sklearn中的xgboost_xgboost来了

一.xgboost前奏
1,介绍一下啥是xgboost
XGBoost全称是eXtreme Gradient Boosting,即极限梯度提升算法。它由陈天奇所设计,致力于让提升树突破自身的计算极限,以实现运算快速,性能优秀的工程目标。2,XGBoost的三大构件
XGBoost本身的核心是基于梯度提升树实现的集成算法,整体来说可以有三个核心部分:集成算法本身,用于集成的弱评估器,以及应用中的其他过程。三个部分中,前两个部分包含了XGBoost的核心原理以及数学过程,最后的部分主要是在XGBoost应用中占有一席之地。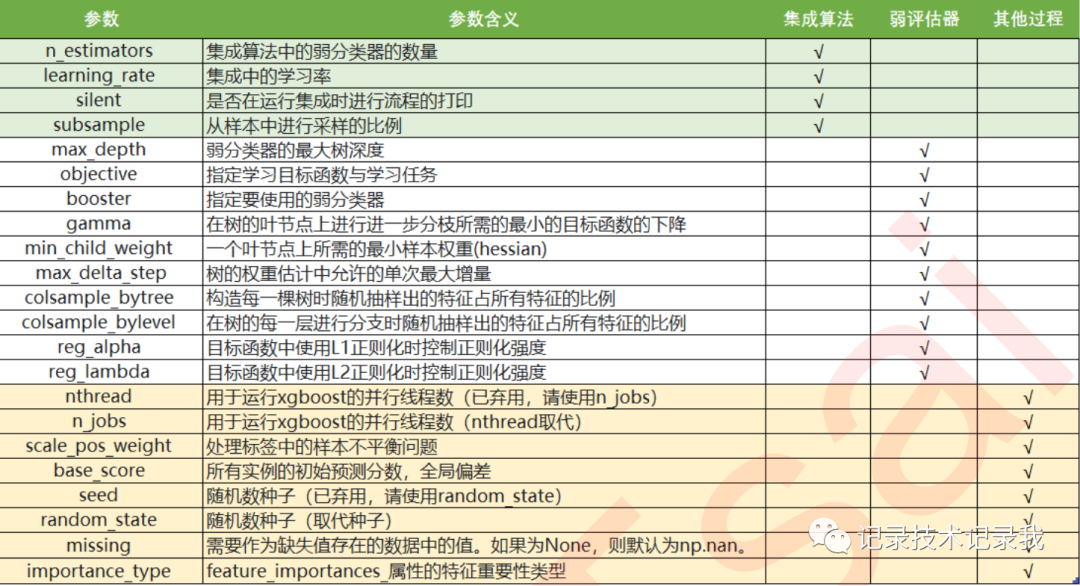
二.梯度提升树:xgboost的基础
1,核心参数:n_estimators
集成算法通过在数据上构建多个弱评估器,汇总所有弱评估器的建模结果以获取比单个模型更好的回归或分类表现。n_estimators就是弱分类器的个数:n_estimators越大,模型的学习能力就会越强,模型也越容易过拟合。1),首先XGB中的树的数量决定了模型的学习能力,树的数量越多,模型的学习能力越强。只要XGB中树的数量足够了,即便只有很少的数据,模型也能够学到训练数据100%的信息,所以XGB也是天生过拟合的模型。但在这种情况 下,模型会变得非常不稳定。
2),XGB中树的数量很少的时候,对模型的影响较大,当树的数量已经很多的时候,对模型的影响比较小,只能有 微弱的变化。当数据本身就处于过拟合的时候,再使用过多的树能达到的效果甚微,反而浪费计算资源。当唯一指标
或者准确率给出的n_estimators看起来不太可靠的时候,我们可以改造学习曲线来帮助我们。
3),第三,树的数量提升对模型的影响有极限,最开始,模型的表现会随着XGB的树的数量一起提升,但到达某个点之后,树的数量越多,模型的效果会逐步下降,这也说明了暴力增加n_estimators不一定有效果。
这些都和随机森林中的参数n_estimators表现出一致的状态。在随机森林中我们总是先调整n_estimators,当n_estimators的极限已达到,我们才考虑其他参数,但XGB中的状况明显更加复杂,当数据集不太寻常的时候会更加 复杂。这是我们要给出的第一个超参数,因此还是建议优先调整n_estimators,一般都不会建议一个太大的数目, 300以下为佳。2,有放回随机抽样:重要参数subsample
随机抽样的时候抽取的样本比例,范围(0,1],在sklearn中,我们使用参数subsample来控制我们的随机抽样。在xgb和sklearn中,这个参数都默认为1且不能取到0,这说明我们无法控制模型是否进行随机有放回抽样,只能控制抽样抽出来的样本量大概是多少。采样还对模型造成了什么样的影响呢?采样会减少样本数量,而从学习曲线来看样本数量越少模型的过拟合会越严重,因为对模型来说数据量越少模型学习越容易,学到的规则也会越具体越不适用于测试样本。所以subsample参数通常是在样本量本身很大的时候来调整和使用。一般保持默认就好。3,迭代决策树:重要参数eta
在sklearn中,我们使用参数learning_rate来干涉我们的学习速率:
集成中的学习率,又称为步长,以控制迭代速率,常用于防止过拟合。
xgb.train():eta,默认0.3 取值范围[0,1]
xgb.XGBRegressor():learning_rate,默认0.1 取值范围[0,1]
现在来看,我们的梯度提升树可是说是由三个重要的部分组成:
一个能够衡量集成算法效果的,能够被最优化的损失函数
一个能够实现预测的弱评估器
一种能够让弱评估器集成的手段,包括我们讲解的迭代方法,抽样手段,样本加权等等过程
三.XGBoost
1,选择弱评估器:重要参数booster
参数“booster"来控制我们究竟使用怎样的弱评估器。可供选择的有这些:"gbtree", "gblinear", "dart"2.XGB的目标函数:重要参数objective
XGB的损失函数实现了模型表现和运算速度的平衡。普通的损失函数,比如错误率,均方误差等,都只能够衡量模型的表现无法衡量模型的运算速度。我们曾在许多模型中使用空间复杂度和时间复杂度来衡量模型的运算效率。XGB因此引入了模型复杂度来衡量算法的运算效率。因此XGB的目标函数被写作:传统损失函数 + 模型复杂度。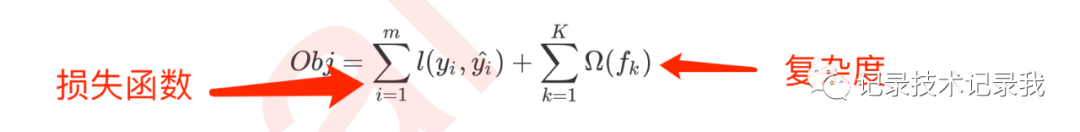
常见的选择有
输入 | 选用的损失函数 |
reg:linear | 使用线性回归的损失函数,均方误差,回归时使用 |
binary:logistic | 使用逻辑回归的损失函数,对数损失log_loss,二分类时使用 |
binary:hinge | 使用支持向量机的损失函数,Hinge Loss,二分类时使用 |
multi:softmax | 使用softmax损失函数,多分类时使用 |
xgb自身的调用方式

# encoding=utf-8from sklearn.metrics import r2_score# 默认reg:linearreg = XGBR(n_estimators=180, random_state=420).fit(Xtrain, Ytrain)reg.score(Xtest, Ytest)MSE(Ytest, reg.predict(Xtest))# xgb实现法import xgboost as xgb# 1,使用类Dmatrix读取数据dtrain = xgb.DMatrix(Xtrain, Ytrain)dtest = xgb.DMatrix(Xtest, Ytest)# 2,写明参数,silent默认为False,通常需要手动将它关闭param = {'silent': False, 'objective': 'reg:linear', "eta": 0.1}num_round = 180# 3,类train,可以直接导入的参数是训练数据,树的数量,其他参数都需要通过params来导入bst = xgb.train(param, dtrain, num_round)# 4,接口predictr2_score(Ytest, bst.predict(dtest))MSE(Ytest, bst.predict(dtest))3,寻找最佳分枝:结构分数之差
贪婪算法指的是控制局部最优来达到全局最优的算法,决策树算法本身就是一种使用贪婪算法的方法。XGB作为树的集成模型,自然也想到采用这样的方法来进行计算,所以我们认为,如果每片叶子都是最优,则整体生成的树结构就是最优,如此就可以避免去枚举所有可能的树结构。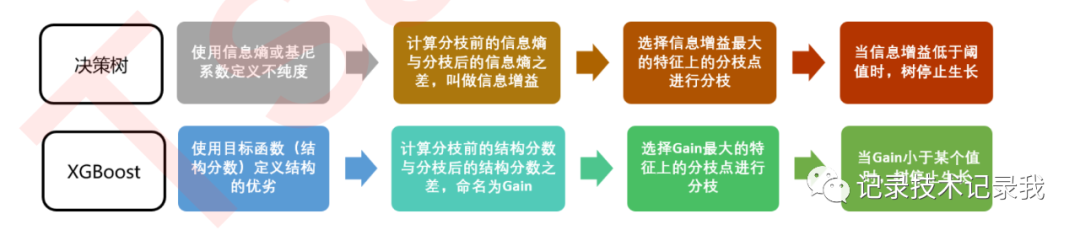
4,让树停止生长:重要参数gamma
从目标函数和结构分数之差的式子中来看,它是我们每增加一片叶子就会被剪去的惩罚项。增加的叶子越多,结构分数之差会被惩罚越重,所以它又被称之为是“复杂性控制”.所以 是我们用来防止过拟合的重要参数。实践证明,它是对梯度提升树影响最大的参数之一,其效果丝毫不逊色于n_estimators和防止过拟合的神器max_depth。同时,它还是我们让树停止生长的重要参数。在XGB中,我们规定只要结构分数之差Gain是大于0的,即只要目标函数还能够继续减小,我们就允许树继续进行分枝。我们可以直接通过设定γ的大小来让XGB中的树停止生长。γ因此被定义为:在树的叶节点上进行进一步分枝所需的最小目标函数减少量,在决策树和随机森林中也有类似的参数(min_split_loss,min_samples_split)。设定 越大,算法就越保守,树的叶子数量就越少,模型的复杂度就越低。四. XGBoost应用中的其他问题
1,过拟合:剪枝参数与回归模型调参
作为天生过拟合的模型,XGBoost应用的核心之一就是减轻过拟合带来的影响。作为树模型,减轻过拟合的方式主要是靠对决策树剪枝来降低模型的复杂度,以求降低方差。在之前的讲解中,我们已经学习了好几个可以用来防止过拟合的参数,包括复杂度控制γ ,正则化的两个参数λ和α,控制迭代速度的参数η 以及管理每次迭代前进行的随机有放回抽样的参数subsample。所有的这些参数都可以用来减轻过拟合。但除此之外,我们还有几个影响重大的,专用于剪枝的参数:参数含义 | xgb.train() | xgb.XGBRegressor() |
树的最大深度 | max_depth,默认为6 | max_depth,默认为6 |
每次生成树时随机抽样特征的比例 | colsample_bytree,默认1 | colsample_bytree,默认1 |
每次生成树的一层时随机抽样特征的比例 | colsample_bylevel,默认1 | colsample_bylevel,默认1 |
每次生成一个叶子节点时随机抽样特征的比例 | colsample_bynode,默认1 | N.A. |
i,树的最大深度是决策树中的剪枝法宝,算是最常用的剪枝参数,不过在XGBoost中,最大深度的功能与参数λ相似,因此如果先调节了λ ,则最大深度可能无法展示出巨大的效果。当然,如果先调整了最大深度,则λ也有 可能无法显示明显的效果。通常来说,这两个参数中我们只使用一个。
ii,在建立树时对特征进行抽样其实是决策树和随机森林中比较常见的一种方法,但是在XGBoost之前,这种方法并没有被使用到boosting算法当中过。Boosting算法一直以抽取样本(横向抽样)来调整模型过拟合的程度,而实践证明其实纵向抽样(抽取特征)更能够防止过拟合。
iii,通常当我们获得了一个数据集后,我们先使用网格搜索找出比较合适的n_estimators和eta组合,然后使用gamma或 者max_depth观察模型处于什么样的状态(过拟合还是欠拟合,处于方差-偏差图像的左边还是右边?),最后再决定是否要进行剪枝。通常来说,对于XGB模型,大多数时候都是需要剪枝的。
让我们先从最原始的,设定默认参数开始,先观察一下默认参数下,我们的交叉验证曲线长什么样:# encoding=utf-8import datetimeimport timeimport matplotlib.pyplot as pltimport pandas as pdimport xgboost as xgbfrom sklearn.datasets import fetch_california_housing as fchhousevalue = fch()X = pd.DataFrame(housevalue.data)y = housevalue.targetdfull = xgb.DMatrix(X, y)param1 = {'silent': True # 并非默认 , 'obj': 'reg:linear' # 并非默认 , "subsample": 1, "max_depth": 6, "eta": 0.3 , "gamma": 0 , "lambda": 1 , "alpha": 0, "colsample_bytree": 1, "colsample_bylevel": 1, "colsample_bynode": 1, "nfold": 5}num_round = 200time0 = time()cvresult1 = xgb.cv(param1, dfull, num_round)print(datetime.datetime.fromtimestamp(time() - time0).strftime("%M:%S:%f"))fig, ax = plt.subplots(1, figsize=(15, 10))# ax.set_ylim(top=5)ax.grid()ax.plot(range(1, 201), cvresult1.iloc[:, 0], c="red", label="train,original")ax.plot(range(1, 201), cvresult1.iloc[:, 2], c="orange", label="test,original")ax.legend(fontsize="xx-large")plt.show()2,在调参过程中可能会遇到这些问题:
i.一个个参数调整太麻烦,可不可以使用网格搜索呢?
当然可以!只要电脑有足够的计算资源,并且你信任网格搜索,那任何时候我们都可以使用网格搜索。只是使用的时候要注意,首先XGB的参数非常多,参数可取的范围也很广,究竟是使用np.linspace或者np.arange作为参数的备选值也会影响结果,而且网格搜索的运行速度往往不容乐观,因此建议至少先使用xgboost.cv来确认参数的范围,否则很可能花很长的时间做了无用功。并且,在使用网格搜索的时候,最好不要一次性将所有的参数都放入进行搜索,最多一次两三个。有一些互相影响的参数需要放在一起使用,比如学习率eta和树的数量n_estimators。另外,如果网格搜索的结果与你的理解相违背,与你手动调参的结果相违背,选择模型效果较好的一个。如果两者效果差不多,那选择相信手动调参的结果。网格毕竟是枚举出结果,很多时候得出的结果可能会是具体到数据的巧合,我们无法去一一解释网格搜索得出的结论为何是这样。如果你感觉都无法解释,那就不要去在意,直接选择结果较好的一个。ii. 调参的时候参数的顺序会影响调参结果吗?
会影响,因此在现实中,我们会优先调整那些对模型影响巨大的参数。在这里,我建议的剪枝上的调参顺序是: n_estimators与eta共同调节,gamma或者max_depth,采样和抽样参数(纵向抽样影响更大),最后才是正则化 的两个参数。当然,可以根据自己的需求来进行调整。iii. 调参之后测试集上的效果还没有原始设定上的效果好怎么办?
如果调参之后,交叉验证曲线确实显示测试集和训练集上的模型评估效果是更加接近的,推荐使用调参之后的效果。我们希望增强模型的泛化能力,然而泛化能力的增强并不代表着在新数据集上模型的结果一定优秀,因为未知数据集 并非一定符合全数据的分布,在一组未知数据上表现十分优秀,也不一定就能够在其他的未知数据集上表现优秀。因 此不必过于纠结在现有的测试集上是否表现优秀。当然了,在现有数据上如果能够实现训练集和测试集都非常优秀, 那模型的泛化能力自然也会是很强的。五,XGBoost模型的保存和调用
1,使用 pickle保存和调用模型
pickle是python编程中比较标准的一个保存和调用模型的库,我们可以使用pickle和open函数的连用,来将我们的模型保存到本地。以刚才我们已经调整好的参数和训练好的模型为例,我们可以这样来使用pickle:# encoding=utf-8import pickleimport pandas as pdimport xgboost as xgbfrom sklearn.datasets import fetch_california_housing as fchfrom sklearn.datasets import load_bostonfrom sklearn.metrics import mean_squared_error as MSE, r2_scorefrom sklearn.model_selection import train_test_split as TTShousevalue = fch()X = pd.DataFrame(housevalue.data)y = housevalue.targetX.columns = ["住户收入中位数", "房屋使用年代中位数", "平均房间数目" , "平均卧室数目", "街区人口", "平均入住率", "街区的纬度", "街区的经度"]X.head()Xtrain, Xtest, Ytrain, Ytest = TTS(X, y, test_size=0.3, random_state=420)dtrain = xgb.DMatrix(Xtrain, Ytrain)# 设定参数,对模型进行训练param = {'silent': True , 'obj': 'reg:linear', "subsample": 1, "eta": 0.05 , "gamma": 20, "lambda": 3.5, "alpha": 0.2, "max_depth": 4, "colsample_bytree": 0.4, "colsample_bylevel": 0.6, "colsample_bynode": 1}num_round = 180bst = xgb.train(param, dtrain, num_round)# 保存模型# 注意,open中我们往往使用w或者r作为读取的模式,但其实w与r只能用于文本文件,当我们希望导入的不是文本文件,而 是模型本身的时候,我们使用"wb"和"rb"作为读取的模式。其中wb表示以二进制写入,rb表示以二进制读入pickle.dump(bst, open("xgboostonboston.dat", "wb"))data = load_boston()X = data.datay = data.targetXtrain, Xtest, Ytrain, Ytest = TTS(X, y, test_size=0.3, random_state=420)dtest = xgb.DMatrix(Xtest, Ytest)# 导入模型loaded_model = pickle.load(open("xgboostonboston.dat", "rb"))ypreds = loaded_model.predict(dtest)MSE(Ytest, ypreds)r2_score(Ytest, ypreds)2,使用Joblib保存和调用模型
Joblib是SciPy生态系统中的一部分,它为Python提供保存和调用管道和对象的功能,处理NumPy结构的数据尤其高效,对于很大的数据集和巨大的模型非常有用。Joblib与pickle API非常相似bst = xgb.train(param, dtrain, num_round)import joblibjoblib.dump(bst,"xgboost-boston.dat")loaded_model = joblib.load("xgboost-boston.dat")ypreds = loaded_model.predict(dtest)MSE(Ytest, ypreds)r2_score(Ytest,ypreds)更多相关:
-
这是3D 点云的深度学习框架,提供常见的点云分析方法的一种通用深度学习模型。它主要依赖Pytorch Geometric和Facebook Hydra。该框架能够以最小的代价和极大的可重复性来构建精简而复杂的模型。目标是建立一个工具,用于对SOTA模型进行基准测试,同时允许研究者们有效地研究点云分析,最终目标是建立可应用于实际应用的...
-
【从零开始的ROS四轴机械臂控制(三)】五、在gazebo中添加摄像头1.修改arm1.gazebo.xacro文件2.修改arm1.urdf.xacro文件3.查看摄像头图像六、为模型添加夹爪(Gripper)1.通过solidworks建立模型2.将夹爪添加进gazebo(1)模型导入(2)更改urdf文件夹3.gazebo模型抖...
-
使用Keras训练自动驾驶(使用Udacity自动驾驶模拟器) 1.完成项目所需要的资源 (1)模拟器下载 • Linux • macOS • Windows (2)Unity 下载 运行Udacity模拟器需要Unity,这是下载链接。 https://unity.cn/releases (3)Behavioral Cl...
-
maxtree–工厂模型第74卷 大小解压后:2.34G 信息: 植物模型第74卷是高质量的三维植物模型的集合。包括12个物种,共72个单一模式。 获取地址:三维植物树木模型 Maxtree – Plant Models Vol 74-云桥网 种类 三角枫 槭树 复叶槭 鸡爪槭 白桦 Chitalpa tashkente...
-
英语的重要性,毋庸置疑!尤其对广大职场人士,掌握英语意味着就多了一项竞争的技能。那,对于我们成人来说,时间是最宝贵的。如何短时间内在英语方面有所突破,这是我们最关心的事情。英语学习,到底有没有捷径可以走,是否可以速成?周老师在这里明确告诉大家,英语学习,没有绝对的捷径走,但是可以少走弯路。十多年的教学经验告诉我们,成功的学习方法可以借...
-
展开全部 其实IDLE提供了一个显32313133353236313431303231363533e78988e69d8331333365663438示所有行和所有字符的功能。 我们打开IDLE shell或者IDLE编辑器,可以看到左下角有个Ln和Col,事实上,Ln是当前光标所在行,Col是当前光标所在列。 我们如果想得到文件代码...
-
前言[1]从 Main 方法说起[2]走进 Tomcat 内部[3]总结[4]《Java 2019 超神之路》《Dubbo 实现原理与源码解析 —— 精品合集》《Spring 实现原理与源码解析 —— 精品合集》《MyBatis 实现原理与源码解析 —— 精品合集》《Spring MVC 实现原理与源码解析 —— 精品合集》《Spri...
-
【本文摘要】【注】本文所述内容为学习Yjango《学习观》相关视频之后的总结,观点归Yjango所有,本文仅作为学习之用。阅读本节,会让你对英语这类运动类知识的学习豁然开朗,你会知道英语学习方面,我们的症结所在。学习英语这类运动类知识,需要把握四个原则第一,不要用主动意识。第二,关注于端对端第三,输入输出符合实际情况第四,通过多个例子...
-
点云PCL免费知识星球,点云论文速读。文章:RGB-D SLAM with Structural Regularities作者:Yanyan Li , Raza Yunus , Nikolas Brasch , Nassir Navab and Federico Tombari编译:点云PCL代码:https://github.co...
-
情况一:后台给的日期是Sat Jul 31 2021 21:50:01 GMT+0800 (中国标准时间),如果直接呈现给用户,他们一定会吐槽你不说人话~~~ 情况二:后台给的百分数是小数没有转化成00%格式 采用vue的过滤机制就可以解决这种情况,有两种方式: 第一种:全局写法,在main.js里面加入 // 【...
-
问题描述 使用main函数的参数,实现一个整数计算器,程序可以接受三个参数,第一个参数“-a”选项执行加法,“-s”选项执行减法,“-m”选项执行乘法,“-d”选项执行除法,后面两个参数为操作数。 例如:输入test.exe -a 1 2 执行1+2输出3 问题分析 上面的逻辑思维很简单,但是问题在于如何在VS中向...
-
------------------------siwuxie095 MyBatis 中 #{} 和 ${} 的区别 1、在 MyBatis 的映射配置文件中,动态传递参数有两种方式: (1)#{} 占位符 (2)${} 拼接符 2、#{} 和...
-
#2.6 map()# 第一个参数传入一个函数,,第二个参数为一个可迭代对象li_1 = (1,3,5,7)def funcA(x): return x*xm1 = map(funcA,li_1)print(type(m1))print(m1())# 2.6 reduce()# 第一个参数传入一个函数,第二个参数 可以迭...
-
列表,元组,字典的转换。 list列表是一组可变的元素集合 列表是'[]'括号组成的,[]括号包含所有元素,列表的创建可以传递字符串,也可以传递多个字符串来创建列表。如"asd", / "a","b" ... tuple元组的创建和列表一致,区别在于 元组是以'()'创建的,并且元组数据不可变。 dict字典不同于列表和元组,他...