逻辑回归代码_Pytorch教程(四):逻辑回归

今天我将为大家介绍逻辑回归的含义并展示Pytorch实现逻辑回归的方法,先我们来看看一个问题。
问题:
大家想必对MNIST数据集已经非常熟悉了吧?这个数据集被反复“咀嚼”,反复研究。今天我们将换个角度研究MNIST数据集。假设现在不使用卷积神经网络,又该使用什么方法来解决MNIST分类问题呢?
一、观察数据
在开始分析数据问题之前,我们需要了解最基本的数据对象。最好的方法就是访问官网去看一看数据的构成。官网地址如下:MNIST。
MNIST数据集包含四个部分:
- Training set images: train-images-idx3-ubyte.gz (包含 60,000 个样本)
- Training set labels: train-labels-idx1-ubyte.gz (包含 60,000 个标签)
- Test set images: t10k-images-idx3-ubyte.gz (包含 10,000 个样本)
- Test set labels: t10k-labels-idx1-ubyte.gz (包含 10,000 个标签)
根据官网的介绍,每张图像的大小为28*28,标签和图像的存储格式如下所示:
TRAINING SET LABEL FILE (train-labels-idx1-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000801(2049) magic number (MSB first)
0004 32 bit integer 60000 number of items
0008 unsigned byte ?? label
0009 unsigned byte ?? label
........
xxxx unsigned byte ?? label
The labels values are 0 to 9.TRAINING SET IMAGE FILE (train-images-idx3-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 60000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel
Pixels are organized row-wise. Pixel values are 0 to 255. 0 means background (white), 255 means foreground (black).可以使用以下方式读取数据集文件:
import os
import struct
import numpy as npdef load_mnist(path, kind='train'):"""Load MNIST data from `path`"""labels_path = os.path.join(path,'%s-labels-idx1-ubyte'% kind)images_path = os.path.join(path,'%s-images-idx3-ubyte'% kind)with open(labels_path, 'rb') as lbpath:magic, n = struct.unpack('>II',lbpath.read(8))labels = np.fromfile(lbpath,dtype=np.uint8)with open(images_path, 'rb') as imgpath:magic, num, rows, cols = struct.unpack('>IIII',imgpath.read(16))images = np.fromfile(imgpath,dtype=np.uint8).reshape(len(labels), 784)return images, labels图像数据的形式如下所示,具体情况请参考详解 MNIST 数据集一文对MNIST数据集的介绍。
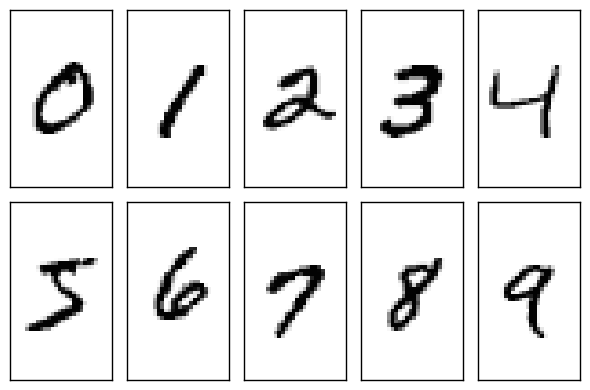
借助上面的代码,我们可以获得对数据的一个直观感受。在分析数据集时往往还需要关注一些细节问题,例如数据是否存在类别不平衡问题、数据的噪声情况、数据是否做过归一化处理等等。MNIST相对比较简单,对于上述数据问题,后面的课程中我们会结合更加复杂的数据集再做探讨。
二、分析问题
上一节课程中,我们讨论了线性回归问题,而这次的课程需要解决的是一个分类问题。在自己动脑筋想办法之前,我们先找到一个巨人,站在他的肩膀上看一看,弄清楚针对这一问题已有的办法是什么样的。一般情况下,每个开放的数据集都会给出基于此数据集的各项任务排名。下面这张表摘录了部分应用于MNIST数据集的方法,这些方法被分为如下7类:
- Linear Classifiers
- K-Nearest Neighbors
- Boosted Stumps
- Non-Linear Classifiers
- SVMs
- Neural Nets
- Convolutional nets
这些方法并不是凭空出现或者一拍脑门就想出来的,分析研究其设计思路是一件非常有意思的事情。还记得我们在课程开始提出的问题吗?“假设现在不使用卷积神经网络,该使用什么方法来解决MNIST分类问题”。前人的工作已经给出了回答。
我们今天探讨的内容是“逻辑回归”。逻辑回归可以视作用回归的方法处理分类问题。结合我们上一节课程介绍的内容,回归问题可以用线性函数加以拟合。同样的逻辑回归问题也可以使用线性函数来处理。所以说用逻辑回归处理MNIST分类问题,可以理解为使用“Linear Classifiers”来处理该问题。但是回归问题里可以用“距离”这种概念来作为优化目标。分类问题里又该选择哪一种优化目标呢?下面我用尽可能简单的语言来介绍人们设计分类问题优化目标的思路。
思路一:使用分类误差作为优化目标
我们先来看看两张表格,这两张表格分别是两个线性模型进行分类预测的结果。
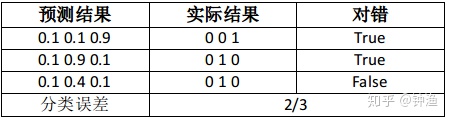
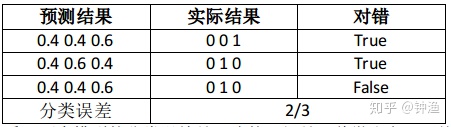
从分类结果来看,两个模型的分类误差是一致的。但是,稍微注意一下就会发现,模型一的性能优于模型二。但是分类误差显然不能区分出这一点。所以说,使用分类误差作为优化目标可能是不精确的。
思路二:使用均方误差作为优化目标
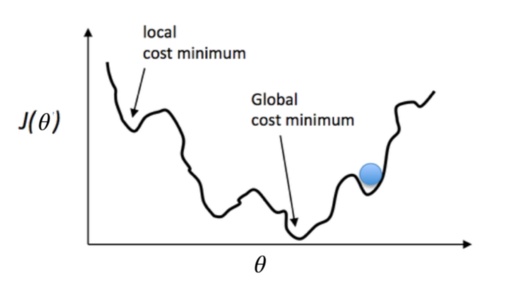
使用均方误差(MSE)来处理分类问题倒也不是不行,但是请朋友们注意一个问题。我们是在做分类问题,输出的结果是一个类别,类别是离散值,我们需要计算每个类别出现的概率并挑选概率最大的类别作为输出。在计算各个类别概率的时候,需要使用softmax函数。但是使用了softmax函数后,MSE的函数形状是非凸的,换句话说就是有许多局部的极值点。这样很难通过反向传播来进行优化。就像下图的小球滚到“山腰”就没法往下滚了。
思路三:使用交叉熵函数作为优化目标
交叉熵函数非常有意思,大家可以看看这篇文章熵与信息增益。今天主要逻辑回归的内容,熵与信息增益的内容会放到生成对抗网络部分进行介绍。这里我们直接看交叉熵函数的公式:
其中
那么根据公式,模型一中第一项的交叉熵误差的值是:
以此类推,模型一的平均交叉熵误差是:
模型二的平均交叉熵误差是:
所以在分类任务中,交叉熵函数可以比较好的度量不同分布之间的差别。
三、实验
这部分的代码比较简单,所以我就把代码放上来了,方便大家复制粘贴,完整代码请参见pytorch-tutorial。本节课程的代码非常类似于上一节课程介绍的线性回归代码,主要的差别在于本节课程采用了CrossEntropyLoss这一损失函数。
完整代码如下:
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms# Hyper-parameters
input_size = 784
num_classes = 10
num_epochs = 5
batch_size = 100
learning_rate = 0.001# MNIST dataset (images and labels)
train_dataset = torchvision.datasets.MNIST(root='../../data', train=True, transform=transforms.ToTensor(),download=True)test_dataset = torchvision.datasets.MNIST(root='../../data', train=False, transform=transforms.ToTensor())# Data loader (input pipeline)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)# Logistic regression model
model = nn.Linear(input_size, num_classes)# Loss and optimizer
# nn.CrossEntropyLoss() computes softmax internally
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) # Train the model
total_step = len(train_loader)
for epoch in range(num_epochs):for i, (images, labels) in enumerate(train_loader):# Reshape images to (batch_size, input_size)images = images.reshape(-1, 28*28)# Forward passoutputs = model(images)loss = criterion(outputs, labels)# Backward and optimizeoptimizer.zero_grad()loss.backward()optimizer.step()if (i+1) % 100 == 0:print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, total_step, loss.item()))# Test the model
# In test phase, we don't need to compute gradients (for memory efficiency)
with torch.no_grad():correct = 0total = 0for images, labels in test_loader:images = images.reshape(-1, 28*28)outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum()print('Accuracy of the model on the 10000 test images: {} %'.format(100 * correct / total))# Save the model checkpoint
torch.save(model.state_dict(), 'model.ckpt')运行结果如下:
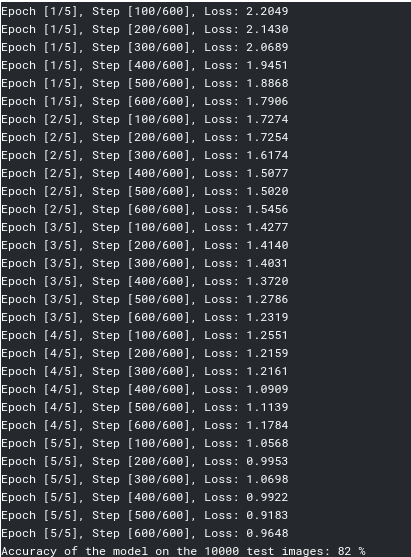
四、小结与反思
不知道各位读者看完上述程序后有没有一丝丝疑惑,这个单层的网络到底学习到了什么东西?凭什么建立一个784到10的映射就能完成手写字体识别任务?
换个角度考虑一下,我们来想想784×10个映射关系中的一个具体的映射关系究竟学习到了什么东西?这个问题比较好回答,线性映射能学到的无非就是一个线性函数。这个线性函数能完成的任务也就是判断与这个线性函数对应的像素块对全局信息的贡献度。
那么多个线性映射是否就能完整的表达图像的全局信息呢?答案是:不一定。原因很简单,不同像素位置的点的贡献度应当是不同的,不同位置的像素之间存在一定的关联,这种联系在描述语义信息时是非常重要的。显然单层线性模型无法完成这项任务。我们将针对这一问题在后续课程中继续研究更加合适的处理方法。
更多相关:
-
这是学习笔记的第 2103 篇文章 最近碰到了一个奇怪的权限问题,问题的背景是业务同学反馈在下班后,有一个数据表出现了阻塞,导致后续的业务流程都产生了拥堵,在对这个问题进行分析发现,业务同学所谓的拥堵,阻塞是数据库连接出了问题。当然我们进行了一些深入的沟通,对整个问题的情况有了一个更为清晰的了解。 6:30左右,业务同学发现...
-
写在前面 最近公众号的活动让更多的人加入交流群,尝试提问更多的我问题,群主也在积极的招募更多的小伙伴与我一起分享,能够相互促进。 这里总结群友经常问,经常提的两个问题,并给出我的回答: (1)啥时候能出教程,能够讲解PCL中的各种功能? (2)如何解决大规模点云的问题呢? 以下给出正式的解答以及计划安排 问题1:对于...
-
我刚刚开始接触PCL,懂的东西也很少,所以总是出现各种各样的问题,每次遇见问题的时候要查找各种各样的资料,很费时间。所以,今天我把我遇见的常见问题分享给大家,讲解的步骤尽量详细,让和我一样基础差的小伙伴能尽快进入到PCL点云库的学习中,希望能和大家进步。 运行环境:PCL-1.8.0-AllInOne-msvc2013-win...
-
这篇博文中主要收集我开发过程中遇到的Makefile相关的问题, 以免自己日后再犯类似的错误. 今天就遇到一个很弱的问题, Makefile显示如下错误: 出现该问题是因为我写错了标注处的代码: $和()之间有空格了, 这里必须是$(), 不能有空格的...
-
本文是西门子开放式TCP通信的第2篇,上一篇我们讲了使用西门子1200PLC作为TCP服务器的程序编写,可以点击下方链接阅读:【公众号dotNet工控上位机:thinger_swj】基于Socket访问西门子PLC系列教程(一)在完成上述步骤后,接下来就是编写上位机软件与PLC之间进行通信。上位机UI界面设计如下图所示:从上图可以看出...
-
我有一个大型数据集,列出了在全国不同地区销售的竞争对手产品。我希望通过使用这些新数据帧名称中的列值的迭代过程,根据区域将该数据帧分成几个其他区域,以便我可以分别处理每个数据帧-例如根据价格对每个地区的信息进行排序,以了解每个地区的市场情况。我给出了以下数据的简化版本:Competitor Region ProductA Product...
-
作为一名IT从业者,我来回答一下这个问题。首先,对于具有Java编程基础的人来说,学习Python的初期并不会遇到太大的障碍,但是要结合自己的发展规划来制定学习规划,尤其要重视学习方向的选择。Java与Python都是比较典型的全场景编程语言,相比于Java语言来说,当前Python语言在大数据、人工智能领域的应用更为广泛一些,而且大...
-
这段时间通过学习相关的知识,最大的变化就是看待事物更加喜欢去了解事物后面的本质,碰到问题后解决问题思路也发生了改变。举个具体的例子,我在学习数据分析,将来会考虑从事这方面的工作,需要掌握的相关专业知识这个问题暂且按下不表,那哪些具体的问题是我需要了解的呢,以下简单罗列:1、了解数据分析师这个岗位在各个地区的需求情况?2、数据分析师的薪...
-
这一节将开始学习python的一个核心数据分析支持库---pandas,它是python数据分析实践与实战的必备高级工具。对于使用 Python 进行数据分析来说,pandas 几乎是无人不知,无人不晓的。今天,我们就来认识认识数据分析界鼎鼎大名的 pandas。目录一. pandas主要数据结构 SeriesDataFrame二...