CUDA学习3-GridBlock
掌握如何组织线程是CUDA编程的重要部分。CUDA线程分成Grid和Block两个层次。
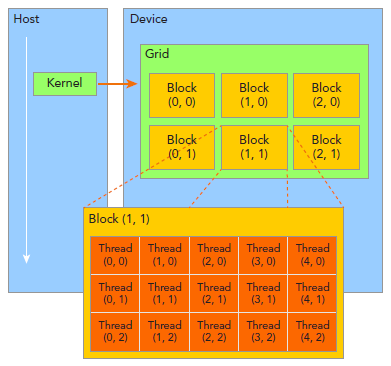
由一个单独的kernel启动的所有线程组成一个grid,grid中所有线程共享global memory。一个grid由许多block组成,block由许多线程组成,grid和block都可以是一维二维或者三维,上图是一个二维grid和二维block。
这里介绍几个CUDA内置变量:
blockIdx:block的索引,blockIdx.x表示block的x坐标。
threadIdx:线程索引,同理blockIdx。
blockDim:block维度,上图中blockDim.x=5.
gridDim:grid维度,同理blockDim。
一般会把grid组织成2D,block为3D。grid和block都使用dim3作为声明,例如:
dim3 block(3);
dim3 grid((nElem+block.x-1)/block.x);
需要注意的是,dim3仅为host端可见,其对应的device端类型为uint3。
启动CUDA kernel
CUDA kernel的调用格式为:
kernel_name<<
其中grid和block即为上文中介绍的类型为dim3的变量。通过这两个变量可以配置一个kernel的线程总和,以及线程的组织形式。例如:
kernel_name<<<4, 8>>>(argumentt list);
该行代码表明有grid为一维,有4个block,block为一维,每个block有8个线程,故此共有4*8=32个线程。

一些基本的描述:
gridDim.x-线程网络X维度上线程块的数量
gridDim.y-线程网络Y维度上线程块的数量
blockDim.x-一个线程块X维度上的线程数量
blockDim.y-一个线程块Y维度上的线程数量
blockIdx.x-线程网络X维度上的线程块索引
blockIdx.y-线程网络Y维度上的线程块索引
threadIdx.x-线程块X维度上的线程索引
threadIdx.y-线程块Y维度上的线程索引
线程索引
一般,一个矩阵以线性存储在global memory中的,并以行来实现线性:

在kernel里,线程的唯一索引非常有用,为了确定一个线程的索引,我们以2D为例:
- 线程和block索引
- 矩阵中元素坐标
- 线性global memory 的偏移
首先可以将thread和block索引映射到矩阵坐标:
ix = threadIdx.x + blockIdx.x * blockDim.x
iy = threadIdx.y + blockIdx.y * blockDim.y
之后可以利用上述变量计算线性地址:
idx = iy * nx + ix
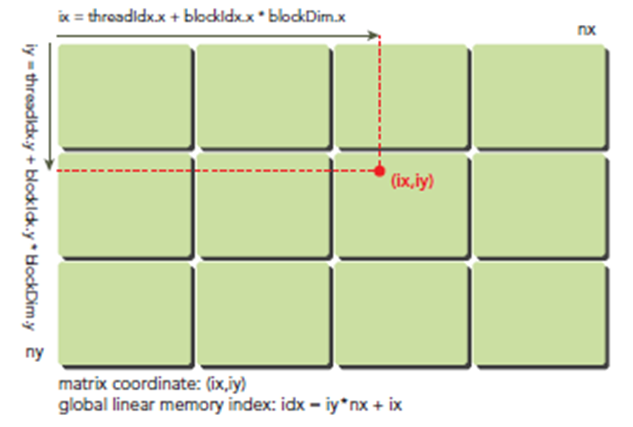
上图展示了block和thread索引,矩阵坐标以及线性地址之间的关系,谨记,相邻的thread拥有连续的threadIdx.x,也就是索引为(0,0)(1,0)(2,0)(3,0)...的thread连续,而不是(0,0)(0,1)(0,2)(0,3)...连续,跟我们线代里玩矩阵的时候不一样。
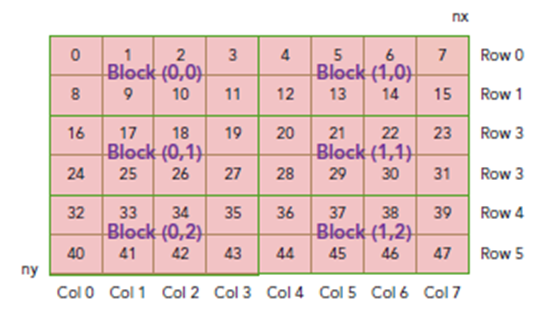
现在可以验证出下面的关系:
thread_id(2,1)block_id(1,0) coordinate(6,1) global index 14 ival 14
下图显示了三者之间的关系:
线程块分配要求:
CUDA设备上面的SM的数量;dev_prop.multiProcessorCount
每个SM上面SP(流处理器)的数量,真正执行指令的部件;
一个SM(多核流处理器)上最多可以分配的线程数量;
一个SM上分配线程块的上线;
一个线程块中的最大线程数量;dev_prop.maxthreadsPerBlock
每个维度允许分配的最大线程数量;x:dev_prop.maxthreadsDim[0] 、y:dev_prop.maxthreadsDim[1]
每个维度允许分配的最大线程块数量;x:dev_prop.maxGridSize[0] 、y:dev_prop. maxGridSize[1]
Warp单元:SM中的线程调度单元,用来隐藏其它类型的操作延迟,由32个线程组成。
当一个网格启动时,网格中的线程块以任意顺序分配到SM上,因此不同线程块上的线程不能同步.
Warp调度
逻辑上,所有thread是并行的,但是,从硬件的角度来说,实际上并不是所有的thread能够在同一时刻执行,接下来我们将解释有关warp的一些本质。
同一个warp中的thread可以以任意顺序执行,active warps被SM资源限制。当一个warp空闲时,SM就可以调度驻留在该SM中另一个可用warp。在并发的warp之间切换是没什么消耗的,因为硬件资源早就被分配到所有thread和block,所以该新调度的warp的状态已经存储在SM中了。
SM可以看做GPU的心脏,寄存器和共享内存是SM的稀缺资源。CUDA将这些资源分配给所有驻留在SM中的thread。因此,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力。所以,掌握部分硬件知识,有助于CUDA性能提升。
warp是SM的基本执行单元。一个warp包含32个并行thread,这32个thread执行于SMIT模式。也就是说所有thread执行同一条指令,并且每个thread会使用各自的data执行该指令。
block可以是一维二维或者三维的,但是,从硬件角度看,所有的thread都被组织成一维,每个thread都有个唯一的ID。
每个block的warp数量可以由下面的公式计算获得:
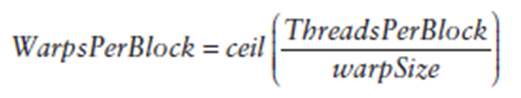
一个warp中的线程必然在同一个block中,如果block所含线程数目不是warp大小的整数倍,那么多出的那些thread所在的warp中,会剩余一些inactive的thread,也就是说,即使凑不够warp整数倍的thread,硬件也会为warp凑足,只不过那些thread是inactive状态,需要注意的是,即使这部分thread是inactive的,也会消耗SM资源。
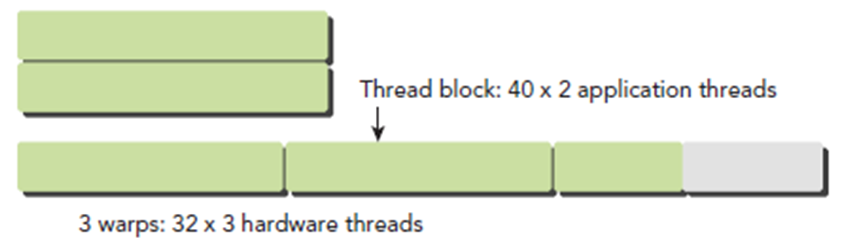
每一个块上面最多可以有1024个线程。
每一个SM(多核流处理器)上面最多有1636个线程。
SM中的线程调度单元又将分配到的块进行细分,将其中的线程组织成更小的结构,称为线程束(warp)。所以由32个线程组成的Warp是CUDA程序执行的最小单位,并且同一个warp是严格串行的。warp的设计被用于隐藏延迟操作。尽可能充分利用每个线程块的线程容量能得到足够多的warp隐藏长延迟操作。
更多相关:
-
多线程有什么好处?提高CPU的利用率,更好地利用系统资源,使用Monitor类可以同步静态/实例化的方法的全部代码或者部分代码段,使用不同的同步类创建自己的同步机制。多线程指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个线程提升整体处理性能。多线程是指程序中包含多个执行流,即...
-
Step1:在界面主函数的构造函数中初始化多线程 auto mythread = new QThread(); //新建connect(mythread , &QThread::finished, mythread, &QObject::deleteLater);//线程运行结束后释放内存object1->moveToThread...
-
一、thread的基本用法 参见C++使用thread类多线程编程 。 二、类外使用多线程,访问类的成员 这几种方式,新建线程都是在类外,然后通过把友元函数或者成员函数作为thread参数。 #include
#include #include using namesp... -
本博文是根据中科大信息学院谭立湘老师的课件加上自己的理解整理出来的 ************************************************************************************ NVIDIA在2007年推出CUDA这个统一计算架构 CUDA的基本思想是支持大量的线程级并...
-
一、parallel communication patterns 并行通信模式 Map:映射,在特定的位置读取和写入。 Gather:收集,从多个不同的位置读入,写入一个位置。 Scatter:分发,写入多个位置。 Transpose转置 结构数组缩写为AOS,数组结构缩写为SOA 转置运算是指任务重新排序内存中的数...
-
1.分类Category的使用// 给MJPerson类添加分类 @interface MJPerson : NSObject - (void)run; @end@implementation MJPerson - (void)abc{} - (void)run{NSLog(@"MJPerson - run");} + (void)...
-
首先概括一下这几个概念。其中SM(Streaming Multiprocessor)和SP(streaming Processor)是硬件层次的,其中一个SM可以包含多个SP。thread是一个线程,多个thread组成一个线程块block,多个block又组成一个线程网格grid。 现在就说一下一个kenerl函数是怎么执行的。一...
-
下面的程序输出什么?思考一下 #include
// Driver Code int main() {{int x = 10, y = 20;{// The outer block contains// declaration of x and// y, so following statement// is va... -
原文:https://blog.csdn.net/ygtlovezf/article/details/80528300 blktrace对于分析block I/O是个非常好的工具,本篇文章记录了如何使用blktrace。 blktrace原理 blktrace是对通用块层(block layer)的I/O跟踪机制,它能抓取详细的...