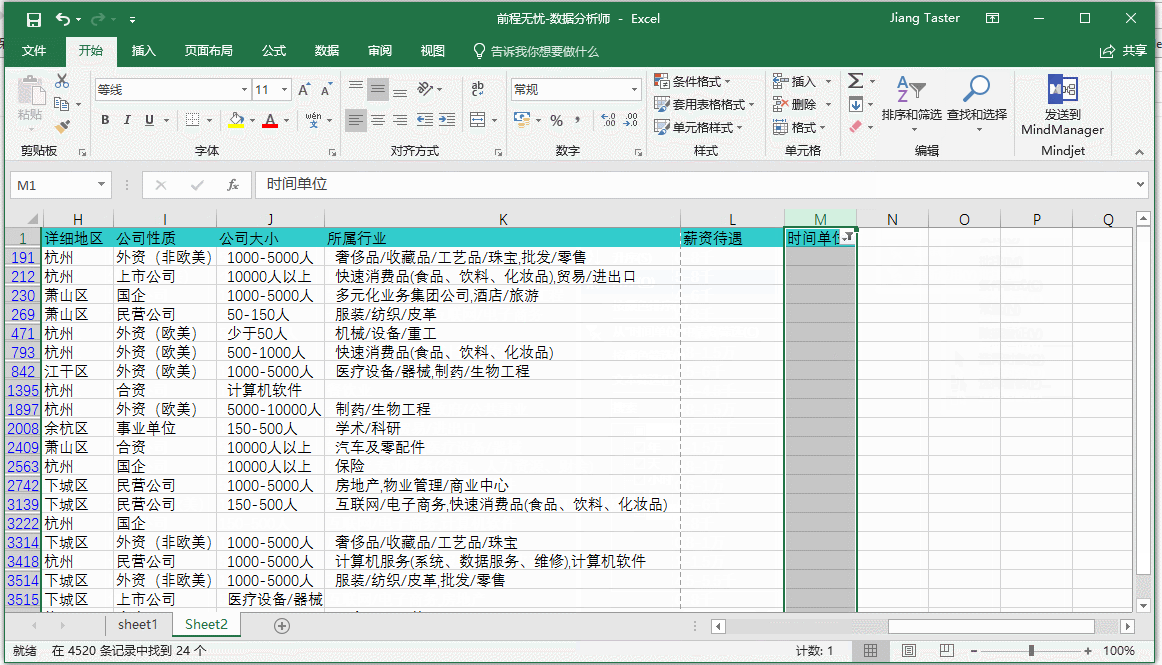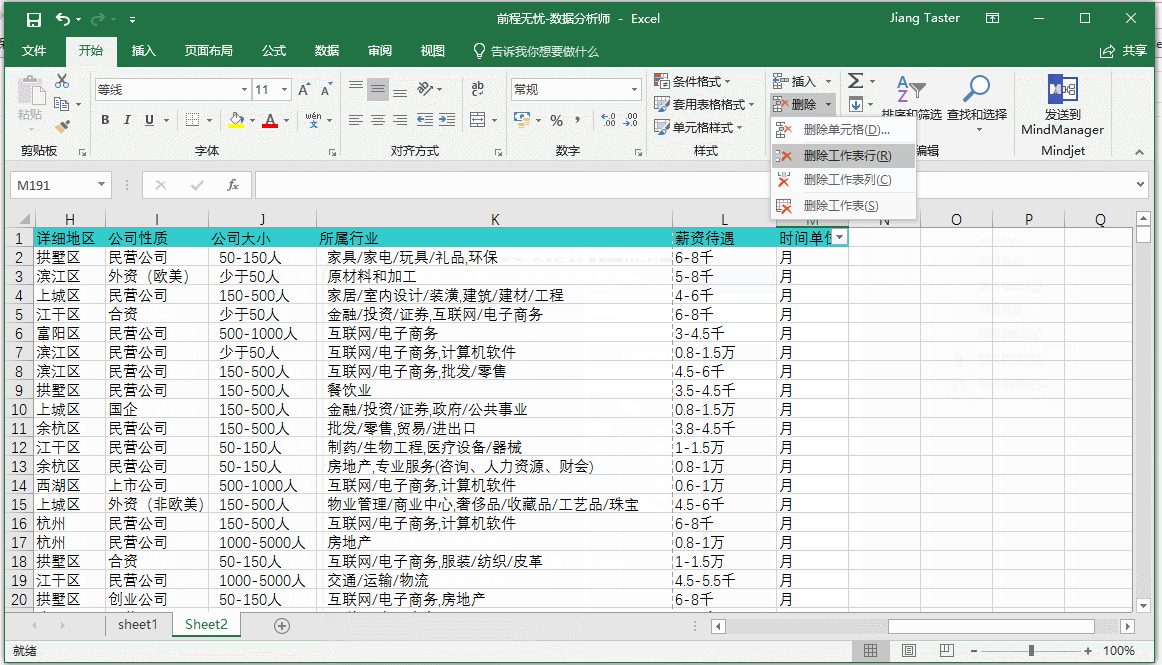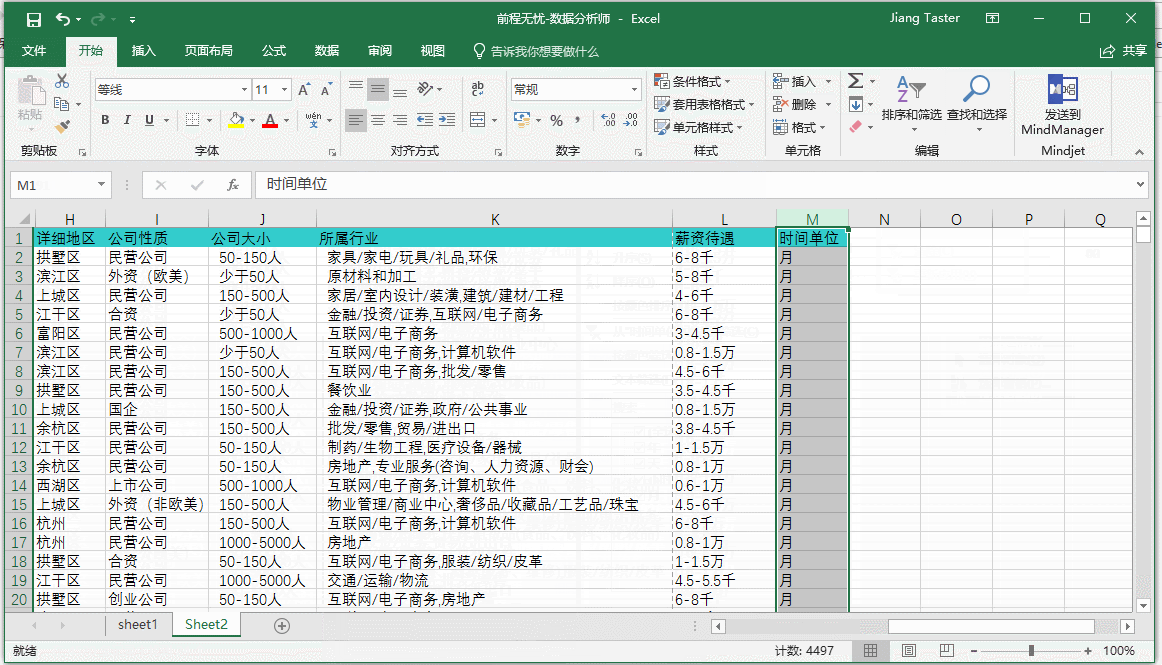
把其他单位的薪资待遇通过转换为“XXX-XXX千”格式,如下图:
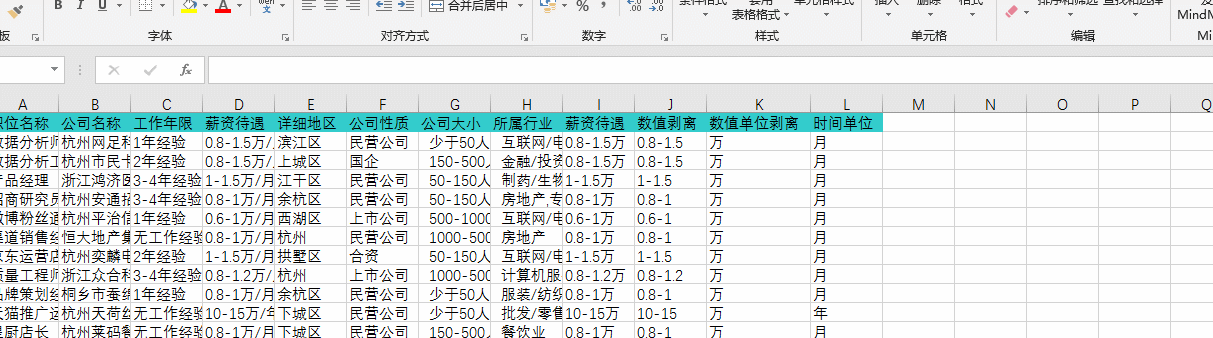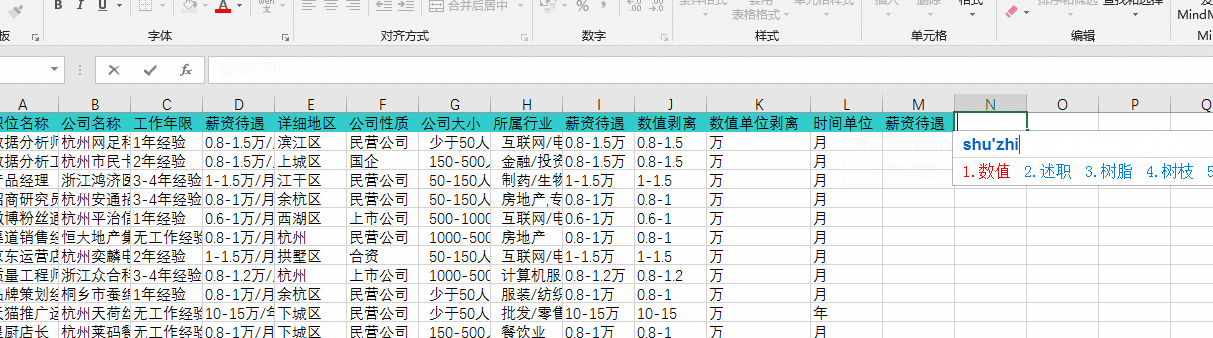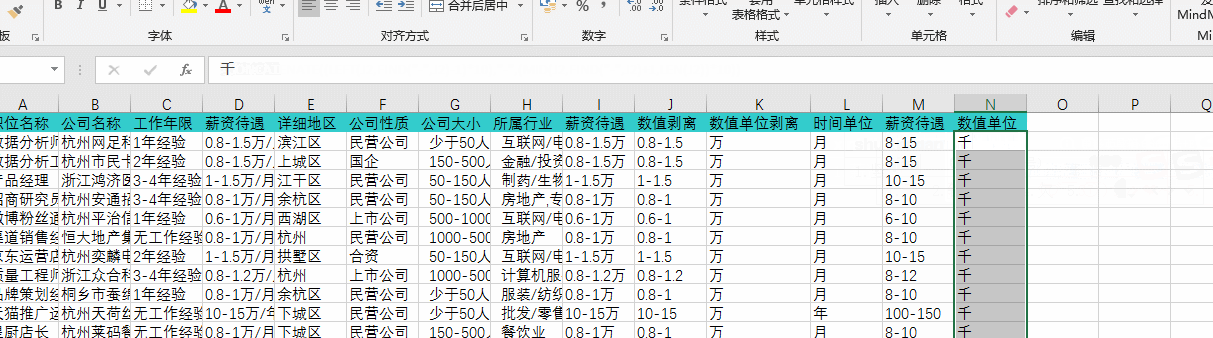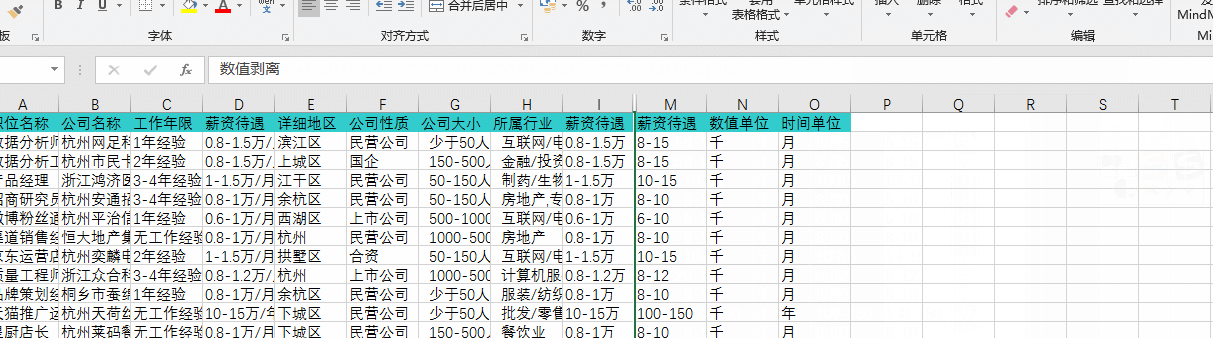
通过“筛选”查询发现有部分“薪资待遇”HR是按“年”书写的,在此要通过公式换算为“月”,如下图:
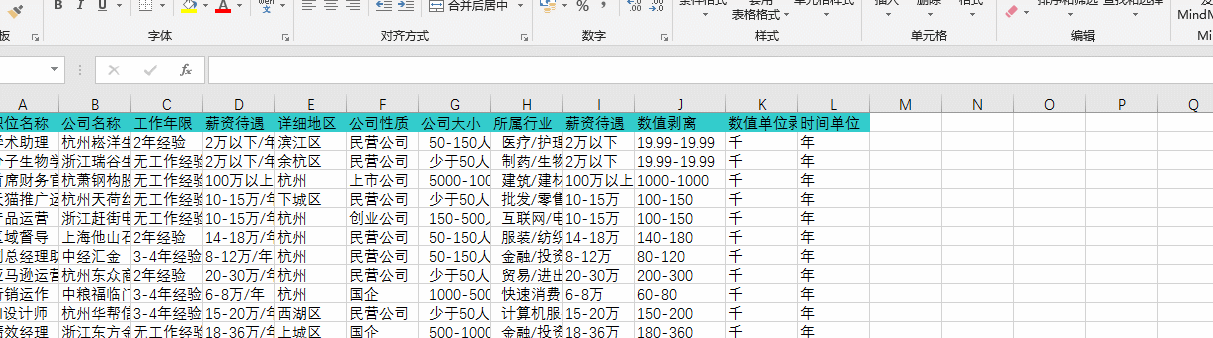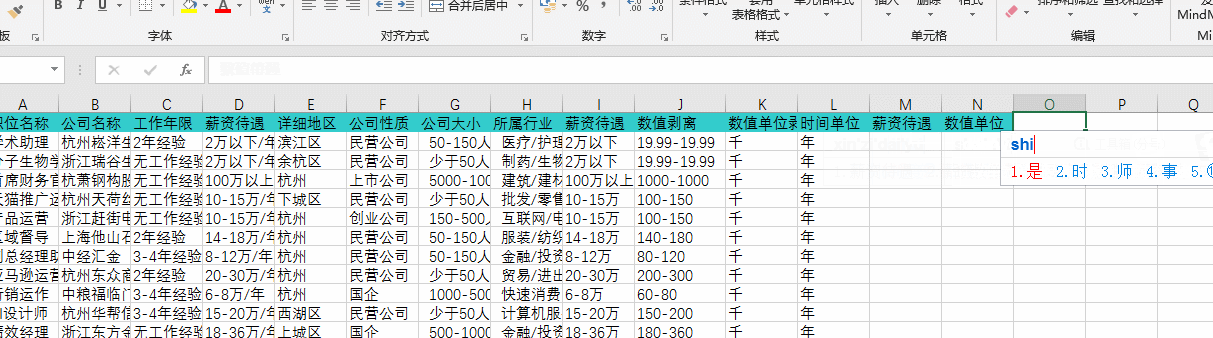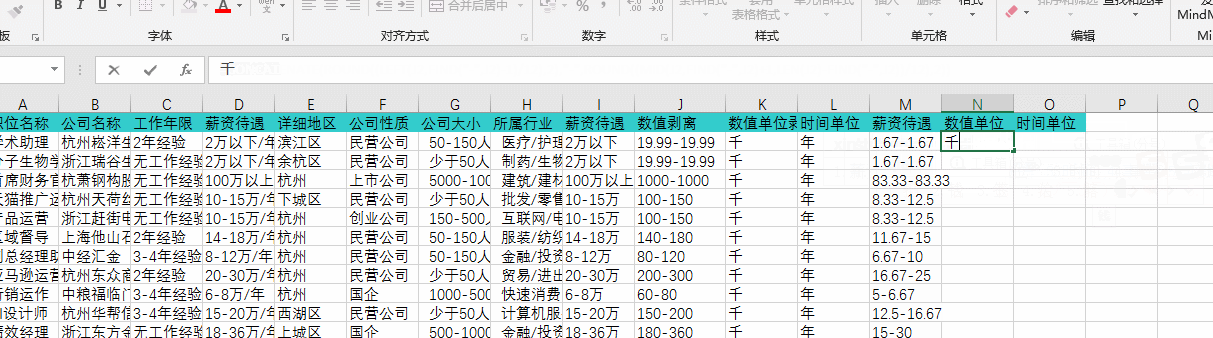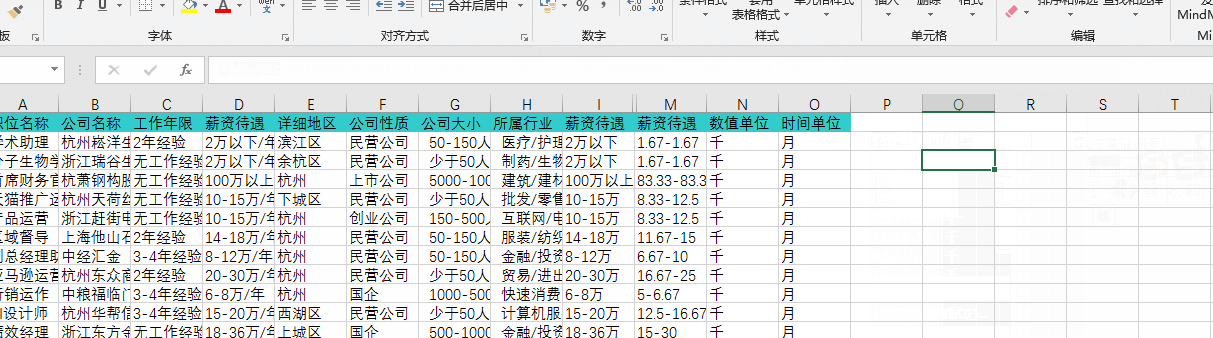
通过上述几步操作以后,我已经成功的把之前五花八门的薪资书写方式转换成了统一的格式,其中尝试过很多种方法,最重要的是要知道怎么去搜索自己想了解的一些函数,通过函数来达到转换的目的,在这次转换中我发现其实公式可以嵌套起来一起用,这样就不需要分很多列去分布书写,上图就是我通过组合嵌套公式直接换算的,可以看到公式非常长:
=CONCATENATE(ROUND((LEFT(J2,FIND("-",J2)-1)/12),2),"-",ROUND((MID(J2,FIND("-",J2)+1,LEN(J2)-FIND("-",J2))/12),2))
以下是需要运用到函数Left、Mid、Right、Find、Len、Average、Round、Concatenate;
FIND:返回一个字符串在另一个字符串中出现的起始位置(区分大小写)
语法:
FIND(find_text,within_text,start_num)
▪Find_text: 要查找的字符串。用双引号(表示空串)可匹配 Within_text 中的第一个字符,不能使用通配符;
▪Within_text: 要在其中进行搜索的字符串;
▪Start_num: 起始搜索位置,Within_text 中第一个字符的位置为 1。如果忽略,Start_num = 1。
LEFT:从一个文本字符串的第一个字符开始返回指定个数的字符
语法:
LEFT(text,num_chars)
▪Text: 要提取字符的字符串;
▪Num_chars: 要 LEFT 提取的字符数;如果忽略,为 1。
MID:从文本字符串中指定的起始位置起返回指定长度的字符
语法:
MID(text,start_num,num_chars)
▪Text: 准备从中提取字符串的文本字符串;
▪Start_num: 准备提取的第一个字符的位置。Text 中第一个字符为 1;
▪Num_chars: 指定所要提取的字符串长度。
RIGHT:从一个文本字符串的最后一个字符开始返回指定个数的字符
语法
RIGHT(text,num_chars)
▪Text: 要提取字符的字符串;
▪Num_chars: 要提取的字符数;如果忽略,为 1。
AVERAGE:返回其参数的算术平均值;参数可以是数值或包含数值的名称、数组或引用
语法:
AVERAGE(number1,number2,...)
▪Number1: 必须。要计算平均值的第一个数字、单元格引用或单元格区域;
▪Number2,...: 可选。要计算平均值的其他数字、单元格引用或单元格区域,最多可包含255个。
COUNT:计算区域中包含数字的单元格的个数
语法:
COUNT(value1,value2,...)
▪Value1: value1,value2,...是1到255个参数,可以包含或引用各种不同类型的数据,但只对数字型数据进行计算。
ROUND:按指定的位数对数值进行四舍五入
语法:
ROUND(number,num_digits)
▪Number1: 需要四舍五入的数值;
▪Num_digits: 执行四舍五入时采用的位数。如果此参数为负数,则圆整到小数点的左边;如果此参数为零,则圆整到最接近的整数。
CONCATENATE:将多个文本字符串合并成一个
语法:
CONCATENATE(text1,text2,...)
▪Text1: text1,test2,... 是1到255个要合并的文本字符串。可以是字符串、数字或对单个单元格的引用。
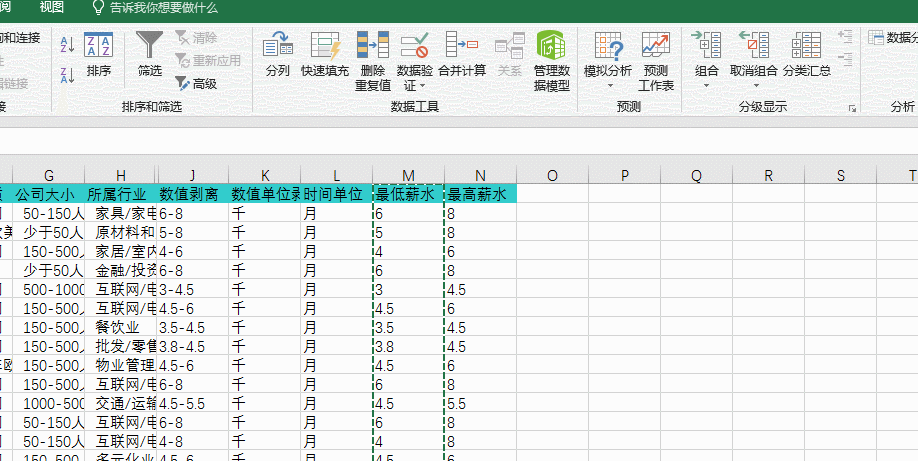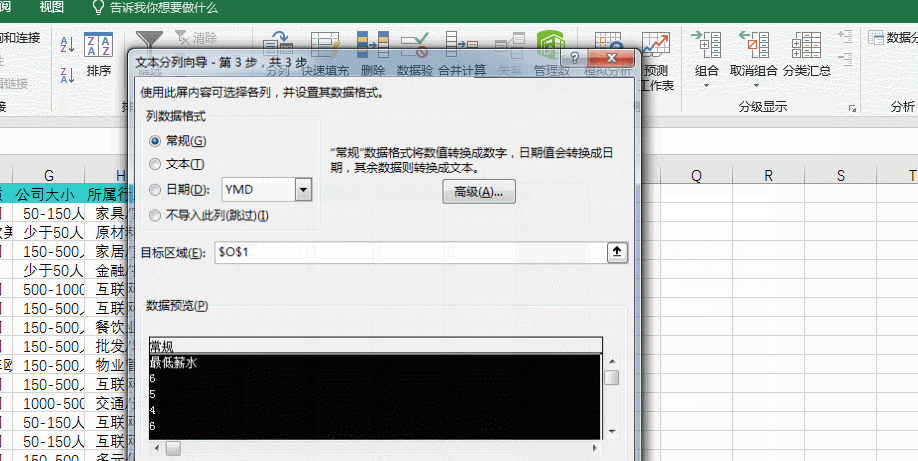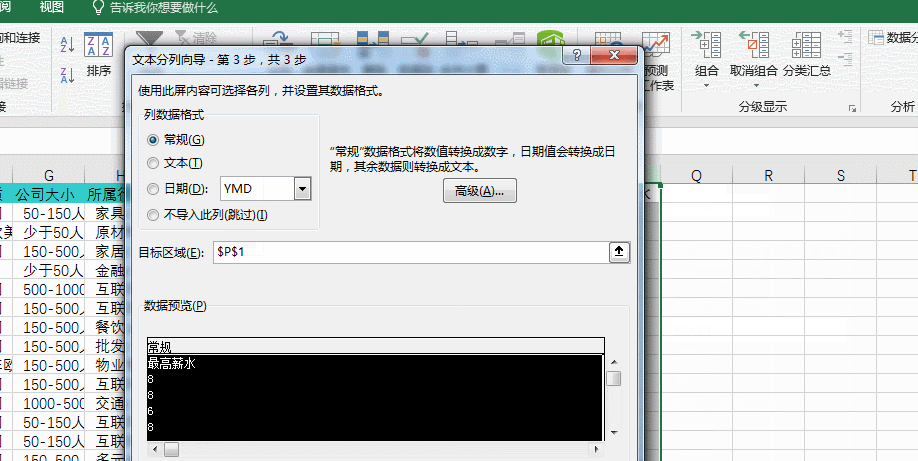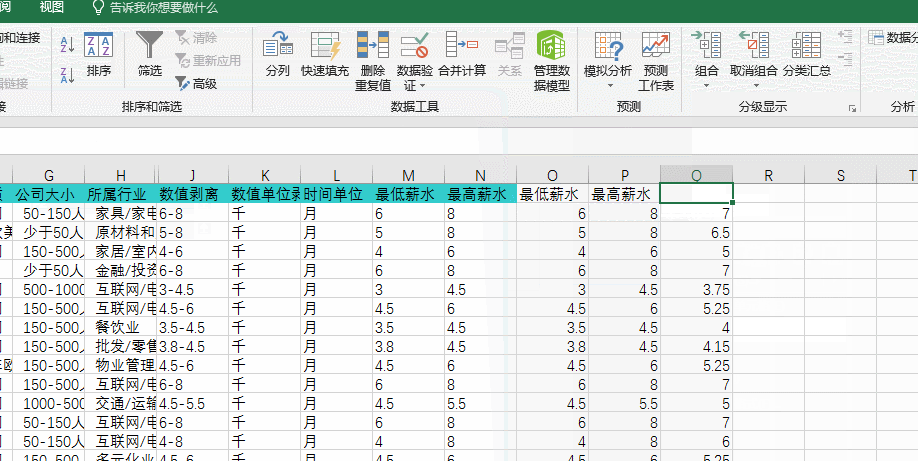
当完成了上去转换单位和时间等不同条件后将“薪资待遇”拆分成“最低薪水”、“最高薪水”、“平均薪水”就显得异常简单了,只是要注意当在求得“最低、最高薪水”以后求“平均薪水”之时需要先将文本格式的数字(求得的最低最高薪水的数值)转换为数值,可通过复制单元格并使用“分列”来转换,不然会提示被“被零除”错误。
继续一致化处理数据,我们将对职位名称进行筛选,剔除那些与“数据分析师”无关的职位,FIND 函数如果查询的字段中不包含所查询的文本所报错,例如:=FIND({"数据分析","数据运营","分析师"},R5) ,返回的值是#VALUE!,使用 COUNT 函数后会变成含有被查询文本返回数值1,不包含返回数值0,加上 IF 函数判断,可以设置为返回“是”或“否”,例:=IF(COUNT(FIND({"数据分析","数据运营","分析师"},R2),R2),"是","否")
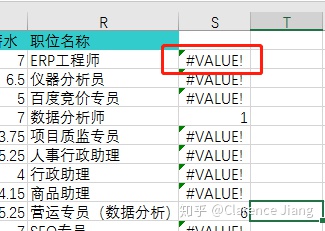
通过“筛选”工具把与数据分析无关的职业都隐藏以后,以“以最低薪水”为锚点排序收入情况,得到以下初步数据:最高平均薪水为41.665K/月,有效职位424个。
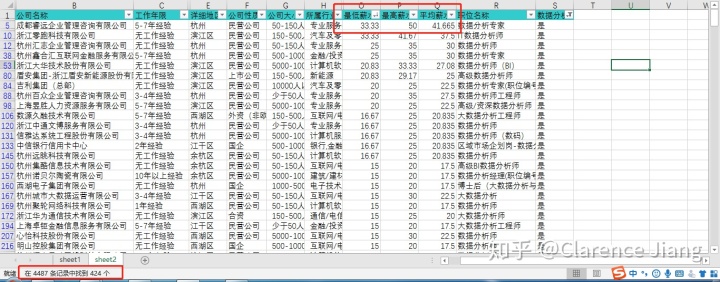
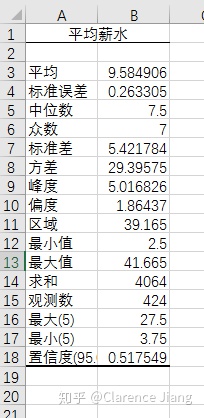
复制整张表格到新的工作表中用于数据“描述统计”得到以下数据
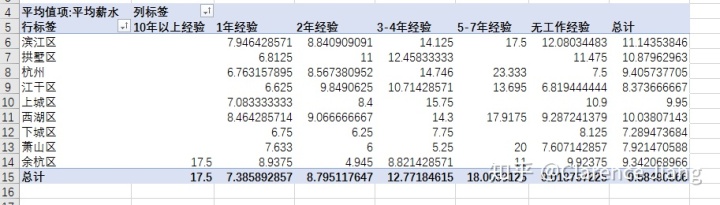
整个杭州总体薪资情况(平均K/月,例:滨江1年工作经验平均薪资7946.00元),注:表中直接显示杭州的区域是HR在发布招聘信息时为明确标注工作地所在区域,特用“杭州”代替,以下图看无经验的显示比1年工作经验的平均薪资要高应该是大量HR没有填写对应属性所致。
按百分比划分
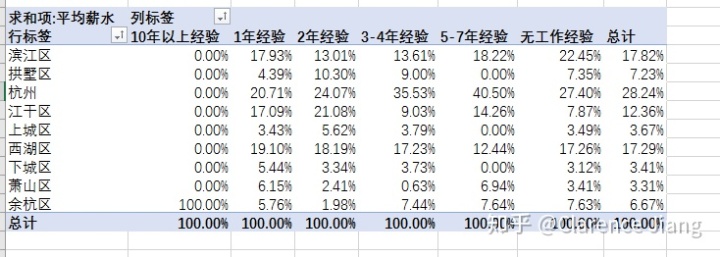
从上去分析结果可以得出:
1、滨江区、西湖区、江干区发布的招聘信息相对比较多,大量的人才需求集中在3-7年工作经验;
2、整个杭州市数据分析师的薪资平时在9.5K左右,中位数在7.5,相比互联网其他岗位不算很出众,但是发展潜力巨大,随着工作年限的增加,薪资涨幅也还不错;
3、将来从事数据分析相关工作可以考虑选择其它城市发展,比如北上广等超一线城市。
更多相关:
-
本文是西门子开放式TCP通信的第2篇,上一篇我们讲了使用西门子1200PLC作为TCP服务器的程序编写,可以点击下方链接阅读:【公众号dotNet工控上位机:thinger_swj】基于Socket访问西门子PLC系列教程(一)在完成上述步骤后,接下来就是编写上位机软件与PLC之间进行通信。上位机UI界面设计如下图所示:从上图可以看出...
-
我有一个大型数据集,列出了在全国不同地区销售的竞争对手产品。我希望通过使用这些新数据帧名称中的列值的迭代过程,根据区域将该数据帧分成几个其他区域,以便我可以分别处理每个数据帧-例如根据价格对每个地区的信息进行排序,以了解每个地区的市场情况。我给出了以下数据的简化版本:Competitor Region ProductA Product...
-
作为一名IT从业者,我来回答一下这个问题。首先,对于具有Java编程基础的人来说,学习Python的初期并不会遇到太大的障碍,但是要结合自己的发展规划来制定学习规划,尤其要重视学习方向的选择。Java与Python都是比较典型的全场景编程语言,相比于Java语言来说,当前Python语言在大数据、人工智能领域的应用更为广泛一些,而且大...
-
这一节将开始学习python的一个核心数据分析支持库---pandas,它是python数据分析实践与实战的必备高级工具。对于使用 Python 进行数据分析来说,pandas 几乎是无人不知,无人不晓的。今天,我们就来认识认识数据分析界鼎鼎大名的 pandas。目录一. pandas主要数据结构 SeriesDataFrame二...
-
英语的重要性,毋庸置疑!尤其对广大职场人士,掌握英语意味着就多了一项竞争的技能。那,对于我们成人来说,时间是最宝贵的。如何短时间内在英语方面有所突破,这是我们最关心的事情。英语学习,到底有没有捷径可以走,是否可以速成?周老师在这里明确告诉大家,英语学习,没有绝对的捷径走,但是可以少走弯路。十多年的教学经验告诉我们,成功的学习方法可以借...
-
展开全部 其实IDLE提供了一个显32313133353236313431303231363533e78988e69d8331333365663438示所有行和所有字符的功能。 我们打开IDLE shell或者IDLE编辑器,可以看到左下角有个Ln和Col,事实上,Ln是当前光标所在行,Col是当前光标所在列。 我们如果想得到文件代码...
-
前言[1]从 Main 方法说起[2]走进 Tomcat 内部[3]总结[4]《Java 2019 超神之路》《Dubbo 实现原理与源码解析 —— 精品合集》《Spring 实现原理与源码解析 —— 精品合集》《MyBatis 实现原理与源码解析 —— 精品合集》《Spring MVC 实现原理与源码解析 —— 精品合集》《Spri...
-
【本文摘要】【注】本文所述内容为学习Yjango《学习观》相关视频之后的总结,观点归Yjango所有,本文仅作为学习之用。阅读本节,会让你对英语这类运动类知识的学习豁然开朗,你会知道英语学习方面,我们的症结所在。学习英语这类运动类知识,需要把握四个原则第一,不要用主动意识。第二,关注于端对端第三,输入输出符合实际情况第四,通过多个例子...
-
点云PCL免费知识星球,点云论文速读。文章:RGB-D SLAM with Structural Regularities作者:Yanyan Li , Raza Yunus , Nikolas Brasch , Nassir Navab and Federico Tombari编译:点云PCL代码:https://github.co...
-
文章目录Ptrace 的使用GDB 的基本实现原理Example1 通过ptrace 修改 被追踪进程的内存数据Example2 通过ptrace 对被追踪进程进行单步调试Ptrace的实现PTRACE_TRACEMEPTRACE_ATTACHPTRACE_CONTPTRACE_SINGLESTEPPTRACE_PEEKDATAPTR...
-
在通过GridView取一个单元格(cell)的值时,数据库中为NULL,而页面上显示为空格。发现通过gridview.cell[i].text取出来的值为 ,导致获取数据出现问题。 解决方法: 一、利用Server.HtmlDecode(string)进行转换 二、设置该字段NullDisplayText=" ",取值...