关联规则挖掘算法_#数据挖掘初体验 使用weka做关联规则
这学期选了数据挖掘课,前两节课刚好都没有去上课。照着教程练习一下课程内容...
prepare
- 下载软件weka,根据系统选择版本,个人使用版本“a disk image for OS X that contains a Mac application including Oracle's Java 1.8 JVM”Data Mining with Open Source Machine Learning Software in Java
Note : mac版本安装时不是拖拽至application,而是双击weka.jar文件安装。
- 下载python,terminal自带python2和python3,个人使用python3
- 下载 mlxtend和jupyter,使用以下pip安装命令在终端中安装
pip3 install mlxtend -i https://pypi.tuna.tsinghua.edu.cn/simple #安装mxltend
pip3 install jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple #安装jupyter实验一:使用weka做关联规则
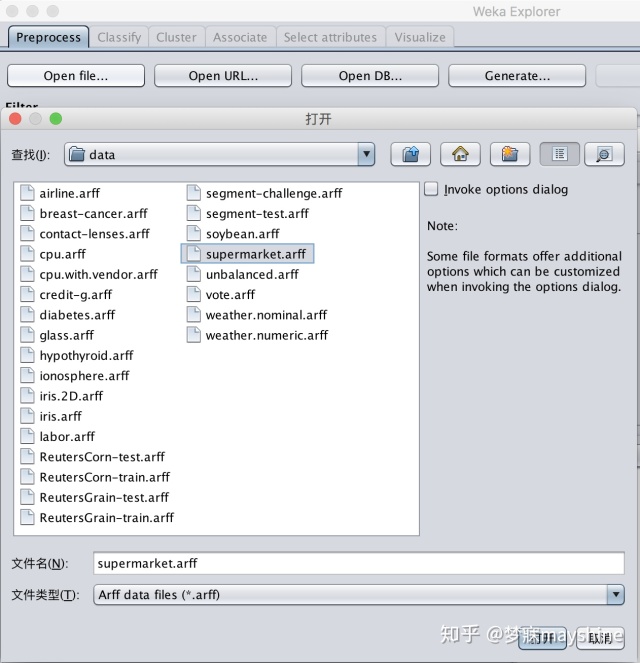
第一步:打开explorer,open file在weka所在目录的位置中在data找到supermarket数据
使用weka官方自带的数据集supermarket数据集,来自真实超市的购物数据,记录了4627条购物记录和购物记 录对应的217个属性。除total外,每个属性都是布尔类型的。't'带表True,'?'代表false。而totol字段 中,‘low’代表低于100$的消费,‘high‘代表高于100$的消费。属性中,除了商品还有商品对应的department, 若购买商品中有来自某depart ment 的商品,则该depart ment 对应属性为't ',否则为'?'。

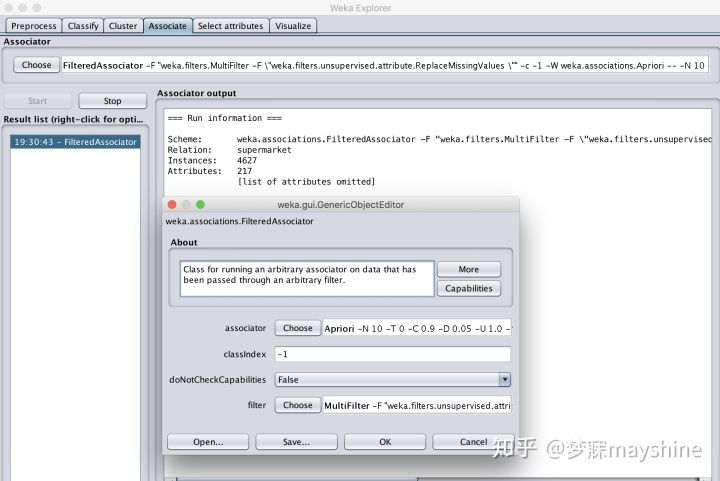
第二步:使用算法和参数过滤
在associate下选择算法和参数,点击start可以开始分析。
实验二:使用python做关联规则
使用mlxtend对api做关联规则 :Mlxtend.frequent patterns - mlxtend
主要步骤:
- 读取数据,进行预处理,将数据转为onehot 编码。
- 使用apriori挖掘频繁项集
- 使用association_rules根据指定的阈值(support ,confidence,lift ,leverage,conviction)生成满足条件的关联规则。
任务:Supermarket.arff / Weather.nominal.arff
步骤1:按total字段中low和high的值分组分别进行关联规则挖掘,注意分组后删除total字段。
df_low=df[df['total']=='low']
df_high=df[df['total']=='high'] 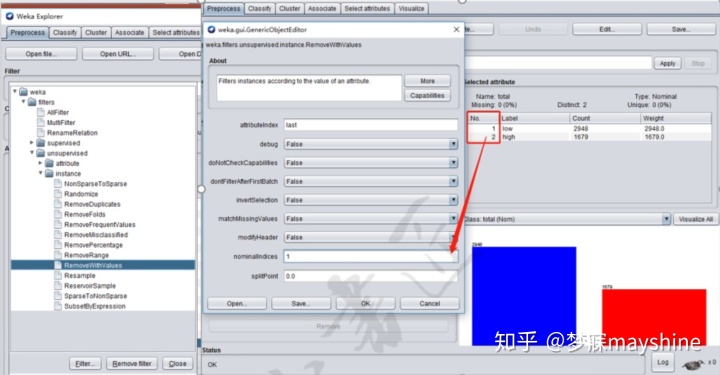
步骤2: 删除所有department 属性,使用删除depart ment 后的数据进行关联规则挖掘。
#删除department数据
departments=[x for x in df.columns if x.find('department')==0]
df_without_department=df.drop(labels=departments,axis=1)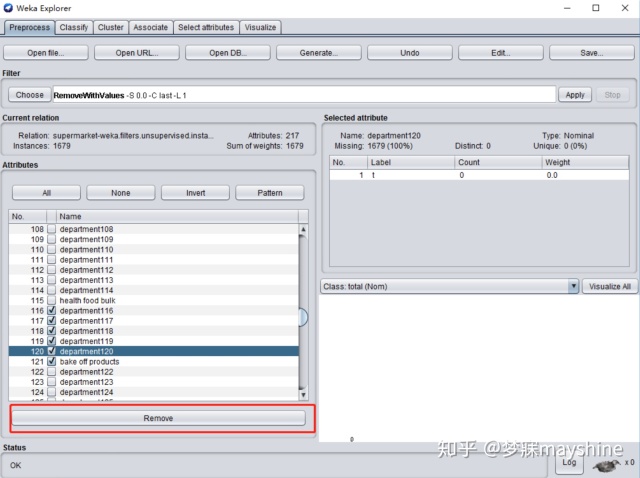
步骤三:使用weather.nominal.arff数据集挖掘关联规则,若使用weka,必须使用FPgrowth算法。
#FPGrowth要求输入01类型的nominal值矩阵。
df = pd.read_csv(path)
df = pd.get_dummies(df)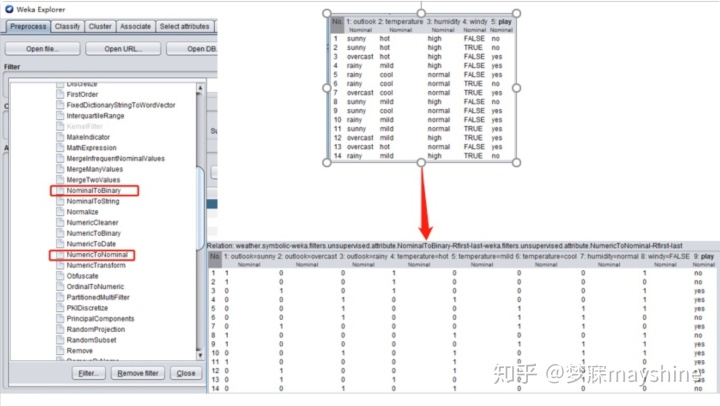
python版本:
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rulesdef encode_units(x): if x == 't':return 1 if x == '?':return 0 else:return x #获取在满足最小support条件下confidence最高的top n rules
def get_rules(df,support,confidence,n):# 获取support>=指定阈值的频繁项集frequent_itemsets = apriori(df, min_support=support, use_colnames=True) # 获取confidence>=指定阈值的的关联规则rules = association_rules(frequent_itemsets, metric="confidence",min_threshold=confidence)# 将获取的rule按照confidence升序排序 rules.sort_values(by='confidence', ascending=False) # 获取confidence前10的ruleif len(rules)>10:return rules[0:n]else:return rulesif __name__=="__main__": #对supermarket.csv数据集进行关联规则挖掘 path=r'C:UserspcDesktopsupermarket.csv' df = pd.read_csv(path)# 将数据转化成01矩阵df = df.applymap(encode_units)#删除department数据departments=[x for x in df.columns if x.find('department')==0] df_without_department=df.drop(labels=departments,axis=1) df_without_department=pd.get_dummies(df_without_department) #按照total字段low或high删除记录 df_low=df[df['total']=='low'].drop(labels='total',axis=1) df_high=df[df['total']=='high'].drop(labels='total',axis=1)#当df_high sppport取0.1时,关联规则较多,需要计算1分钟,故取0.3 print(get_rules(df=df_high,support=0.3,confidence=0.9,n=10)) print(get_rules(df=df_low, support=0.1, confidence=0.8, n=10)) print(get_rules(df=df_without_department, support=0.1, confidence=0.9, n=10))#对Weather.nominal.csv数据集进行关联规则挖掘path = r'C:UserspcDesktopweather.nominal.csv'df = pd.read_csv(path)df=pd.get_dummies(df)print(get_rules(df=df, support=0.1, confidence=0.9, n=10))总结
对比python和weka,可以发现pyhton在数据预处理方面拥有很多的便利,关于pandas和python在数据分析领域的 进一步使用,可以参考《利用Python进行数据分析》。
- mlxtend association api介绍
- pandas dataframe api介绍
- python语法

更多相关:
-
数据丢失(缺失)在现实生活中总是一个问题。 机器学习和数据挖掘等领域由于数据缺失导致的数据质量差,在模型预测的准确性上面临着严重的问题。 在这些领域,缺失值处理是使模型更加准确和有效的重点。 何时以及为什么数据丢失? 想象一下有一个产品的在线调查。很多时候,人们不会分享与他们有关的所有信息。 很少有人分享他们的经验,但不是他们使用产品...
-
nan 是not a number ,inf是无穷大 numpy.nan_to_num(x): 使用0代替数组x中的nan元素,使用有限的数字代替inf元素...
-
简介 Simple Reference 基础CUDA示例,适用于初学者, 反映了运用CUDA和CUDA runtime APIs的一些基本概念.Utilities Reference 演示如何查询设备能力和衡量GPU/CPU 带宽的实例程序。Graphics Reference 图形化示例展现的是 CUDA, OpenGL,...
-
在做开发的过程中难免需要给内核及下载的一些源码打补丁,所以我们先学习下Linux下使用如如何使用diff制作补丁以及如何使用patch打补丁。...
-
我在调研ATS 4.2.3挂载SSD的过程中,遇到很多坑,特此详细记录我摸索的主要过程,以便大家以后避免之。 基本思路可以完全照搬参考文献[2][3] 下面的安装假定是以root用户身份进行的,Linux服务器已经安装好系统,磁盘已经做好分区。 首先需要认识我们的Linux服务器的硬件配置和软件情况 硬件配置: DELL...
-
该博文整理一些在使用stl编程过程中遇到的小经验: 1.在多线程环境下面打印调试,如何使用cout及时刷新到屏幕上? 在C中我们经常这样使用: printf("Hello World "); fflush(stdout); 如果使用stl,我们可以这样使用: cout << "Hello World" << endl <...
-
本文是西门子开放式TCP通信的第2篇,上一篇我们讲了使用西门子1200PLC作为TCP服务器的程序编写,可以点击下方链接阅读:【公众号dotNet工控上位机:thinger_swj】基于Socket访问西门子PLC系列教程(一)在完成上述步骤后,接下来就是编写上位机软件与PLC之间进行通信。上位机UI界面设计如下图所示:从上图可以看出...
-
我有一个大型数据集,列出了在全国不同地区销售的竞争对手产品。我希望通过使用这些新数据帧名称中的列值的迭代过程,根据区域将该数据帧分成几个其他区域,以便我可以分别处理每个数据帧-例如根据价格对每个地区的信息进行排序,以了解每个地区的市场情况。我给出了以下数据的简化版本:Competitor Region ProductA Product...
-
作为一名IT从业者,我来回答一下这个问题。首先,对于具有Java编程基础的人来说,学习Python的初期并不会遇到太大的障碍,但是要结合自己的发展规划来制定学习规划,尤其要重视学习方向的选择。Java与Python都是比较典型的全场景编程语言,相比于Java语言来说,当前Python语言在大数据、人工智能领域的应用更为广泛一些,而且大...
-
这段时间通过学习相关的知识,最大的变化就是看待事物更加喜欢去了解事物后面的本质,碰到问题后解决问题思路也发生了改变。举个具体的例子,我在学习数据分析,将来会考虑从事这方面的工作,需要掌握的相关专业知识这个问题暂且按下不表,那哪些具体的问题是我需要了解的呢,以下简单罗列:1、了解数据分析师这个岗位在各个地区的需求情况?2、数据分析师的薪...
-
这一节将开始学习python的一个核心数据分析支持库---pandas,它是python数据分析实践与实战的必备高级工具。对于使用 Python 进行数据分析来说,pandas 几乎是无人不知,无人不晓的。今天,我们就来认识认识数据分析界鼎鼎大名的 pandas。目录一. pandas主要数据结构 SeriesDataFrame二...